„Wo stand das noch mal?“ Wer als Mitarbeitender nach internen Dokumenten sucht, stellt sich diese Frage häufiger. Jeden Tag werden in Unternehmen große Mengen an Daten produziert, darunter Verträge, Protokolle, interne Regelungen, Vorträge, Wiki-Seiten und viele mehr. Diese werden oft an unterschiedlichen Stellen hinterlegt und sind nur mit entsprechendem Such-Aufwand wiederzufinden. Selbst wenn das gesuchte Dokument vorliegt, kann es eine Herausforderung sein, den beschriebenen Inhalt schnell zu erfassen.
Suchen benötigen Zeit und können schnell zu Frustration führen.
Mithilfe von LLMs (Large Language Models) ist es möglich, Suchen auf ein neues Level zu heben. LLMs fallen in den Bereich der Generative Artificial Intelligence (GenAI) und konzentrieren sich dabei speziell auf die Verarbeitung von Sprache und Text. Die Sprachmodelle bieten einen innovativen Ansatz, um das interne Wissensmanagement in Unternehmen zu optimieren.
Wir wollen in diesem Artikel insbesondere auf Retrieval Augmented Generation (RAG) eingehen. RAG ist eine immer beliebter werdende Methode, bei der LLMs mit unternehmensinternem Wissen versorgt werden und zu treffsicheren Ergebnissen führen. Im Folgenden sprechen über die Vor- und Nachteile von RAG und stellen sie einer alternativen Methode, dem Finetuning, gegenüber.
Inhalt
- Finetuning - aufwendiger Standard?
- Was ist RAG und wie funktioniert es?
- RAG vs. Finetuning
- Zusammenfassung
Finetuning – aufwendiger Standard?
Starten wir zunächst mit der bekannteren Methode: Beim Finetuning werden bestehende Modelle für spezielle Use-Cases angepasst und mit domänenspezifischem Wissen versorgt. Das Modell wird anhand von speziell präparierten Daten neu trainiert und erlernt vorhandene Muster und Informationen. Der Nutzer kann dann Anfragen an das "Finetuned-LLM" senden und Antworten erhalten, die mit Wissen aus dem domänenspezifischen Datensatz generiert wurden.
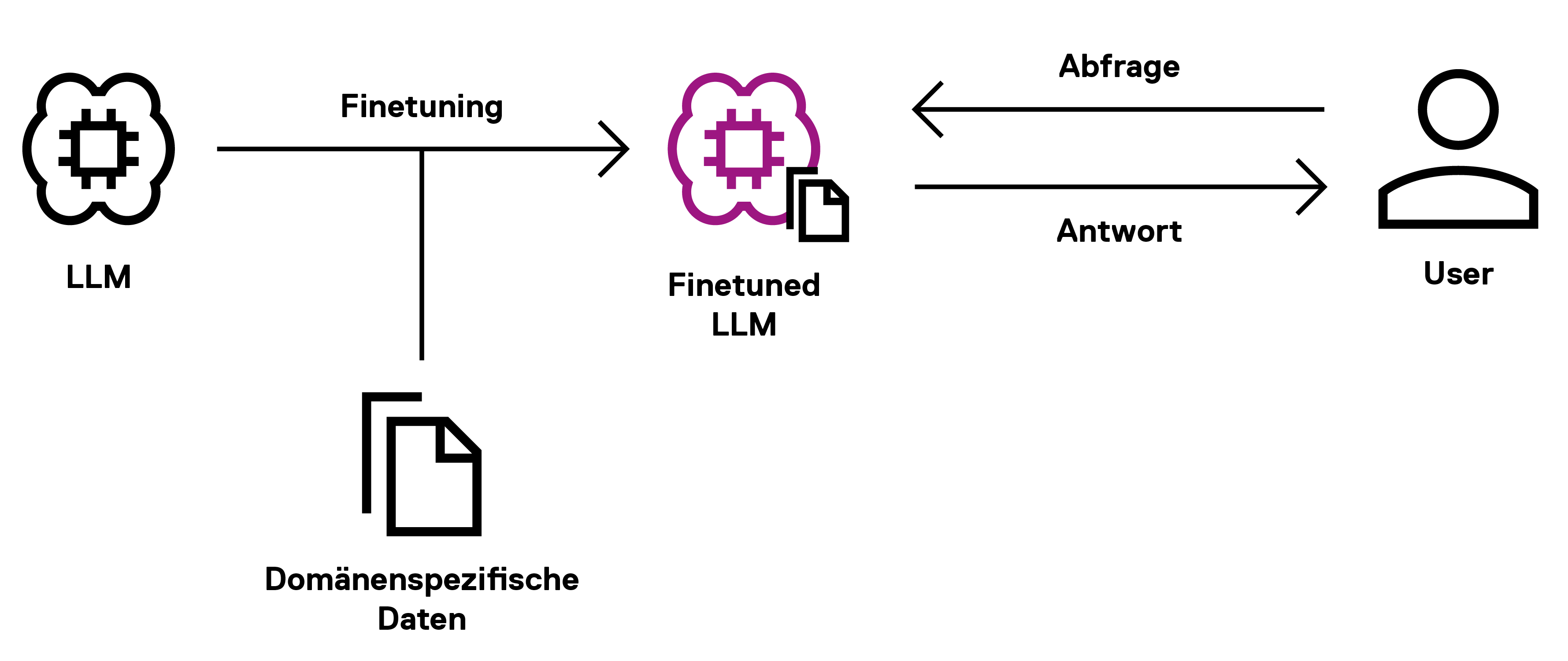
Abbildung 1: Finetuning
Finetuning war bisher die Standardmethode, ein LLM so zu trainieren, dass es z.B. auf unternehmensspezifische Fragen eingehen kann. Allerdings birgt die Methode so manche, unangenehme Tücken. Es kann nämlich in einem unangemessen hohen Kosten-, Zeit- und Ressourcenaufwand münden. Das liegt vor allem an der Datenbereitstellung für das Training, da zusätzliche Daten aggregiert, bereinigt und gelabelt werden müssen. Erst dann kann ein weiterführendes Training erfolgen, welches abermals Ressourcen verschlingt.
Beim Finetuning kann das Modell lediglich auf das Wissen zugreifen, welches zur Trainingszeit vorhanden war. Aktuellere Daten können bei diesem Ansatz ohne erneutes Training des Modells nicht berücksichtigt werden. Ein weiterer Nachteil entsteht bei einem Mangel an guten Trainingsdaten: Zwar erlernt es anhand der Daten Muster und kann daraus Informationen ziehen, jedoch wendet es diese stochastisch an – was zu unpräzisen Ergebnissen führen kann.
Eine Alternative mit einer verlässlicheren Funktionsweise wird benötigt, und das führt uns zum Ansatz von RAG.
Was ist RAG und wie funktioniert es?
Bei Retrieval Augmented Generation (RAG) werden LLMs mit Informationen aus externen Wissensdatenbanken versorgt. Der Unterschied zum Finetuning ist, dass das zugrunde liegende LLM nicht noch einmal neu trainiert wird. RAG greift bei der Erstellung einer Antwort auf vorhandenes Wissen in Form von Dokumenten zu und fügt dieses Wissen dem bestehenden Kontext hinzu. So können präzise, aktuelle und kontextrelevante Texte generiert werden.
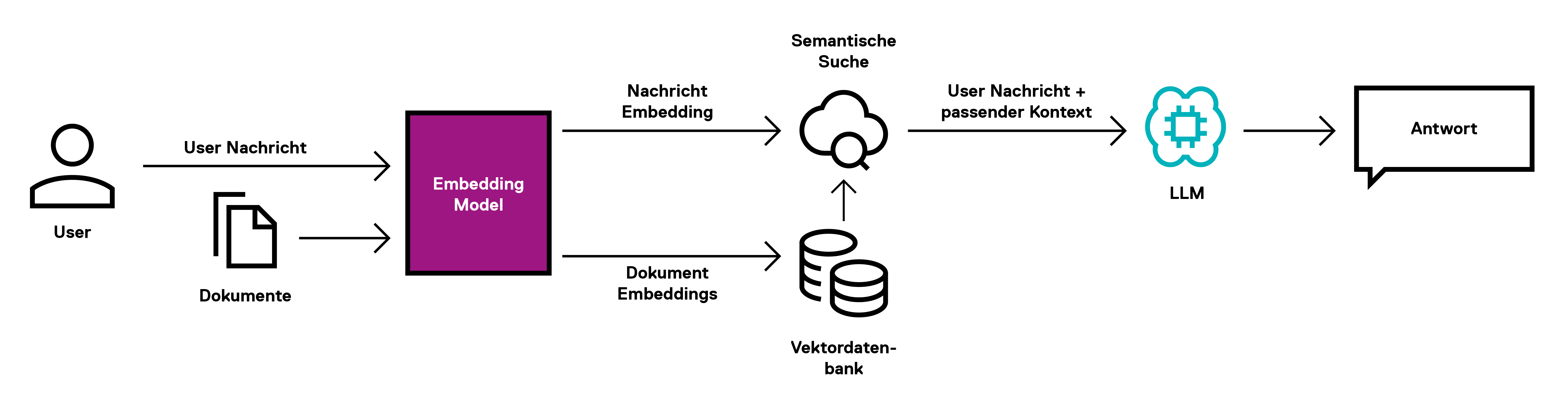
Abbildung 2: Retrieval Augmented Generation (RAG)
Um besser zu verstehen, wie RAG funktioniert, schauen wir uns die Methode anhand einer typischen Frage an:
"Wie mache ich eine Reisekostenabrechnung?"
Zwei wesentliche Schritte finden bei RAG statt:
- Die semantische Suche passender Dokumente auf eine Anfrage an das LLM
- Die Generierung einer Antwort
Sowohl Anfrage als auch Antwort geschehen in natürlicher Sprache.
Schritt 1: Semantische Suche
Das grundlegende Werkzeug von RAG und insbesondere der semantischen Suche ist eine sogenannte Vektordatenbank. Eine Vektordatenbank ist darauf spezialisiert, Vektoreinbettungen von Worten, Sätzen und Dokumenten in natürlicher Sprache (auch als Embeddings bezeichnet) zu indexieren und effizient abzufragen. Embeddings sind nichts weiter als die Repräsentation natürlicher Sprache in Vektoren, welche arithmetisch miteinander verrechnet werden können. Diese Vektoren werden von vortrainierten Embedding-Modellen erstellt und können die semantische Bedeutung von Sprache in Zahlenform festhalten. Das hat den Vorteil, dass man so Texte miteinander vergleichen und herausfinden kann, welche Texte sich semantisch ähnlich sind.
Um die Funktion besser verstehen können, schauen wir uns die Frage zur Reisekostenabrechnung an. Die Voraussetzungen einer semantischen Suche sind, dass zum einen Dokumente mit dem relevanten Wissen über den Sachverhalt existieren, und zum anderen in vektorisierter Form in einer Datenbank vorliegen und abgerufen werden können. Bei der semantischen Suche wird nun die Suchanfrage von natürlicher Sprache in Vektoren umgewandelt, und die für die Anfrage relevanten Dokumente aus der Vektordatenbank herausgesucht. Dies ist z.B. der Fall, wenn sich die Inhalte zwischen der Nutzer-Anfrage und dem gesuchten Dokument ähneln - in unserem Beispiel also, wenn es in beiden inhaltlich um Reisekosten geht. Dank der Embeddings lässt sich diese Ähnlichkeit mathematisch berechnen und deren Abfrage automatisieren.
Schritt 2: Generierung der Antwort
Nachdem mithilfe der semantischen Suche ein oder mehrere relevante Dokumente zur Nutzer-Anfrage gefunden wurden, werden diese als Kontext an die Anfrage angehängt. Nun kann das LLM aus der Nutzer-Anfrage und dem Kontext eine Antwort generieren, welche auf dem Wissen des firmeninternen Wikis basiert. Das LLM hat also zur Frage „Wie mache ich eigentlich eine Reisekostenabrechnung?“ alle relevanten Informationen zur Reisekostenabrechnung zur Verfügung, und kann diese ggf. paraphrasieren und auf die entsprechenden Dokumente verweisen.
RAG vs. Finetuning
Der Vorteil von RAG liegt v.a. in der Leichtgewichtigkeit gegenüber dem Finetuning.
- Das LLM muss nicht trainiert werden, sondern kann in seiner Ursprungsform verwendet werden. Man bedient sich lediglich seiner Fähigkeit, natürliche Sprache zu verarbeiten. Dies erspart bereits eine Menge Zeit und Kosten, welche sonst auf eine Feinabstimmung des LLM aufzuwenden wären.
- Ein RAG-System lässt sich wesentlich einfacher auf dem neuesten Wissensstand halten. Anstatt ein LLM mit dem neuen Wissen trainieren zu müssen, braucht man lediglich das neue Wissen in die Vektordank einzubringen. Das RAG-System wird dann automatisch bei der nächsten Nutzer-Anfrage auf die aktuellen Informationen zugreifen.
Ein wesentlicher Nachteil des RAG gegenüber finegetunten LLMs ist allerdings die Größe des Kontexts, welche an das LLM übergeben wird. Bei jeder Anfrage muss das relevante Wissen aus der Vektordatenbank angehängt werden. Je nach Dokumentengröße kann der Kontext so auf beträchtliche Größe wachsen. Dies ist insbesondere dann von Bedeutung, wenn man ein LLM über die API eines Drittanbieters anspricht. Die Verrechnung erfolgt in der Regel nach dem „Pay-Per-Use“-Prinzip, und ist proportional zur Tokenlänge, also der Anzahl übermittelter Textfragmente.
Zusammenfassung
RAG bietet im Vergleich zum Model-Finetuning eine leichtgewichtige Lösung, mit der effizient und kostengünstig ein LLM mit aktuellem, domänenspezifischem Wissen erweitert werden kann. RAG kann ohne ein erneutes Training des LLM mit neuen Informationen aktualisiert werden und ist daher ressourcenschonender. Im Vergleich zum Model-Finetuning ist allerdings zu beachten, dass bedingt durch die Funktionsweise von RAG die Anzahl der Tokens pro Anfrage vergleichsweise hoch ist. Schließlich muss das relevante Wissen immer an die Nutzer-Anfrage zusätzlich angehängt wird. Dies kann bei häufiger und langfristiger Nutzung mit großen Kontexten zu beträchtlichen Mehrkosten je Anfrage führen.
RAG ist die Methode der Wahl, wenn es darum geht, faktenbasierte Antworten zu generieren. RAG benötigt nicht nur weniger Ressourcen, sondern liefert auch zuverlässigere Ergebnisse als ein Fine-Tuned LLM. Finetuning sollte nur dann in Betracht gezogen werden, wenn das Verhalten des LLM an spezifische Anforderungen angepasst werden muss: z.B. wenn das Antwortverhalten abgestimmt und/oder spezielle Sprachcodes verwendet werden sollen.
Haben Sie Fragen oder benötigen Sie Unterstützung?
Mehr zu den Möglichkeiten von Generativer KI für Ihr Unternehmen finden Sie auf unserer Webseite.

Weitere Artikel










- Juni 2026
- April 2026
- Februar 2026
- Januar 2026
- Dezember 2025
- November 2025
- Oktober 2025
- August 2025
- Juli 2025
- Juni 2025
- Mai 2025
- April 2025
- März 2025
- Februar 2025
- Januar 2025
- Oktober 2024
- September 2024
- August 2024
- Juli 2024
- Juni 2024
- Mai 2024
- April 2024
- März 2024
- Februar 2024
- Januar 2024
- Dezember 2023
- November 2023
- September 2023
- August 2023
- Juli 2023
- Juni 2023
- Mai 2023
- April 2023
- Februar 2023
- Dezember 2022
- November 2022
- Mai 2022
- April 2022
- März 2022
- Januar 2022
- Dezember 2021
- November 2021
- Oktober 2021
- August 2021
- Juli 2021
- Juni 2021
- Mai 2021
- April 2021
- Dezember 2020
- Oktober 2020
- September 2020
iteratec
iteratec ist der Partner für alle, die zu den Gewinner:innen der digitalen Transformation gehören wollen. Mit individuellen, überlegenen Lösungen eröffnen wir unseren Kunden technologische wie unternehmerische Potenziale. Denn: Wenn Scheitern keine Option ist, sind wir der Partner, der den Unterschied macht. So haben wir seit 1996 mehr als 1.000 Projekte zum Erfolg geführt und eine Kundenzufriedenheit von 97%.