
Ohne große Datenmengen funktionieren Artificial Intelligence (AI) oder Machine Learning (ML) nicht. AI/ML-Modelle zu trainieren heißt, mit verschiedenen Methoden und Daten zu experimentieren und diese miteinander und gegeneinander zu verproben. Die Daten unterliegen aber oft unterschiedlichen Geheimhaltungsstufen oder können erst nach langwierigen Abstimmungen für den Lernprozess verwendet werden. Die Notwendigkeit der Datennutzung muss zumeist detailliert begründet werden.
Mit Daten experimentieren zu können, die Nutzung aber vorher detailliert begründen zu müssen, steht im Widerspruch zueinander. Wie können wir diesen auflösen?
Nachfolgend beschreiben wir die Möglichkeiten und Grenzen des maschinellen Lernens in einem Protected Environment. Wir erläutern anhand des Praxisbeispiels „Zuordnung von E-Mails zu Abteilungen", wie wir mit sensiblen Daten experimentieren – ohne die Daten selbst einsehen zu können. Außerdem zeigen wir den Aufbau des Protected Environments, erklären, wie die Experimente darin stattfinden und was wir daraus gelernt haben.
Inhalt
- Das Projekt Mail2Abteilung
- Das Protected Environment
- Die Learning-Pipeline
- Feature-Generator
- Trainingsmethoden
- Einsatz des Systems
- Erfahrungen
- Schlussbemerkungen
Unser ML-Projekt „Mail2Abteilung“ wäre beinahe am Datenschutz gescheitert.
Kennen Sie das Thema? Ich habe vor Kurzem an unser Projekt-Management-Office eine E-Mail geschickt, weil ich die Freigabe für ein Laufwerk brauchte. Die Antwort war: „Das liegt seit einiger Zeit nicht mehr bei uns, sondern bei den Administratoren“. Je nach Organisationsgröße kann die Suche nach dem zuständigen Bereich relativ lange dauern.
Was können wir hier tun? In einem Projekt wollen wir aus dem Mailinhalt den richtigen Empfänger ermitteln und vorschlagen. Als Ansatz wählen wir das Training eines ML-Modells. Dafür sind viele Trainingsdaten notwendig.
Woher bekommen wir die Daten? Große Mengen an gelabelten Daten erhalten wir aus den E-Mails der Vergangenheit. Für das Training brauchen wir sehr viele E-Mails, zu denen wir dem Trainingsalgorithmus den korrekten Mailempfänger mitgeben können. Wir gehen davon aus, dass in der Vergangenheit in den meisten Fällen der korrekte Empfänger angegeben wurde. Mit diesen Daten wollen wir verproben, ob wir ein System mit ausreichender Genauigkeit trainieren können.
Doch wie in vielen ML-Projekten und insbesondere in Projekten mit Textdaten sind die Trainingsdaten hochsensibel! In E-Mails an das Projekt-Management-Office können beispielsweise sensible Informationen zu Projektinhalten stehen. Deshalb dürfen wir die Trainingsdaten nicht einsehen oder analysieren – das ist vorerst auch nicht notwendig. Im ersten Schritt soll mit den Daten experimentiert und herausgefunden werden, ob sie ausreichend sind, um uns unserem Ziel zu nähern.
Genau an dieser Stelle scheitern viele ML-Projekte: weil sie nicht an die Daten kommen; weil der Datenschutz einen Riegel vorschiebt.
Es gibt verschiedene Wege, damit umzugehen:
- Wir können die Daten anonymisieren: Wir müssen Namen und Mailinhalte soweit verfälschen, dass daraus keinerlei sensiblen Informationen rekonstruierbar sind. Die Wahrscheinlichkeit, dass dabei Informationen verloren gehen, die wesentlich für die Zuordnung der E-Mails sind, ist allerdings hoch.
⇒ Diesen Weg haben wir verworfen. - Wir können die Daten verschlüsseln: Nach der Verschlüsselung können nur sehr einfache ML-Modelle trainiert werden. Komplexere Algorithmen, wie Deep Learning Networks, können möglicherweise die Entschlüsselung lernen. Sie könnten die E-Mails zumindest teilweise entschlüsseln oder Rückschlüsse auf die Informationen zulassen, die wir während des Debuggens lesen könnten.
⇒ Diesen Weg haben wir verworfen. - Wir können die relevanten Datenschutzrichtlinien klären: Dieser Weg bringt uns auf eine lange Reise, die nach unserer Erfahrung letztendlich zu den Ergebnissen von Punkt 1 oder 2 führt. Noch wissen wir nicht, ob wir mit den Daten das Ziel erreichen können.
⇒ Diesen Weg haben wir verworfen. - Wir können ein Protected Environment für Machine-Learning-Experimente aufbauen: Das Protected Environment ist so abgesichert, dass wir nicht auf die E-Mails oder deren Inhalt zugreifen können.
⇒ Diesen Weg haben wir gewählt!
Über das Protected Environment haben wir uns ein Experimentierfeld für unsere Machine-Learning-Algorithmen geschaffen. Wir haben keinen Zugriff auf die Inhalte der E-Mails, bekommen zu den vorgelegten Algorithmen allerdings Qualitätsaussagen zu den entsprechenden Modellen zurück. Damit können wir unsere Modelle ausprobieren und optimieren. Sobald ein Modell bis zu einer vorgegebenen Genauigkeit trainiert ist, kann es von unserem Kunden eingesetzt werden.
Abbildung 1 zeigt den Aufbau des Protected Environments und Experimentierfeldes für Machine Learning.
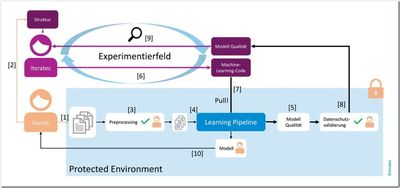
Abb. 1: Protected Environment: Preprocessing, Experimentierkreislauf, Ergebnis
Das Preprocessing
[1] Der Kunde, der Zugriff auf die Daten hat, stellt die E-Mails in dem Protected Environment zur Verfügung.
[2] Parallel dazu gibt er uns Informationen über die Struktur der Daten.
[3] Gemäß der Struktur bauen wir einen Preprocessor, der zum Beispiel Namen entfernt und die Daten auf relevante Informationen reduziert. Der Kunde prüft die Sicherheit des Preprocessors.
[4] Die durch den Preprocessor vorverarbeiteten E-Mails werden an die Learning-Pipeline weitergeleitet. Diese wird in einem späteren Abschnitt genauer erklärt.
[5] Die Learning-Pipeline erzeugt Modell-Qualitätsdaten.
Der Experimentierkreislauf
[6] Machine Learning heißt, mit Methoden und Modellen zu experimentieren. Wir können Trainingsalgorithmen bereitstellen.
[7] Diese werden von dem Protected Environment geholt und ausgeführt.
[8] Über ein geprüftes Modul werden Kennzahlen zu den Algorithmen nach außen gegeben. Hier kommen nur Zahlen an, die Auskunft über die Qualität des Modells geben, wie die Accuracy. Diesen Algorithmus – den Output-Generator – prüft der Kunde ebenfalls.
[9] Wir können die Algorithmen auf Basis der Kennzahlen beurteilen. So werden in einem Experimentierfeld verschiedene Algorithmen ausprobiert und optimiert.
Das Ergebnis
[10] Sobald eine gewünschte Genauigkeit erreicht ist, kann der Kunde das Modell aus dem Protected Environment holen und zum Einsatz bringen.
Die Learning-Pipeline ist der Weg von den vorverarbeiteten E-Mails zur Ausgabe der Modell-Qualität. Hierfür werden folgende fünf Schritte durchlaufen:
[1] Die vorverarbeiteten E-Mails werden eingelesen.
[2] Die Features werden aus den Daten generiert. Hierfür haben wir eine Auswahl von Feature-Generatoren.
[3] Auf Basis der Features wird ein Modell trainiert und optimiert. Hier können verschiedene Algorithmen verwendet werden.
[4] Wir haben im Vorhinein Qualitätskriterien für die Modelle definiert. Auf Basis dieser Kriterien wird die Modell-Qualität beurteilt.
[5] Die Werte der Qualitätskriterien werden aufbereitet und von einem Output-Generator für die Ausgabe vorbereitet.
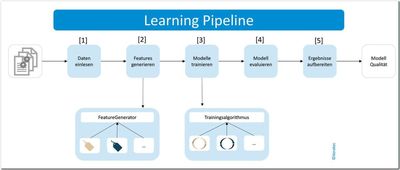
Abb. 2: Fünf Stufen der Learning-Pipeline
Durch den modularen Aufbau ist diese Pipeline sehr flexibel und kann leicht an andere Projekte angepasst werden. Wenn sich beispielsweise die Trainingsdaten ändern, müssen diese anders eingelesen werden, das Training bleibt aber identisch. Eine weitere Besonderheit dieser Pipeline ist die Variabilität der Feature-Generatoren und der Trainingsalgorithmen. Hierbei gibt es Oberklassen, die die Funktionalität vorgeben. Von diesen Oberklassen werden die einzelnen Implementierungen abgeleitet. Im weiter oben beschriebenen Experimentierkreislauf kann damit zwischen verschiedenen Kombinationen von Feature-Generatoren und Trainingsalgorithmen variiert werden. Außerdem können die Variablen der einzelnen Algorithmen ebenfalls angepasst und optimiert werden.
E-Mails sind Fließtexte, bei denen die Semantik eine wichtige Rolle spielt. Eine einfache Stichwortsuche würde die Daten zu stark vereinfachen und schlechtere Ergebnisse liefern. Um die Features der E-Mails unter Beachtung der Semantik zu generieren, wurden verschiedene Ansätze implementiert:
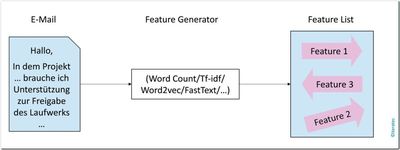
Abb. 3: Der Feature-Generator
- WordCount ist der einfachste hier verwendete Feature-Generator. Für eine E-Mail wird die Häufigkeit von allen darin enthaltenen Wörtern gezählt. Die Semantik der gesamten E-Mail wird daraufhin durch die häufigsten vorkommenden Wörter beschrieben. Verschiedene E-Mails sind sich dementsprechend umso ähnlicher, je mehr der häufigsten Wörter sie gemeinsam haben.
- Bei TF-IDF (Term-Frequency – Inverse Document-Frequency) wird neben der Häufigkeit von Wörtern auch deren Wichtigkeit miteinbezogen. Ein Wort ist umso aussagekräftiger und damit wichtiger, je öfter es innerhalb einer E-Mail und je seltener es insgesamt in allen E-Mails vorkommt.
- Bei Word2Vec handelt es sich um eine Methode, bei der ein vortrainiertes Word-Embedding eingesetzt wird [Wor]. Das Word-Embedding wurde trainiert, indem jedem Wort die Umgebungswörter zugeordnet wurden, die besonders häufig im gleichen Satz oder Absatz vorkommen. Dadurch wird im Word-Embedding die Bedeutung eines Wortes durch dessen umgebende Wörter bestimmt. Für semantisch ähnliche Wörter entstehen somit ähnliche Wortvektoren.
- FastText ist grundsätzlich eine Weiterentwicklung von Word2Vec von Facebook [Fas]. Das Word-Embedding wird hier jedoch nicht durch einzelne Wörter trainiert, sondern durch Teilwörter des jeweiligen Wortes. Der Vektor für das ganze Wort ergibt sich dann aus der Summe der Teilwort-Vektoren. Dadurch können auch Vektoren für Wörter generiert werden, die nicht im Word-Embedding vorkommen, allerdings aus mehreren einzelnen Wörtern zusammengesetzt sind, die wiederum schon im Word-Embedding enthalten sind. Das ist gerade in einer Sprache wie dem Deutschen, das sehr viele zusammengesetzte Wörter enthält, besonders relevant.
Auf diese Weise wird die Bedeutung eines Wortes in einem einzigen Vektor festgehalten. Dieser kann eingesetzt werden, um ausgehend von der Semantik einzelner Wörter die Bedeutung des Inhalts einer ganzen E-Mail zu beschreiben.
Die generierten Features der E-Mails können daraufhin zum Training eines Klassifikations-Modells eingesetzt werden. Jeder in den Trainingsdaten enthaltenen E-Mail ist die korrekte Klasse – also der richtige Empfänger – durch ein Label zugewiesen. Anhand der gelabelten Trainingsdaten kann ein Mapping zwischen den Features einer E-Mail und dem entsprechenden Label trainiert werden.
Ziel ist es, auf Basis dieses Mappings Modelle zu trainieren und in Prediction-Systeme einzubauen. Die Prediction-Systeme sollen neue, noch nicht gelabelte E-Mails den korrekten Klassen zuordnen und damit den richtigen Empfänger der jeweiligen E-Mail bestimmen.
Auch hier wurden einige unterschiedliche Ansätze getestet. Mit folgenden Trainingsmethoden konnten jeweils Modelle mit einer Genauigkeit von mindestens 89 Prozent erreicht werden.
Lineare Support-Vector-Machine (SVM)
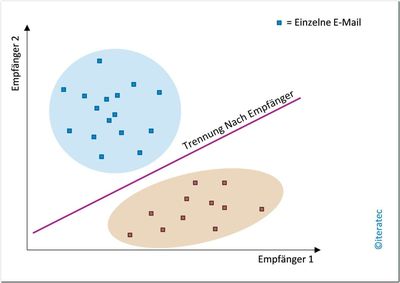
Abb. 4: Lineare SVM
Eine lineare SVM versucht, mehrere trennende Linien so in den Datenraum zu legen, dass die zu verschiedenen Klassen gehörenden Datenpunkte – die E-Mails – möglichst klar voneinander abgetrennt werden. Mithilfe der Trainingsdaten wird für jede Klasse eine möglichst optimal liegende Trennlinie ermittelt. Diese trennt die zur Klasse gehörenden E-Mails von allen anderen E-Mails. Ausgehend von den für jede Klasse entstehenden Trennlinien können neue E-Mails klassifiziert werden. Da die lineare SVM gute Ergebnisse liefert, ist naheliegend, dass unsere Daten zumindest annähernd linear trennbar sind.
Naïve-Bayes-Klassifikator
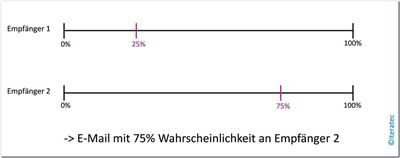
Abb. 5: Naïve-Bayes-Klassifikator
Der Naïve-Bayes-Klassifikator basiert auf der sehr vereinfachten Annahme, dass die Klassen untereinander unabhängig sind. Dadurch ist es möglich, die Wahrscheinlichkeitsverteilungen der möglichen Klassen anhand der Trainingsdaten abzuschätzen. Ausgehend von den so bestimmten Wahrscheinlichkeitsverteilungen kann für eine neue E-Mail ermittelt werden, mit welcher Wahrscheinlichkeit sie zu welcher der Klassen gehört. Dementsprechend wird sich zum Schluss für die Klasse mit der höchsten Wahrscheinlichkeit entschieden.
Random-Forest-Klassifikator
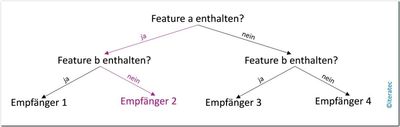
Abb. 6: Random-Forest-Klassifikator
Ein Random-Forest-Klassifikator ist ein Ansatz, der auf Entscheidungsbäumen basiert. Ein Entscheidungsbaum besteht aus Knoten und gerichteten Kanten. Alle Kanten verlaufen aus Richtung der Wurzel in Richtung der Blätter des Baums. An jedem Knoten wird für einen Datenpunkt entschieden, zu welcher der ausgehenden Kanten dieser Datenpunkt zugeordnet wird. Dies wird rekursiv wiederholt, bis der Datenpunkt an einem Blatt des Baums angekommen ist.
Ein Entscheidungsbaum wird anhand von gelabelten Trainingsdaten erstellt: Zu Beginn befinden sich alle E-Mails in der Wurzel des Baums. Daraufhin wird ein Feature der E-Mails gewählt, durch dessen Ausprägungen die einzelnen E-Mails möglichst klar voneinander abgetrennt werden können – beispielsweise das Vorkommen eines bestimmten Begriffs. Anhand der Ausprägung des Features wird daraufhin für jede E-Mail bestimmt, welchem Zweig des Baums sie zugeordnet wird: Zweig 1 – der Begriff kommt vor – oder Zweig 2 – der Begriff ist nicht enthalten. Innerhalb der Zweige eines Baums wird dieses Verfahren wiederholt, bis alle E-Mails ihrer richtigen Klasse zugeordnet wurden. Hierbei entsteht schnell ein sehr tiefer Entscheidungsbaum, der zu genau an die Trainingsbeispiele angepasst wurde und nicht mehr so gut generalisieren kann. Ein zu kleiner Entscheidungsbaum kann allerdings wiederum nicht genau genug klassifizieren.
An dieser Stelle kommt Random-Forest ins Spiel: Es werden parallel mehrere Entscheidungsbäume erstellt und jeder davon wächst anhand einer bestimmten Randomisierung. Um den Random-Forest-Klassifikator einzusetzen, wird eine E-Mail mit jedem der vorhandenen Entscheidungsbäume klassifiziert. Letztendlich wird eine E-Mail der Klasse zugeordnet, für die sich die meisten der Bäume entschieden haben.
Multilayer-Perceptron
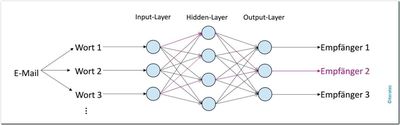
Abb. 7: Multilayer-Perceptron
Ein Multilayer-Perceptron ist ein neuronales Netz. Ein neuronales Netz ist eine Methode, um eine beliebig komplexe Funktion anzunähern. Auf diese Weise kann auch die Grenze zwischen Datenpunkten angenähert werden, um sie in mehrere Klassen zu unterteilen. Um diese Funktionalität umzusetzen, muss ein neuronales Netz trainiert werden. Die Features, anhand deren klassifiziert werden soll, werden durch die Input-Neuronen in der ersten Schicht in das neuronale Netz eingespeist. Die Input-Neuronen sind durch Kanten mit den Neuronen der folgenden Schicht verbunden und auch diese Neuronen sind mit den Neuronen der ihnen folgenden Schicht verbunden – das setzt sich bis zur letzten Schicht, dem Output-Layer, fort. Die Kanten sind gewichtet und diese Gewichte werden trainiert.
Um das Netz zu trainieren, werden gelabelte Trainingsdaten eingesetzt: Eine Beispiel-E-Mail, deren Empfänger bekannt ist, wird durch das Netz verarbeitet. Am Ende wird der vom Netz bestimmte Empfänger mit dem korrekten Empfänger verglichen: Stimmen diese beiden Klassen nicht überein, müssen die Gewichte innerhalb des Netzes verändert werden. Durch den Lernalgorithmus Backpropagation kann ermittelt werden, wie die Kantengewichte angepasst werden müssen, um die Klassifikation zu verbessern. Dieses Verfahren wird mit allen vorhandenen Trainings-E-Mails mehrmals durchgeführt, bis das Netz beim Klassifizieren aller Trainingsbeispiele eine bestimmte Genauigkeit erreicht hat. Dann kann es eingesetzt werden, um neue, noch unbekannte E-Mails zu klassifizieren.
Ein Multilayer-Perceptron ist eine sehr einfache Form eines neuronalen Netzes. Es besteht aus einem Input-Layer, mindestens einem Hidden-Layer und einem Output-Layer. Die Informationen innerhalb des Netzes fließen ausschließlich vom Input-Layer in Richtung Output-Layer, es gibt keine Rückverbindungen. Durch den Einsatz nicht-linearer Funktionen in den Neuronen kann ein Multilayer-Perceptron auch Daten klassifizieren, die nicht linear trennbar sind.
Ensemble der Methoden
Eine weitere getestete Methode ist ein Ensemble der oben aufgelisteten Modelle. Dabei wird, um eine E-Mail zu klassifizieren, nicht nur ein Klassifikator eingesetzt, sondern mehrere. Jedes der verwendeten Modelle erhält die E-Mail und entscheidet sich für eine der möglichen Klassen. Letztendlich wird die E-Mail der Klasse zugeordnet, für die sich die meisten der Klassifikatoren entschieden haben.
Verbessert eine Minimalwahrscheinlichkeit das Ensemble? Um eine verbesserte Klassifikation zu gewährleisten, sollten sich die einzelnen Modelle mit ihrer Entscheidung relativ sicher sein. Dementsprechend wurde in diesem Versuch die Entscheidung eines Klassifikators nur in das Ensemble einbezogen, wenn die Wahrscheinlichkeit der gewählten Klasse beispielsweise mindestens 70 Prozent betragen hat. Dieses Verfahren führte jedoch zu einer leichten Verschlechterung des Ensemble-Ergebnisses.
Mit dem Ensemble der Methoden ohne Minimalwahrscheinlichkeit konnten wir eine Genauigkeit der Ergebnisse von ca. 90 Prozent bei den Einzelmethoden auf 95 Prozent erhöhen.
Weitere Ansätze
Neben den aufgelisteten Modellen wurden weitere Ansätze ausprobiert, insbesondere komplexere neuronale Netze. Diese lieferten allerdings deutlich schlechtere Ergebnisse.
Nachdem wir verschiedene Modelle trainiert und optimiert hatten, haben wir ein Modell mit einer Genauigkeit von mehr als 95 Prozent erhalten. Damit konnten wir ein Add-in für Outlook bauen. Zu einer E-Mail kann jetzt über den Aufruf des Add-ins „Serviceteam vorschlagen“ mittels semantischer Textanalyse und Klassifizierung der Mailempfänger vorgeschlagen werden.
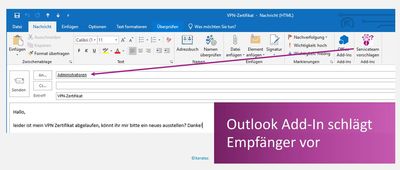
Abb. 8: Add-in für Outlook
Bedingt durch das Protected Environment erhalten wir während des gesamten Trainingsdurchlaufs keine Information über das System oder über den Status des Trainingsprozesses. Informationen dazu sind erst am Ende des jeweiligen Trainingsdurchlaufes verfügbar. Zusätzlich dauert ein Testdurchlauf sehr lange. Das System muss den Trainingsalgorithmus holen, die notwendigen Shell-Skripte anstoßen und der Output-Generator muss die Ergebnisse aufbereiten.
Durch die asynchrone Verarbeitung lagen die Rüstzeiten bei bis zu 15 Minuten. Hinzu kommt noch das Training des Modells, das je nach Trainingsalgorithmus teilweise über 24 Stunden dauert.
In dem Protected Environment hatten wir dadurch spezielle Themen zu beachten:
- In der gesamten Zeit ist außerhalb des Protected Environments unklar, ob das System noch läuft oder abgestürzt ist.
⇒ Der Administrator des Protected Environments muss die Learning-Pipeline loggen und monitoren. - Die Datenformate weichen teilweise stark von den Definitionen ab. Manche der Dateien sind defekt. Das Preprocessing-Modul stürzt mit ungeklärten Zuständen ab. Die entsprechenden Fehlersituationen dürfen allerdings nicht nach Außen gegeben werden. In den ersten Wochen kam es vermehrt zu diesen Fehlersituationen.
⇒ Der Admin des Protected Environments muss die Fehler prüfen und analysieren. Er muss in den ersten Wochen des Projektes eingeplant werden und zur Verfügung stehen. - Da wir keinen Einblick in das System haben, ist nicht sicher, ob der Algorithmus überhaupt läuft.
⇒ Wir haben ein Testsystem aufgesetzt, das identisch mit dem Protected Environment ist, dem jedoch nur synthetische Daten zur Verfügung stehen. In diesem Testsystem können wir die Fehlermeldungen einsehen und somit Logikfehler korrigieren. - Es können sehr viele Daten sein, auf denen trainiert werden soll. Wir wissen nicht, ob der Algorithmus mit den Daten läuft und ob wir ausreichend Ressourcen geplant haben.
⇒ Hierfür gibt es mehrere Lösungsansätze:- Training auf einem Teildatensatz starten und die Datenmengen schrittweise erhöhen, um die Ressourcenlast zu überblicken.
- Auch wenn Fehlermeldungen nicht nach außen gegeben werden können, können die Fehlertypen mittels Fehlercodes geschrieben werden. Dadurch wissen wir, wo der Fehler aufgetreten ist und um welche Fehlerart es sich handelt.
- Wenn die Fehlerursache weiterhin nicht gefunden werden kann, können Teile der Pipeline auskommentiert werden, um sich schrittweise dem Fehler zu nähern. Diese Fehlersuche ist sehr zeitaufwendig und vor allem auf komplexem Code nicht einfach.
Wir konnten in unserem Machine-Learning-Labor ein Protected Environment für Machine Learning aufbauen. Aus den Mails der Vergangenheit konnten wir ein Modell mit einer Genauigkeit von über 95 Prozent trainieren. Mit dem Protected Environment können wir über ein Add-in für Outlook zu einer Mail den Empfänger vorschlagen. Dank der flexiblen Architektur lassen sich auf hochsensiblen Textdaten verschiedener Strukturen Machine-Learning-Modelle trainieren.
Dieser Blog-Beitrag ist auch im Online-Themenspecial Künstliche Intelligenz 2018 der Fachzeitschrift OBJEKTspektrum (www.objektspektrum.de) erschienen.
Noch Fragen?
Was bedeutet Machine Learning und wie kann Ihr Unternehmen vom Einsatz profitieren? Erfahren Sie, wie wir Sie beim Thema Machine Learning unterstützen können:
 Stefan Blum - arbeitet bei iteratec in München. Er begeistert sich für Machine Learning, Artifical Intelligence und Data Mining.
Stefan Blum - arbeitet bei iteratec in München. Er begeistert sich für Machine Learning, Artifical Intelligence und Data Mining.
Literatur
[Fas] FastText von Facebook, https://fasttext.cc/
[Wor] Word2Vec Word-Embedding, https://devmount.github.io/GermanWordEmbeddings/
Weitere Artikel










- Juni 2026
- April 2026
- Februar 2026
- Januar 2026
- Dezember 2025
- November 2025
- Oktober 2025
- August 2025
- Juli 2025
- Juni 2025
- Mai 2025
- April 2025
- März 2025
- Februar 2025
- Januar 2025
- Oktober 2024
- September 2024
- August 2024
- Juli 2024
- Juni 2024
- Mai 2024
- April 2024
- März 2024
- Februar 2024
- Januar 2024
- Dezember 2023
- November 2023
- September 2023
- August 2023
- Juli 2023
- Juni 2023
- Mai 2023
- April 2023
- Februar 2023
- Dezember 2022
- November 2022
- Mai 2022
- April 2022
- März 2022
- Januar 2022
- Dezember 2021
- November 2021
- Oktober 2021
- August 2021
- Juli 2021
- Juni 2021
- Mai 2021
- April 2021
- Dezember 2020
- Oktober 2020
- September 2020
iteratec
iteratec ist der Partner für alle, die zu den Gewinner:innen der digitalen Transformation gehören wollen. Mit individuellen, überlegenen Lösungen eröffnen wir unseren Kunden technologische wie unternehmerische Potenziale. Denn: Wenn Scheitern keine Option ist, sind wir der Partner, der den Unterschied macht. So haben wir seit 1996 mehr als 1.000 Projekte zum Erfolg geführt und eine Kundenzufriedenheit von 97%.









{kind=link}