
Cloud-native vs. Rechenzentrum
Im ultimativen Infrastrukturvergleich treten zwei unterschiedliche Plattformansätze einer Anwendungsfamilie gegeneinander an. Anhand der Prinzipien der 12-Factor App vergleichen wir eine cloud-native mit einer Rechenzentrum-basierten Infrastruktur:
-
Teil 2: Factor III: Config - Store config in the environment
-
Teil 3: Factor IV: Backing Services - Treat backing services as attached resources
-
Teil 4: Factor VII: Port Binding – Export services via port binding
- Teil 5: Factor X: Dev/Prod parity – Keep development, staging, and production as similar as possible
- Teil 6: Factor XI: Logs – Treat logs as event stream
In dieser Runde erfahren Sie, wie Event-basiertes Logging dabei hilft, mögliche Fehler frühzeitig zu erkennen und Bugs schnell und zielgerichtet mithilfe von Dashboards und Suchfunktionen zu lokalisieren.
Inhalt
Aussage des Faktors Event-basiertes Logging
Treat logs as event stream [12F6] ist die zentrale Aussage des nächsten Faktors, den wir im Detail betrachten wollen. In traditionellen Anwendungen werden Logs oft in Files geschrieben und auf dem Server abgelegt. Dazu muss die Anwendung selbst einen Teil des Mikromanagements der Logs übernehmen, zum Beispiel deren Speicherort festlegen. Nachdem Logs aber zeitgeordnete und aggregierte Events darstellen, die kontinuierlich erzeugt werden, stellt sich die Frage, ob Files tatsächlich die beste Lösung zur Repräsentation von Logs darstellen. Die 12-Factor App soll explizit keine Logs in Files schreiben, sondern stattdessen Dienste einbinden, die die Logs aller Prozesse sammeln und dem Benutzer über dedizierte Boards in Echtzeit zur Verfügung stellen.
Die Umsetzung dieses Faktors bietet uns nicht nur in der Cloud, sondern auch beim Betrieb auf klassischer Infrastruktur diverse Vorteile. Insbesondere wird die Analyse und das Management der Logs deutlich vereinfacht. Mithilfe moderner Tools wir Splunk oder Kibana können wir in Logs suchen und diese nach bestimmten Events filtern. Zudem bietet sich die Möglichkeit, Trends zu extrahieren sowie Benachrichtigungen bei Schwellwertüberschreitungen zu konfigurieren. Wenn wir diese Optionen für uns nutzen, können wir wesentlich schneller auf Fehler reagieren bzw. diese bereits frühzeitig erkennen und entsprechende Maßnahmen und Anpassungen vornehmen. Im Vergleich zu traditionellen Logfiles, die heruntergeladen und dann händisch analysiert werden müssen, bietet dies einen enormen Vorteil. Ein explizites Management der Files auf den Servern ist zudem nicht mehr nötig.
File-basiertes Logging im Rechenzentrum
Ursprünglich gab es in APP1 ausschließlich file-basiertes Logging. Dies führt dazu, dass aufseiten des Codes entsprechende Konfigurationen gepflegt werden müssen. Dies kann zum Beispiel wie folgt aussehen:
<appender name="LOG_FILE_APPENDER" class="ch.qos.logback.APP2.rolling.RollingFileAppender">
<file>${log_dir}/<LOGFILE_NAME>.log</file>
<append>true</append>
<immediateFlush>true</immediateFlush>
<rollingPolicy class="ch.qos.logback.APP2.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>${log_dir}/<LOGFILE_NAME>.%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<maxFileSize>100MB</maxFileSize>
<maxHistory>30</maxHistory>
<totalSizeCap>3GB</totalSizeCap>
</rollingPolicy>
<encoder>
<pattern>${LOG_FILE_PATTERN}</pattern>
</encoder>
</appender>
Wie üblich für file-basiertes Logging legen wir eine Rolling Policy fest, um zu verhindern, dass die geschriebenen Dateien zu groß werden. Die Konfiguration macht zudem deutlich, dass die Anwendung selbst Detailwissen über das Management der Logs haben muss. So muss explizit das Verzeichnis und der Name der Datei festgelegt werden. Dies kann als eine zusätzliche Verletzung des Backing Services Faktors, den wir bereits analysiert haben, interpretiert werden.
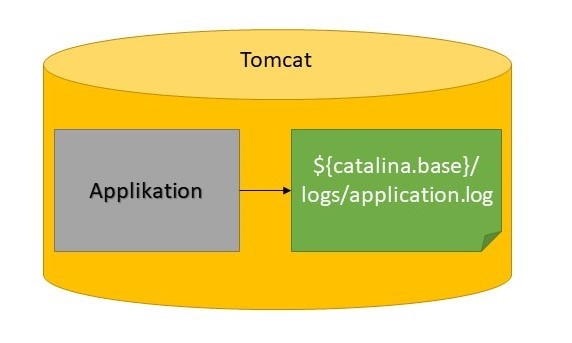
Neben des Managements der Logs durch Anwendung und Applikationsserver, ist bei einem solchen Setup die Loganalyse häufig suboptimal. Bei APP1 mussten aufgrund der expliziten Trennung von Entwicklung und Betrieb die Logfiles händisch von den Servern heruntergeladen und entpackt werden, bevor eine Analyse stattfinden konnte. Ein solcher Ansatz ist bei der Analyse von Bugs oder deren Früherkennung äußerst hinderlich. Ein mögliches Szenario könnte wie folgt aussehen: Der Fachbereich meldet einen Fehler in Produktion, der vor einigen Tagen aufgetreten ist. Das Entwicklungsteam wird hierzu per Mail informiert und lädt daraufhin die Logfiles der letzten Tage von allen Servern herunter. Die Überprüfung der verschiedenen Files muss nun händisch erfolgen. Wurde endlich der relevante Log-Eintrag gefunden, kann die Analyse des Bugs im Code starten. Dieser Prozess ist langwierig und unübersichtlich, auch wenn er sich durch den Einsatz lokaler Tools durch die Entwickler etwas straffen lässt.
In einer modernen Umsetzung des Loggings könnte oben beschriebene Situation wie folgt gelöst werden: Die Logs werden kontinuierlich gesammelt und in einem Log-Browser / Dashboard bereitgestellt. Weil eingehende Events gefiltert und regelbasiert ausgewertet werden, erfahren die Entwickler von dem Fehler lange bevor die Meldung des Anwenders weitergegeben wird. Außerdem ist der direkt lokalisiert und die Fehlerbehebung kann sofort durchgeführt werden.
Mittlerweile ist für APP1 Splunk angebunden. Somit ist eine deutlich vereinfachte Analyse der Logs im oben beschriebenen event-basierten Sinne möglich. Außerdem erhalten wir über Nagios automatisiert E-Mails, wenn es Fehler in den Logs gibt. Allerdings erforderte die Realisierung dieser Anbindungen prozessbedingt hohen Kommunikationsaufwand. Zuerst muss der Wunsch der Entwickler, moderne Tools zur Umsetzung des Loggings zu verwenden, genehmigt werden. Ist dies erfolgt, so kann mit der Umsetzung begonnen werden. Im Gegensatz zu APP2, wo Dienste durch das Entwicklungsteam in Eigenverantwortung schnell eingebunden werden können, muss dies im Rechenzentrum vom Betrieb übernommen werden. Die fertige Einrichtung muss dann wiederum durch das Entwicklungsteam getestet werden. Besteht weiterer Anpassungsbedarf, wie zum Beispiel beim Alerting durch Nagios, so muss eine weitere Runde gedreht werden. Tatsächlich lagen zwischen dem Wunsch der Entwickler eine moderne Logging-Lösung zu verwenden und der vollständigen Umsetzung mehrere Monate trotz tatkräftiger Unterstützung durch den IT-Bereich. Im Endeffekt hat es sich aber ausgezahlt, für eine solche Umsetzung des Loggings zu plädieren. Auf lange Zeit profitieren davon nicht nur Entwickler, sondern insbesondere die Benutzer der Anwendung.
Event-basiertes Logging in der Cloud
Cloud Foundry stellt Logging als Dienst zu Verfügung. Dies entspricht auch dem Prinzip der Backing Services, das wir bereits im letzten Teil der Serie kennengelernt haben. Bei der konkreten Wahl der Cloud Foundry Plattform gibt es in der Regel verschiedene Dienste, die für das Logging eingebunden werden können. Im Rahmen von APP2 haben wir uns für eine Variante des ELK-Stacks entschieden. Logs werden durch FluentD aggregiert und dann zur Speicherung an Elastic Search weitergeleitet. Kibana bietet uns zudem Dashboards, die diese Informationen grafisch aufbereiten. All dies bekommen wir als Paket. Es ist also nur die Erstellung eines einzigen Services und dessen Anbindung an unsere Applikation notwendig.
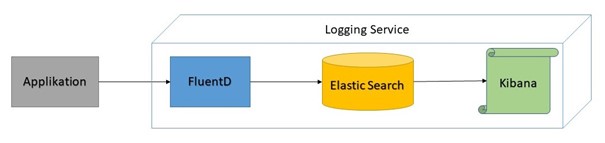
Per default verwendet der Dienst syslog als Logging-Format. Allerdings macht es Sinn, ein vielseitigeres Format zu definieren. Unser Dienst erlaubt es uns hier, das sogenannte Graylog Extended Log Format (GELF) [GELF] zu benutzen. Dazu sind nur einige wenige Konfigurationen in unserer Codebasis nötig. Zunächst einmal müssen wir eine entsprechende Abhängigkeit definieren:
<dependency>
<groupId>de.siegmar</groupId>
<artifactId>logback-gelf</artifactId>
<version><VERSION></version>
</dependency>
Des Weiteren fügen wir für unsere Applikation die gewünschte Konfiguration zu logback-spring.xml hinzu:
<springProperty scope="context" name="gelfHost" source="vcap.services.logging.credentials.host"/>
<springProperty scope="context" name="gelfPort" source="vcap.services.logging.credentials.port"/>
<springProperty scope="context" name="space" source="vcap.application.space_name"/>
<appender name="GELF" class="de.siegmar.logbackgelf.GelfTcpAppender">
<graylogHost>${gelfHost}</graylogHost>
<graylogPort>${gelfPort}</graylogPort>
<encoder class="de.siegmar.logbackgelf.GelfEncoder">
<includeMdcData>true</includeMdcData>
<includeLevelName>true</includeLevelName>
<staticField>space:${space}</staticField>
<shortPatternLayout class="ch.qos.logback.classic.PatternLayout">
<pattern>%.-1000m%nopex</pattern>
</shortPatternLayout>
</encoder>
</appender>
<appender name="ASYNC_GELF" class="ch.qos.logback.classic.AsyncAppender">
<appender-ref ref="GELF"/>
</appender>
Hier ist es interessant anzumerken, dass die Konfiguration auch einen anderen Faktor, Config, umsetzt. Wie wir bereits besprochen haben geht es dabei darum, Konfiguration über Umgebungsvariablen zu injizieren. Der Auszug zeigt, wie dies bei der Definition des Loggings aussehen kann. Die Variablen, die wir in den springProperty tags erstellen, werden durch Umgebungsvariablen gesetzt, die Cloud Foundry zu Verfügung stellt (source=vcap...). Die Konfiguration des Loggings ist somit unabhängig von der konkreten Stage.
Außerdem geschieht das Management der Logs komplett außerhalb der Kernanwendung. Die Anwendung muss sich nicht darum kümmern, wie die Logs in Elastic Search landen. Dies wird durch FluentD abstrahiert und somit aus der Applikationslogik gelöst. Somit ist sichergestellt, dass die Prinzipien der Backing Services auch auf dem Level des Loggings eingehalten werden.
Als Konsequenz ist es uns möglich und auch empfohlen, bereits in frühen Phasen der Entwicklung schnell und einfach auf event-basiertes Logging zu setzen. Wir können bei Bedarf verschiedene Varianten testen und anhand der gewonnenen Erkenntnisse entscheiden, welcher Dienst am besten unsere Anforderungen und Wünsche erfüllen kann. Dazu ist keine aufwendige Kommunikation notwendig, sondern einige einfache Befehle, die das Entwicklungsteam eigenständig ausführen kann. Das ist aber nur möglich, weil bei der Entwicklung und beim Betrieb von APP2 auf DevOps gesetzt wird. Mehr Details dazu haben wir bereits ausführlich im Rahmen anderer Beiträge dieser Serie besprochen.
Fazit
Wir haben gesehen, dass ein moderner, event-basierter Ansatz des Loggings hilft, mögliche Fehler frühzeitig zu erkennen und Bugs schnell und zielgerichtet mithilfe von Dashboards und Suchfunktionen zu lokalisieren. Eine solche Umsetzung des Loggings ist nicht auf die Cloud beschränkt und sollte aufgrund seiner Mächtigkeit auch in klassischen Anwendungen umgesetzt werden. Wir haben gesehen, dass dies in APP1 bereits der Fall ist, auch wenn die Prozesse im Rechenzentrum dazu geführt haben, dass die vollständige Umsetzung basierend auf Nagios und Splunk kommunikations- und zeitintensiv waren. Dies ist zu vergleichen mit dem analogen Vorgehen im Rahmen von APP2. Hier wird der ELK-Stack über die Cloud Foundry CLI eingebunden und mithilfe einiger weniger Anpassungen konfiguriert. All dies kann selbstständig und im Sinne eines DevOps Vorgehens durch die Entwickler gemacht werden. Dies spart Zeit und hilft dabei, den Abstimmungsbedarf zu minimieren.
Noch Fragen?
Weitere Informationen und Hilfestellungen rund um die Gestaltung und Weiterentwicklung hochperformanter IT-Infrastrukturen und Applikationslandschaften finden Sie unter:
Referenzen:
[12F6]: THE TWELVE-FACTOR-APP - XI. Logs, siehe: https://12factor.net/logs
[GELF]: graylog, siehe: https://www.graylog.org/features/gelf
Weitere Artikel










- Juni 2026
- April 2026
- Februar 2026
- Januar 2026
- Dezember 2025
- November 2025
- Oktober 2025
- August 2025
- Juli 2025
- Juni 2025
- Mai 2025
- April 2025
- März 2025
- Februar 2025
- Januar 2025
- Oktober 2024
- September 2024
- August 2024
- Juli 2024
- Juni 2024
- Mai 2024
- April 2024
- März 2024
- Februar 2024
- Januar 2024
- Dezember 2023
- November 2023
- September 2023
- August 2023
- Juli 2023
- Juni 2023
- Mai 2023
- April 2023
- Februar 2023
- Dezember 2022
- November 2022
- Mai 2022
- April 2022
- März 2022
- Januar 2022
- Dezember 2021
- November 2021
- Oktober 2021
- August 2021
- Juli 2021
- Juni 2021
- Mai 2021
- April 2021
- Dezember 2020
- Oktober 2020
- September 2020
iteratec
iteratec ist der Partner für alle, die zu den Gewinner:innen der digitalen Transformation gehören wollen. Mit individuellen, überlegenen Lösungen eröffnen wir unseren Kunden technologische wie unternehmerische Potenziale. Denn: Wenn Scheitern keine Option ist, sind wir der Partner, der den Unterschied macht. So haben wir seit 1996 mehr als 1.000 Projekte zum Erfolg geführt und eine Kundenzufriedenheit von 97%.








