
Irgendwann kommt der Zeitpunkt, an dem die Anwender der Software beginnen in den Begriffen des Modells zu denken und in diesem System zu handeln. Und spätestens wenn das Modell eine Eigendynamik gewinnt und anfängt sich weiterzuentwickeln, kann das sehr kuriose Folgen haben. Etwa dann, wenn nicht einmal der Anwender selbst seine eigene Business-Domäne versteht.
Welche Auswirkungen und Konsequenzen es haben kann, wenn sich das Modell selbstständig weiterentwickelt, haben wir in einem unserer Projekte herausgefunden. Wir zeigen, was genau passiert ist und verdeutlichen das zugrundeliegende Problem anhand eines fiktiven Beispiels.
tl;dr 3 Thesen, die helfen können, das folgende Problem im eigenen Projekt zu bewältigen:
- Für die Business-Analysten: Conway's Law wirkt in beide Richtungen!
- Für die Architekten: Archäologie gehört zum Job – und Relationen sind keine Dinge!
- Für die Entwickler: Primare Keys in Intersection Tables sind die Wurzel (fast) allen Übels!
Inhalt:
- Warum eigentlich Domain Driven Design?
- Die Archäologie die dahinter steckt
- Wie wäre es mit einem Beispiel?
3.1 Das Artefakt
3.2 Pompeji
3.3 Archäologie 101
3.4 Genealogie
3.5 Implementierungshinweise - Fazit
1. Warum eigentlich Domain Driven Design?
Spätestens seit dem bekannten Buch "Domain-Driven Design: Tackling Complexity in the Heart of Software" von Eric Evans fällt die Erstellung eines Modells - übrigens eine der wichtigsten Aufgaben in der Softwareentwicklung - unter die Kategorie des Domain Driven Design (DDD).
Die Bedeutung der Modellierung wird in der Implementierung häufig unterschätzt, da sich Modellklassen nach landläufiger Meinung a) "jederzeit noch ändern lassen" und b) "es ja nicht so wichtig ist, wie man es abbildet, solange es funktioniert".
Beide Ansichten erweisen sich häufig als fatale Fehleinschätzung. Warum das so ist, verdeutlicht ein Beispiel aus einem unserer Projekte. Dabei ist es wichtig, sich einen zentralen Gedanken in Erinnerung zu rufen. Diesen hat Evans in seinem Buch mehrmals und vehement betont: Das Modell ist der Punkt, an dem die Sprache der Anwender und die Sprache der Entwickler sich berühren.
An dieser Schnittstelle findet der größte Teil der Kommunikation zwischen Anwendern und Entwicklern statt. Und diese kann unterschiedlich effizient gestaltet sein. Folgt man der Metapher, dass Anwender wie Entwickler eine "eigene Sprache sprechen", dann ergibt sich daraus die Notwendigkeit, die Sprache der einen in die der anderen zu übersetzen, um eine effiziente Kommunikation zu ermöglichen.

Nun ist es aber leider eine Eigenschaft aller Übersetzungen, dass sie große Unschärfen zulassen. Es ist also sehr gut möglich, zu denken, man verstehe einander, um dann Wochen – und Tausende Euro – später festzustellen, dass man schlicht aneinander vorbeigeredet hat. Evans charmante Idee, um das Übersetzungsproblem zu entschärfen, besteht darin, das Modell als Berührungspunkt der Sprachen von Entwicklern und Anwendern zu begreifen:
Wenn dieses die Vorstellungen des Kunden nicht nur übersetzt, sondern sie 1:1 abbildet, dann werden die Welten der Entwickler und die der späteren Anwendern auf eine effiziente Art aneinander gebunden. Somit kann die Übersetzungsproblematik zumindest verringert werden.
Es gibt allerdings noch eine fatale, selten beleuchtete Konsequenz einer Modellierung, welche nicht eine korrekte Abbildung der realen Welt ist: Die Anwender der Software beginnen im Laufe der Zeit, in den Begriffen des Modells zu denken. Und spätestens wenn das Modell eine Eigendynamik gewinnt und anfängt sich weiterzuentwickeln, kann das sehr kuriose Folgen haben. Etwa dann, wenn nicht einmal der Anwender selbst seine eigene Business-Domäne versteht.
Anhand eines fiktiven Beispiels möchte ich hier davon berichten und die Frage beleuchten: Was passiert, wenn die historisch gewachsene™ Software mit einem Domänenmodell operiert, welches die reale Welt nicht mehr ansatzweise so abbildet, wie sie es einmal getan hat? Welche Auswirkungen hat es, wenn das Modell sich ohne jeden Kontakt zur Realität unkontrolliert weiterentwickelt? Und was können Softwareentwickler tun, nachdem sie sich an diese Umstände gewöhnt haben?

2. Die Archäologie, die dahinter steckt
Die Tätigkeit, die notwendig wird, wenn man einem historisch gewachsenen Modell gegenübersteht, hat weniger mit DDD, als mit Archäologie zu tun. Ein häufiger Fehler ist es, solche Modelle für bare Münze zu nehmen.
Sicher ist es richtig, sich fremden Leistungen mit einem angemessenen Maß an Respekt zu nähern; schließlich wünscht man sich dasselbe für die eigene Leistung. Umgekehrt ist es allerdings naiv anzunehmen, dass ein vorgefundener Code oder gar ein vorgefundenes Modell korrekt seien. Denn zum einen machen selbst die besten Entwickler und Architekten Fehler, zum anderen wird viel Leistung unter Einschränkungen erbracht, die sich der Kontrolle der besten Entwickler entziehen. Des Weiteren hat man selbst die Auswirkungen des historischen Wachstums so häufig erlebt, dass man sich keine Steinwürfe aus dem Glashaus erlauben sollte.
Aber warum Archäologie?
Weil man an der Oberfläche eines historisch gewachsenen™ Artefakts beginnt, das sich nach der ersten Prüfung als ein aus der Form gegossenes Kunstwerk zeigt. Aber im Laufe der Analyse gelangt man zu der Erkenntnis, wie das Artefakt vor langer Zeit entstanden ist und wie seine initiale Gestalt war.
Die Archäologie von Modellen offenbart, wie das Modell einmal vor Urzeiten aussah und gedacht war und welche historische Entwicklung es durchlaufen hat, um heute in einer neuen Gestalt zu erscheinen. Mit Blick auf die Vergangenheit wird häufig klar, dass nicht alle Entscheidungen korrekt waren und aus diesen Lehren können sich fundamentale Vereinfachungen ergeben.
3. Wie wäre es mit einem Beispiel?
Nehmen wir an, wir erhielten einen Auftrag, eine in den 90er-Jahren entstandenen Softwarelösung zu modernisieren. Die erste Domäne, die wir uns dabei vornahmen, war die Stammdatenverwaltung der Fantasy-Basketball-Liga. Interviews mit den Anwendern ergaben, dass die fundamentalste Entität des Modells die sogenannten LigaTeams waren.
3.1 Das Artefakt
Die Anforderung war denkbar einfach: es wurde eine Stammdatenverwaltung dieser LigaTeams benötigt, sie sollten über die UI pflegbar sein. Als Minimum Viable Product (MVP) sollte eine Version gebaut werden, die es zunächst nur erlauben sollte, das Datumsfeld "bis" der LigaTeams zu pflegen, das offenbar abbildete, bis wann das Team "aktiv" gewesen war. Die oberflächliche Domänen-Analyse, die anhand des Codes der Alt-Anwendung und der Datenbank durchgeführt wurde, ergab folgende ERD-Repräsentation:
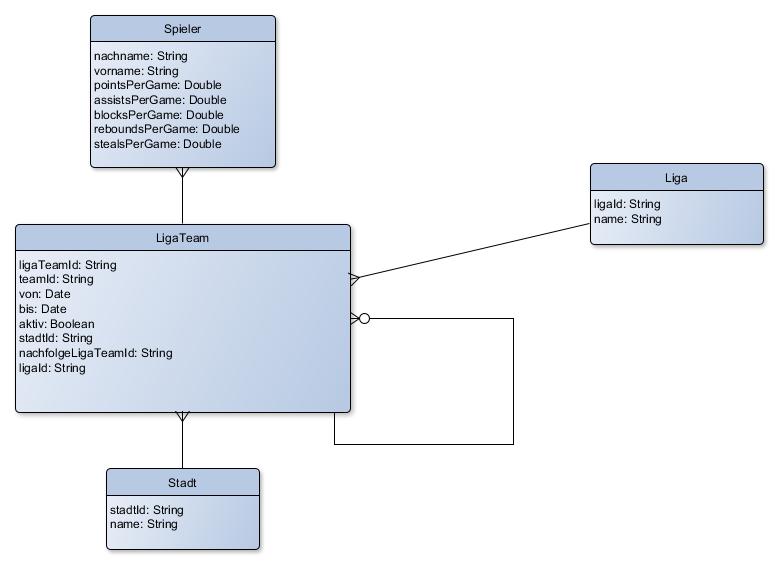
Es schien sehr klar: Spieler spielten in LigaTeams, diese spielten in Ligen, waren in Städten angesiedelt und sie konnten "Nachfolge-LigaTeams" haben.
An dieser Stelle wäre es wichtig gewesen, einige fundamentale Fragen zu stellen, doch schien die Anforderung so klar ("wir brauchen eine Stammdatenverwaltung für die LigaTeams") und die Versuchung, die 90er-Jahre-WindowsForms-UI durch eine flashy "Angular-SCSS-you name it"-Implementierung abzulösen, um einen ShowCase für die Vorteile moderner Technologien abzuliefern, war groß.
Es entstand also eine sehr hübsche UI, in der die LigaTeams verwaltet werden konnten, das Ergebnis wurde dem Kunden präsentiert und dort begeistert abgenommen. Es wurden einige Kleinigkeiten bemängelt: so war es zum Beispiel wichtig, dass ein LigaTeam, dessen "bis"-Datum in der Vergangenheit lag, beim Speichern als inaktiv ("aktiv" = false) markiert werden musste, was einigen Sinn zu geben schien.
Bis zu diesem Punkt war uns nur eine Merkwürdigkeit aufgefallen: die Anzahl der LigaTeams hatte uns überrascht. Wir waren implizit wohl davon ausgegangen, dass es 20 Teams pro Liga und etwa vier Ligen geben würde, doch hätte sich daraus eine Anzahl von 80 LigaTeams ergeben. De Facto gab es etwa 120 davon. Doch war die Abweichung nicht so groß, dass sie uns aus Performance-Perspektive Sorgen machte, und es war bereits angedeutet worden, die Datenqualität sei nicht herausragend, es könne gut einige Karteileichen geben.
Schwieriger wurde es, als die nächste Anforderung aufkam, man solle nun auch neue LigaTeams anlegen können. Die Anforderung, das "C" in CRUD nachzuliefern, schien zunächst halbwegs trivial implementierbar zu sein. Es stellte sich nun aber sehr bald die Frage, weshalb die Entität LigaTeam eigentlich nicht nur eine "ligaTeamId", sondern auch eine "teamId" (offenbar ein Freitextfeld) besaß.
Auf Nachfrage sah uns der Kunde verdutzt an und erwiderte, dabei handele es sich natürlich um die ID des Teams.
- Aber das sei doch sicherlich die "ligaTeamId"?
Nein, die "ligaTeamId" sei natürlich die ID des LigaTeams!
Es kommen stets Momente in solchen Gesprächen, in denen jeder der beiden Gesprächspartner der Ansicht ist, der andere habe den Verstand verloren. Dies war einer von diesen Momenten.
Irgendwann kam ein Entwickler auf den glücklichen Gedanken, den Kunden zu fragen, ob es für ihn einen Unterschied zwischen Teams und LigaTeams gebe. Den gab es. Er ließ sich aber scheinbar schwer in Worte fassen und die Anwender bestanden ohnehin darauf, dass die Team-ID ein Freitext-Feld war und sie es manuell eingeben wollten, daher stellte das Feld vorläufig kein wirkliches Problem dar und wir erstellten eine UI, die die Pflege der LigaTeams ermöglichte. Die Liga-ID referenzierte die Entität Liga, die man aus einem Dropdown wählen konnte. Die optionale Selbst-Assoziation "nachfolgeLigaTeamId" wählte man aus einer Suche über die aktiven Liga-Teams.
Die Implementierung wurde erneut begeistert aufgenommen, wenngleich bemängelt wurde, dass natürlich das Setzen einer "nachfolgeLigaTeamId" nur für inaktive LigaTeams möglich sein sollte. Auch diese Validierung war schnell implementiert. Es schien, als hätten wir unseren MVP erfolgreich abgeliefert. Von hier an ging es bergab.
3.2 Pompeji
Nachdem wir in der Euphorie begannen anzudeuten, wir wollten diesen MVP nun möglichst bald in die Produktionsumgebung deployen, begann die Stimmung merklich abzukühlen. Offenbar hatte man unseren MVP für einen allerersten Wurf gehalten, der noch einige Monate lang verfeinert werden musste. Wir umgekehrt konnten uns kaum vorstellen, was man an diesem doch letztlich sehr einfachen Objektgeflecht noch ändern wollen könnte. Wir nahmen also eine Liste der absoluten Mindestanforderungen für eine produktive Nutzung auf. Die wichtigste Anforderung war die folgende:
- REQ-1: Stadtwechsel:
Es soll möglich sein, einen Stadtwechsel eines Teams einzupflegen. Hierzu ist für alle aktiven LigaTeams mit einer gegebenen Team-ID das "bis"-Datum auf den heutigen Tag zu setzen und es ist jeweils ein Nachfolge-LigaTeam zu erstellen, das mit der neuen Stadt verknüpft ist.
Hinzu kamen weitere unerlässliche Anforderungen:
- REQ-2: Validierung "von"/"bis" der LigaTeams:
Es ist sicherzustellen, dass die Zeiträume (von-bis) der LigaTeams mit derselben Team-ID und Liga-ID sich nicht überschneiden. - REQ-3: (In-)aktiv-Schaltung von LigaTeams:
Es sollen nachträglich alle LigaTeams, deren "bis" in der Vergangenheit liegt auf "aktiv" = false gesetzt werden (und umgekehrt).
3.3 Archäologie 101
Wir diskutierten die Anforderungen und nach kurzem wurde klar, dass wir die Semantik der Entität LigaTeam schlicht nicht begriffen hatten.
Die Daten "von"/"bis" schienen eine andere Bedeutung zu haben, als wir angenommen hatten, und insbesondere die ominöse Team-ID schien einen Hinweis darauf darzustellen, was das Modell tatsächlich abbildete. Es gab an dieser Stelle mehrere Fäden, an denen man ziehen konnte, und jeder führte zur selben Erkenntnis. Man hatte uns die LigaTeams als die fundamentalste Entität der Domäne verkauft - und zwar, weil sie die fundamentalste Entität der alten Anwendung gewesen war.
Sowohl die Anforderung, dass LigaTeams mit derselben Team-ID und Liga-ID keine sich Überschneidenden "von"-"bis"-Zeiträume aufweisen durften, als auch die Anforderung, dass der Stadtwechsel eines Teams eine Änderung an allen LigaTeams mit derselben Team-ID nach sich zog, gaben den entscheidenden Hinweis auf das tatsächlich zugrundeliegende Domänenmodell: die fundamentalste Entität des Systems waren tatsächlich die Teams - nur eben nicht die "LigaTeams", sondern die implizite Entität, die durch das Freitext-Feld "teamId" abgebildet wurde. Ein Team im System entsprach einer Team-ID. Doch welche Rolle spielten dann die immer mysteriöser werdenden LigaTeams?
Nachdem wir nun von der Annahme ausgingen, die Team-ID bilde in Wirklichkeit die realweltlichen Teams ab, ergab sich das realweltliche Modell sehr schnell von selbst. Die Domäne stellte sich am Ende der Analyse wie folgt dar:
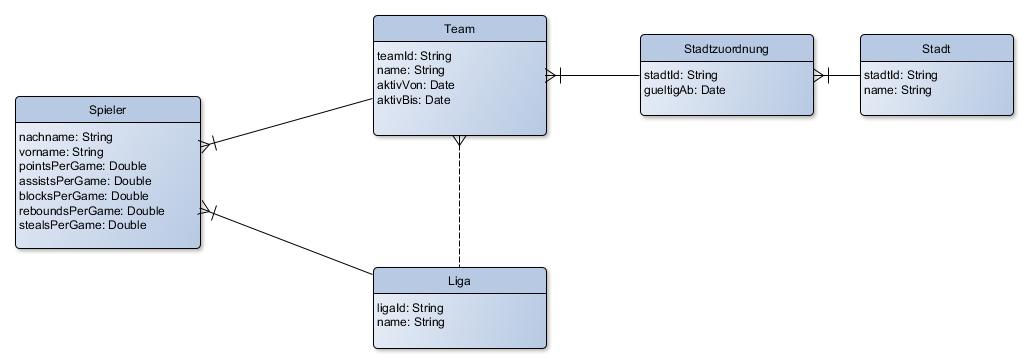
Ein Spieler hatte eine n..1-Zuordnung zu Teams ("ein Spieler spielt in einem Team"), hatte aber eine genauso eine n..1-Zuordnung zu einer Liga. Der Hintergrund war, dass manche Teams an mehreren Ligen teilnahmen, jeder Spieler dabei aber nur in einer Liga gemeldet sein konnte. (Man hätte sicherlich das Erstliga-Team und das Zweitliga-Team als zwei Objekte modellieren können, doch war die Intuition der Anwender, es handele sich dabei um dasselbe Team sehr stark. Dies ist eine Instanz des Ubiquituous Language-Prinzips: Abweichungen des technischen Modells vom fachlichen Modell sollten - soweit möglich - vermieden werden.)
Zum einen schien es also, als wären die Entitäten Liga und Team zu einer Entität LigaTeam verschmolzen worden, um den Sachverhalt abzubilden, dass ein Team mehreren Ligen angehören konnte.
Dies erklärte, weshalb der Stadtwechsel eines Teams zum Update mehrerer LigaTeams führte.
Doch blieb noch das Rätsel der "von" und "bis"-Daten. Ein genauer Blick auf das erstellte fachliche Modell legte nahe, dass hier erneut zwei Dinge verschmolzen worden waren: zum einen bildete der "von"-"bis"-Zeitraum eines LigaTeams, wie wir vermutet hatten, die "Aktivität" eines Teams ab. Doch was war dann der Grund für die merkwürdige Anforderung "REQ-2": dass die Zeiträume der LigaTeam mit derselben Liga-ID und Team-ID sich nicht Überschneiden durften? Warum gab es überhaupt mehrere LigaTeams mit derselben Kombination von Liga-ID und Team-ID?
Die Lösung fand sich in der Stadtzuordnung, die wir im fachlichen Modell skizziert hatten: das System sollte imstande sein, die Historie der Stadtwechsel eines Teams abzubilden. Hierzu hatte man die existerenden "von" und "bis"-Felder verwendet, die damit eine uneinheitliche Semantik gewonnen hatten: einerseits bildeten sie den realweltlichen Umstand ab, dass Teams "inaktiv" werden konnten, andererseits waren sie missbraucht worden, um zugleich die Historie der Zuordnungen der Teams zu Städten abzubilden - und hier kam dann auch endlich die "nachfolgeLigaTeamId" ins Spiel, die wir als unlösbares Enigma hintangestellt hatten.
Durch diese Selbstassozation der "nachfolgeLigaTeamId" ließ sich gewissermaßen eine LinkedList von LigaTeams herstellen, die die Historie einer Liga-Team-Kombination abbildete.
Der realweltliche Fall, dass ein Team, das in zwei Ligen spielte, zunächst einmal die Stadt wechselte und dann inaktiv wurde, stellte sich im Modell des alten Systems wie folgt dar:
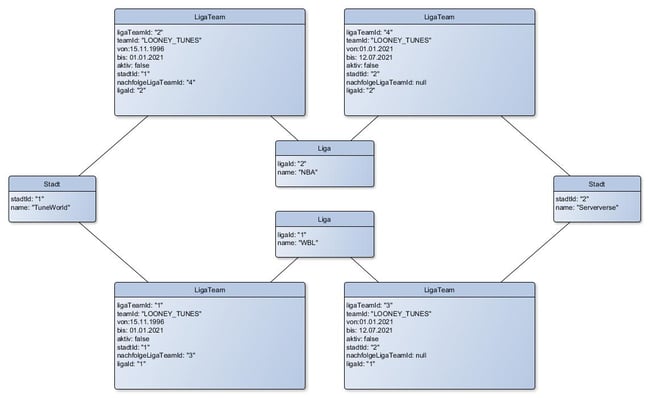
Die Komplexität des historisch gewachsenen™ Modells wird hier auf den ersten Blick ersichtlich. Dabei sind verschiedene Faktoren besonders interessant, man beachte beispielsweise, ...
- ... dass alle vier LigaTeams letztlich dasselbe Team abbilden: das Team mit Team-ID LOONEY_TUNES.
- ...dass die Eigenschaft "aktiv"=false der LigaTeams auf der linken Seite eine andere Semantik hat als die der Objekte auf der rechten Seite: links bedeutet sie, dass das Objekt eine historische Repräsentation darstellt, die nicht mehr den "aktuellen" Stand darstellt, rechts bedeutet sie, dass das Team realweltlich nicht mehr aktiv ist.
- ...dass das Flag "aktiv" im Grunde eine abgeleitete Eigenschaft darstellt, die sich daraus ergibt, ob das "bis"-Datum in der Vergangenheit liegt. Da es aber separat persistiert wurde, wurde die Anforderung "REQ-3" nötig, in der eine Stored Procedure auf der Datenbank nachträglich das "aktiv"-Flag aller LigaTeams mit ihrem "bis"-Datum abglich.
In unserem neuen Modell vereinfachte sich das obige Diagramm zu:
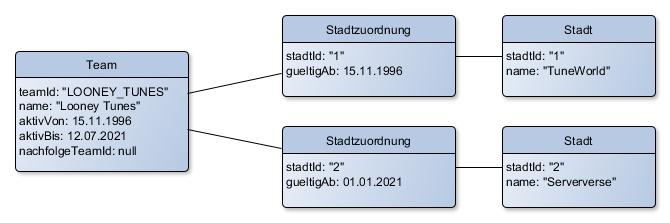
Hier wiederum fällt auf,...
- ...dass in unserem "modernen" Modell die Liga-Entität nicht einmal mehr auftaucht und
- ...dass alleine durch das Refactoring des Modells (und Migration der LigaTeams) die Anforderungen REQ-2 und REQ-3 bereits unnötig wurden, da sie reine Artefakte des historisch gewachsenen™ Modells waren.
3.4 Genealogie
Nachdem sich der Rauch verzogen hatten, wir das tatsächliche fachliche Modell erfasst und seine historisch gewachsene™ technische Gestalt eliminiert hatten, war es nicht mehr schwer, zu ermitteln, wie es eigentlich zur Existenz der LigaTeams gekommen war:
Es hatte einmal eine Entität Team gegeben. Dessen n..n-Assoziation zur Liga-Entität war in einer Intersection Table abgebildet worden:
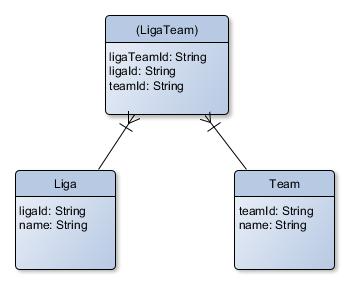
Da diese Intersection Table bereits eine ID hatte, konnte sie komfortabel selbst als eine Entität eigenen Rechts begriffen werden. Als nun die Anforderung aufkam, die historische Stadtzuordnung abzubilden, wurde diese kurzerhand in die Intersection Table eingefügt und bereits hier erschien auf einmal die realweltliche Entität Team überflüssig zu sein. Dementsprechend ergab sich das Modell:
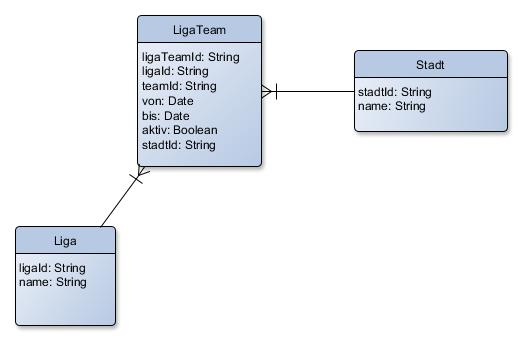
Anschließend war aufgefallen, dass Teams "inaktiv" werden konnten, dafür wurde das "von"/"bis" wiederverwendet, und von dort war es kein weiter Schritt mehr zu dem Modell, das wir am Ende vorfanden.
3.5 Implementierungshinweise
Auf Ebene der Implementierung war die Wurzel der Verwirrung also der "Missbrauch" einer Intersection Table, der daraus resultierte, dass Relationen mit Entitäten verwechselt worden waren.
Dieser Fehler lässt sich in der Praxis auf verschiedene Weisen vermeiden: Eine Möglichkeit wäre etwa, die zentrale Unterscheidung zwischen Entitäten und Relationen durch eine Konvention abzubilden. In manchen Teams gilt etwa die Regel, dass reine Intersection Tables mit einem Präfix wie "JT_" (für "Join Table") oder "IT_" (für "Intersection Table") versehen werden müssen. Dies macht die Verwechslung mit einer "echten" Entität unwahrscheinlicher.
Verwendet man JPA lässt sich die Einführung einer separaten Entität "LigaTeam" bisweilen sogar völlig vermeiden:

Aus einer implementierungstechnischen Perspektive lautet die Erkenntnis daher, dass die Tabellen auf Datenbank-Eben nicht in einer 1:1 Relation zu den Entitäten des System stehen müssen - oder zugespitzt formuliert: dass separate Primary Keys auf Intersection Tables nicht zu unterschätzenden Schaden anrichten können. Die Situation der LigaTeams lässt sich als Reifizierung einer Relation beschreiben, und diese sollte vermieden werden.
4. Fazit
Das Fazit, das sich aus dieser Übung in DDD ziehen lässt, hängt stark von der Perspektive ab.
Die zynische Perspektive lautet, dass historisch gewachsene™ Software im Grunde immer dazu tendiert, sich in merkwürdige Richtungen zu entwickeln. Das ist sicher wahr und es ist wichtig, diesen Umstand im Hinterkopf zu behalten, andererseits ist es aber auch eine äußerst unproduktive Erkenntnis. Die praktische Lehre, die sich daraus ziehen lässt, ist, vorgefundene Modelle nicht kurzerhand für bare Münze zu nehmen und auch den Anwendern nicht aufs Wort zu glauben, und zwar gerade weil IT-Systeme eine Auswirkung auf das mentale Modell der Nutzer haben können, die in ihrem Arbeitsalltag ununterbrochen mit ihnen konfrontiert sind - Conway's Law kann in beide Richtungen wirken.
Und aus einer noch philosophischeren Perspektive auf die Situation ging im Grunde alles auf eine Verwechslung von Typen zurück. Eine der wichtigsten Fragen bei der Modellierung lautet: welche Dinge gibt es in der Vorstellungswelt der Nutzer - denn Entitäten sind Dinge. Und hier ist es wichtig, korrekt zu identifizieren, welche der Namen, die die Nutzer nennen, tatsächlich Dinge bezeichnen. Dinge sind Dinge. Relationen sind es nicht. Die n..n-Relation zwischen Ligen und Teams war niemals ein Ding und hätte daher auch nicht als Entität modelliert werden sollen.
Dass sie in einer relationalen Datenbank aus technischen Gründen über eine separate Tabelle (ein Intersection Table) abgebildet werden muss, bedeutet nicht, dass sie dadurch den Status einer Entität gewinnt. Insbesondere die kategorische Verwechslung von Tabellen und Entitäten, die sich sogar in einschlägigen Artikeln bisweilen findet, kann langfristig schwerwiegende Folgen nach sich ziehen.
Für mich persönlich lautet das Fazit der Geschichte aber immer, dass es wichtig ist, nicht zu vergessen, dass Software nicht nur die Welt abbildet, sondern sogar auf sie zurückwirkt. Die Sprache der Entwickler und der Anwender werden sich mit der Zeit geradezu zwangsläufig annähern - und je mehr sich die Nutzer an die Sprache der Entwickler anpassen müssen, desto weniger haben die Entwickler verstanden, worum es eigentlich einmal ging.

Weitere Artikel










- Juni 2026
- April 2026
- Februar 2026
- Januar 2026
- Dezember 2025
- November 2025
- Oktober 2025
- August 2025
- Juli 2025
- Juni 2025
- Mai 2025
- April 2025
- März 2025
- Februar 2025
- Januar 2025
- Oktober 2024
- September 2024
- August 2024
- Juli 2024
- Juni 2024
- Mai 2024
- April 2024
- März 2024
- Februar 2024
- Januar 2024
- Dezember 2023
- November 2023
- September 2023
- August 2023
- Juli 2023
- Juni 2023
- Mai 2023
- April 2023
- Februar 2023
- Dezember 2022
- November 2022
- Mai 2022
- April 2022
- März 2022
- Januar 2022
- Dezember 2021
- November 2021
- Oktober 2021
- August 2021
- Juli 2021
- Juni 2021
- Mai 2021
- April 2021
- Dezember 2020
- Oktober 2020
- September 2020
iteratec
iteratec ist der Partner für alle, die zu den Gewinner:innen der digitalen Transformation gehören wollen. Mit individuellen, überlegenen Lösungen eröffnen wir unseren Kunden technologische wie unternehmerische Potenziale. Denn: Wenn Scheitern keine Option ist, sind wir der Partner, der den Unterschied macht. So haben wir seit 1996 mehr als 1.000 Projekte zum Erfolg geführt und eine Kundenzufriedenheit von 97%.


.jpg)






