
Cloud-native vs. Rechenzentrum
Im ultimativen Infrastrukturvergleich treten zwei unterschiedliche Plattformansätze einer Anwendungsfamilie gegeneinander an. Anhand der Prinzipien der 12-Factor App vergleichen wir eine cloud-native mit einer Rechenzentrum-basierten Infrastruktur:
-
Teil 2: Factor III: Config - Store config in the environment
-
Teil 3: Factor IV: Backing Services - Treat backing services as attached resources
- Teil 4: Factor VII: Port Binding – Export services via port binding
In dieser Runde erfahren Sie, wie sich unterstützende Dienste als angehängte Ressourcen umsetzen lassen.
Inhalt
Aussage des Faktors
Dieser Faktor besagt, dass die von der Applikation verwendeten Dienste als angebundene Ressourcen behandelt werden sollen [12F3]. Dabei spielt es keine Rolle, ob es sich um plattformspezifische oder extern angebundene Services handelt. Aus Sicht der Anwendung stellen alle Dienste also eine Blackbox dar, die über eine lose gekoppelte Schnittstelle verfügbar gemacht wird. Die Kommunikation kann dann zum Beispiel über HTTPS, ssh oder andere Netzwerkprotokolle erfolgen. Beispiele für angebundene Dienste sind Datenbanken, Messaging-Dienste oder Monitoring-Systeme. Ein großer Vorteil dieser Sichtweise liegt darin, dass wir auf globaler Architekturebene eine Trennung von Verantwortlichkeiten sicherstellen. Unsere Applikation kümmert sich um die Fachlichkeit und die angebundenen Dienste unterstützen diese, indem sie Daten zur Verfügung stellen oder Log-Events grafisch aufbereiten. Dies begünstigt zudem die Idee horizontaler statt vertikaler Skalierung. Schließlich kann sich die Applikation auf die Beantwortung von Webanfragen fokussieren und muss keine zusätzlichen Aufgaben übernehmen, die zum Beispiel im Falle von Java die JVM zusätzlich beanspruchen. Eine weitere wünschenswerte Konsequenz des Ansatzes ist, dass verschiedene Dienste schnell und leichtgewichtig getestet und bei Bedarf unkompliziert durch alternative Lösungen ersetzt werden können. Dies ist bei Architekturen, die Dienste stark an die Applikationslogik koppeln, nur schwer zu realisieren.
Die grundlegende Aussage des Faktors wird in folgender Abbildung nochmals exemplarisch dargestellt:
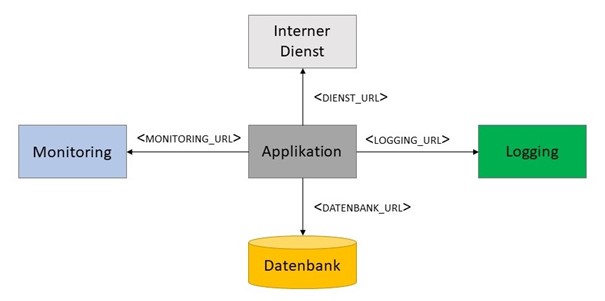
Wir sehen hier noch einmal, dass ganz verschiedene Aufgaben durch die Dienste übernommen werden können. Zur Veranschaulichung werden zum Beispiel Logging, Monitoring und Datenbank, aber auch ein intern bereitgestellter Dienst gezeigt. In Microservice-Architekturen übernimmt jeder Microservice die Rolle einer eigenständigen Applikation, die jeweils ihre benötigten Ressourcen anbindet. Dabei kann ein Microservice selbst als attached ressource agieren, wenn er von einem der anderen Microservices konsumiert wird.
Attached Ressources im Rechenzentrum
Das Prinzip wird in APP1 insbesondere bei der Umsetzung des Cachings basierend auf Hazelcast verletzt. Hazelcast ist ein Key-Value Store, der es uns erlaubt, Daten "in-memory" abzulegen und bei Bedarf abzufragen. Im Rahmen der Analyse des Faktors Config - Store config in the environment haben wir bereits erwähnt, dass APP1 auf die sogenannte embedded-topology von Hazelcast setzt. Hierbei ist Hazelcast Teil der Applikation. Es besteht daher eine starke Kopplung zwischen beiden. Starten wir den Spring Boot Applikationskontext, so wird ebenfalls ein entsprechender Hazelcast Server hochgefahren. Der Zustand des Key-Value Stores ist somit an die konkrete Spring Boot Instanz gebunden. Außerdem müssen wir sicherstellen, dass wir genügend Ressourcen bereitstellen, um Applikationslogik und Hazelcast in einer gemeinsamen Anwendung auszuführen. Reichen die Ressourcen der JVM nicht aus, so müssen wir vertikal, statt wie von der 12-Factor App bevorzugt, horizontal skalieren.
Nachdem APP1 auf zwei produktiven Servern läuft, muss des Weiteren sichergestellt werden, dass die aus Hazelcast bezogenen Daten auf jedem der Server aktuell sind. Ändert ein Benutzer auf einem der Server Daten, die von Hazelcast zwischengespeichert werden, so muss auch die zweite Instanz informiert und aktualisiert werden. Hazelcast stellt hierzu diverse Mechanismen bereit, die über Konfigurationen im Code umgesetzt werden können. Die von uns verwendete TCP/IP Variante haben wir bei der Diskussion des Config-Faktors bereits genauer analysiert.
Ein weiterer Aspekt von APP1, der aufzeigt, wie schnell das Prinzip verletzt werden kann, stellt das Logging dar. Nachdem wir hierzu noch einen dedizierten Beitrag haben, wollen wir nur die Essenz des Problems im Hinblick auf den hier diskutierten Faktor erläutern. Im Rechenzentrum werden Logs häufig, so auch im Falle von APP1, in Dateien geschrieben und auf dem Server abgelegt. Es besteht somit eine Kopplung zwischen der Applikation und der Ablage der Logs im Filesystem. Die Untersuchung der Logs erfordert somit zum Beispiel, dass wir händisch Dateien von allen Servern herunterladen und dann manuell analysieren.
Attached Ressources in der Cloud
In APP2 sieht die Welt anders aus. Praktisch per Definition stellt Cloud Foundry Dienste über den bind-service Befehl als attached resources bereit. Aus Anwendungssicht überlegt man sich also, welche Dienste benutzt werden sollen und erzeugt und bindet diese mittels Kommandozeile. In der Praxis wird die Auswahl von Faktoren wie Kosten, Stabilität, aber auch Unternehmensrichtlinien eingeschränkt. Dies gilt es beim Aufbau der Infrastruktur in der Cloud stets im Auge zu behalten. In APP2 hat dies zum Beispiel zu folgender Architektur geführt (es sind in Gelb auch unterstützende Dienste wie SSH-Proxy gezeigt, die zwar nicht an die Anwendung angebunden sind, aber für den Betrieb relevant sind):
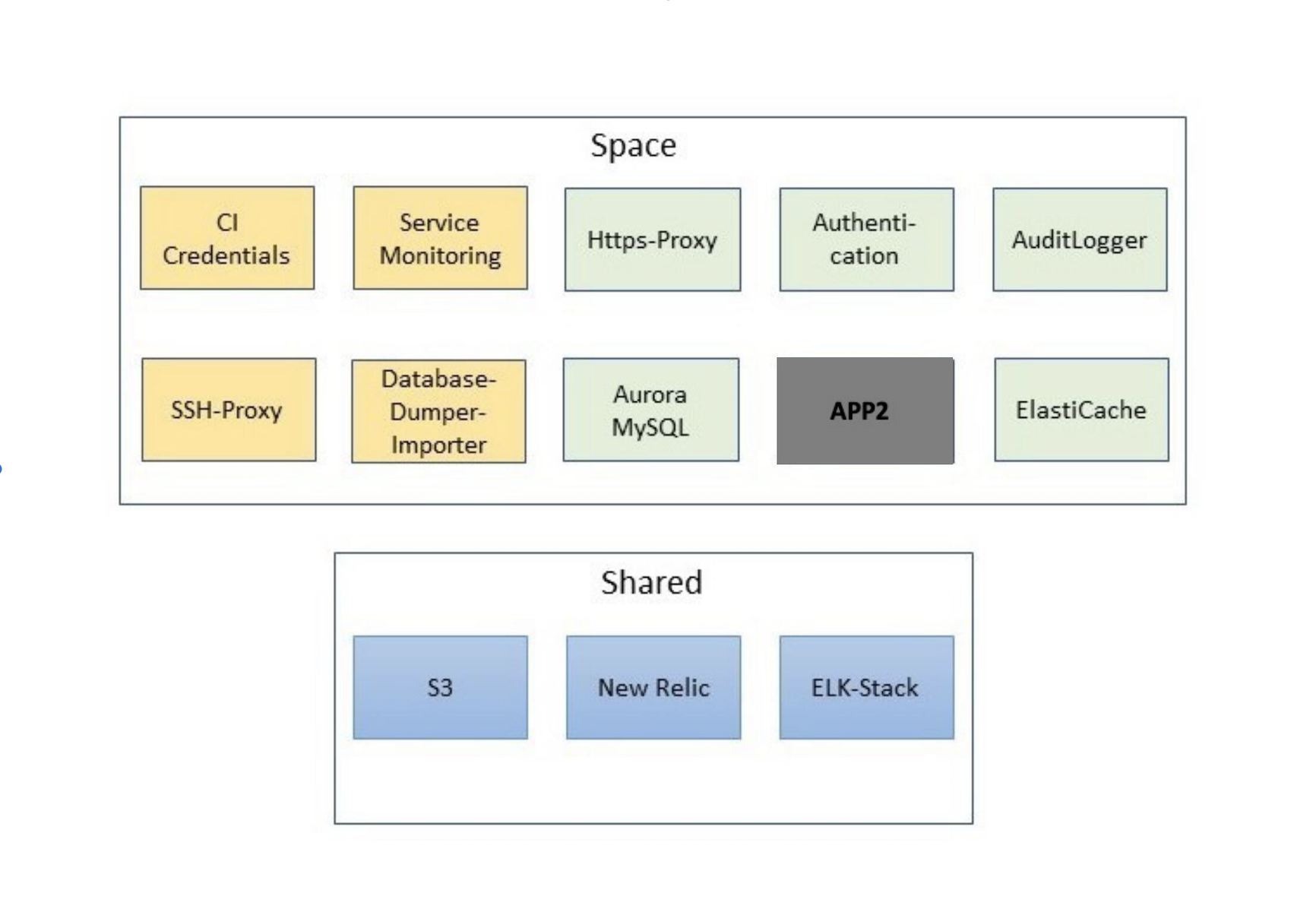 Hierbei wurde zur Bewahrung der Übersichtlichkeit darauf verzichtet, Bindings der Dienste an APP2 explizit einzuzeichnen. Stattdessen repräsentieren die in der Abbildung grün und blau markierten Komponenten Dienste, die an APP2 gebunden sind. Das Diagramm zeigt zudem, dass die von APP2 konsumierten Services in unterschiedliche Kategorien einzuteilen sind. Hier gibt es von der Plattform bereitgestellte Dienste pro Space und übergreifende Shared Services. Letztere zeichnen sich dadurch aus, dass ein Dienst erzeugt wird, der an die Anwendung eines jeden Spaces gebunden werden kann (In unserem Kontext lässt sich ein Space im Wesentlichen mit einer Stage identifizieren). Dies steht im Gegensatz zu den Space-spezifischen Diensten. Diese werden pro Space erzeugt und an APP2 gebunden. Aus Sicht unserer Applikation ist diese Unterteilung aber irrelevant, da alle verwendeten Ressourcen Black Boxes sind, die über das Netzwerk erreichbar sind. In der folgenden Diskussion wollen wir einige der verwendeten Dienste näher betrachten.
Hierbei wurde zur Bewahrung der Übersichtlichkeit darauf verzichtet, Bindings der Dienste an APP2 explizit einzuzeichnen. Stattdessen repräsentieren die in der Abbildung grün und blau markierten Komponenten Dienste, die an APP2 gebunden sind. Das Diagramm zeigt zudem, dass die von APP2 konsumierten Services in unterschiedliche Kategorien einzuteilen sind. Hier gibt es von der Plattform bereitgestellte Dienste pro Space und übergreifende Shared Services. Letztere zeichnen sich dadurch aus, dass ein Dienst erzeugt wird, der an die Anwendung eines jeden Spaces gebunden werden kann (In unserem Kontext lässt sich ein Space im Wesentlichen mit einer Stage identifizieren). Dies steht im Gegensatz zu den Space-spezifischen Diensten. Diese werden pro Space erzeugt und an APP2 gebunden. Aus Sicht unserer Applikation ist diese Unterteilung aber irrelevant, da alle verwendeten Ressourcen Black Boxes sind, die über das Netzwerk erreichbar sind. In der folgenden Diskussion wollen wir einige der verwendeten Dienste näher betrachten.
Datenbank
Die Datenbank ist hierbei ein instruktives Beispiel. Zum einen benötigt nahezu jede Anwendung eine Datenbank. Zum anderen können wir hier aufzeigen, dass der Betrieb in der Cloud einige architektonische Überlegungen und Anstrengungen mit sich bringen kann.
In APP2 wird auf eine MySQL-kompatible Variante von Aurora (im Folgenden als mysql bezeichnet) als Datenbank gesetzt. Für die Bereitstellung von Datenbank-Dumps gibt es zudem eine dedizierte Mini-Anwendung - in der Abbildung als database-dumper-importer bezeichnet - auf die wir im späteren Verlauf noch zu sprechen kommen werden.
Bei der Erzeugung und Anbindung der Datenbank müssen wir für einen gegebenen Space die folgenden Befehle ausführen:
cf create-service aws_aurora <PLAN_NAME> mysql -c <CONFIG>
cf bind-service <APP_NAME> mysql
Hier definiert PLAN_NAME Ressourcen wie Arbeitsspeicher, die der Datenbank zur Verfügung stehen. Eine Auflistung möglicher Pläne kann der Dokumentation des entsprechenden Dienstes im Cloud Foundry Marketplace entnommen werden. CONFIG steht für optionale Konfigurationen (wie etwa Wahl des Encodings) und <APP_NAME> ist der Name der Applikation, an die wir die Datenbank binden wollen. Dies reicht bereits aus, um über unsere Anwendung eine Verbindung mit der Datenbank herzustellen. Im Rahmen einer Spring Boot Applikation ist es nicht nötig, explizit datasource Information in application.yml zu setzen. Cloud Foundry weiß, dass es sich um eine Spring Boot Anwendung handelt und setzt die nötigen Parameter automatisch in einer Umgebungsvariable, welche bei der Erzeugung der Datenbank automatisch generiert wird. Diese Variable kann explizit über cf env <APP_NAME> abgerufen werden. Das folgende Listing zeigt den entsprechenden Auszug:
{
"VCAP_SERVICES": {
"aws_aurora": [
{
"credentials": {
"jdbcUrl": "jdbc:mysql://<HOST_NAME>:<PORT>/<DB_NAME>?user=<USERNAME>&password=<PASSWORT>&characterEncoding=<ENCODING>"
}
}
]
}
}
Ohne nähere Spezifikationen werden die Platzhalter im Auszug durch Werte ersetzt, die automatisch von Cloud Foundry gesetzt werden.
Da für den Betrieb der Datenbank in produktiven Systemen zusätzliche Verbindungen wie ssh-Tunnel benötigt werden, werden hierfür durch Cloud Foundry noch weitere Umgebungsvariablen bereitgestellt, die über
cf service-key mysql <KEY_NAME>
erzeugt werden. Diese sind nun ebenfalls über cf env <APP_NAME> einsehbar.
Wie weiter oben bereits angekündigt, wollen wir nun auf die Bedeutung des database-dumper-importers eingehen. Tatsächlich besteht unser Ökosystem an Applikationen pro Space nicht nur aus APP2. So hat sich während der Entwicklung gezeigt, dass für den produktiven Betrieb von APP2 eine zusätzliche Mini-Anwendung - der database-dumper-importer - sinnvoll ist. Diese Anwendung kennt keine Fachlogik, sondern ist einzig für die Bereitstellung von Datenbank-Dumps verantwortlich. Daher muss diese Applikation alle dafür relevanten Dienste, wie mysql, aber auch einen S3 Bucket binden, wie wir im Folgenden noch genauer erklären werden. Die Anwendungen APP2 und database-dumper-importer brauchen sich hierzu nicht gegenseitig kennen, es ist also kein Binding untereinander nötig.
Um die Notwendigkeit der Mini-Anwendung zu verstehen, wollen wir zuerst mögliche Alternativen aufzeigen und erklären, warum wir diese verworfen haben. Die auf der Hand liegende Option auf die von AWS bereitgestellte Funktion zur Bereitstellung von Dumps zurückzugreifen, konnte aufgrund fehlender Rechte nicht verwendet werden. Es musste also nach einer Alternative gesucht werden.
Eine erste Überlegung war es zur Erzeugung und zum Import von Datenbank-Dumps entsprechende REST Endpunkte innerhalb der Anwendung anzubieten. In dieser Variante wird ein Datenbank-Export zum Beispiel mittels eines Button-Clicks aus der Anwendung heraus initiiert. Ein grundlegendes Problem dieser Variante ist aber, dass aufgrund der starken Kopplung von Anwendung und Datenbankbetrieb, die Konsistenz der Daten schwierig zu gewährleisten ist. Während des laufenden Betriebs ändern Benutzer Daten. Ein Wartungsmodus wäre also zwingend notwendig. Nachdem Exports aber flexibel und regelmäßig stattfinden sollen, wären diese effektiven Downtimes für den Benutzer nicht zumutbar. Somit ist diese Option nicht möglich.
In einem nächsten Schritt haben wir uns überlegt, statt eines REST Endpunktes eine Verbindung über ssh herzustellen. Cloud Foundry ermöglicht es einer Anwendung, als Host für einen ssh Tunnel zu agieren [CF2]. Die Idee wäre dann, sich über die Anwendung mittels ssh mit der remote Datenbank zu verbinden und dann in einer single transaction einen konsistenten Snapshot der Datenbank zu erstellen. Allerdings gibt es hier Restriktionen seitens der von uns verwendeten Plattform. Aus Sicherheitsgründen ist für Anwendungen per default ssh disabled. Nun können wir über cf enable-ssh <APP_NAME> ssh enablen und erst dann die Anwendung starten. Das Problem ist aber, dass die Plattform ssh alle 60 Minuten automatisch wieder disabled. Soll also nach mehr als einer Stunde ein Export gestartet werden, so ist dies erst nach explizitem enablen wieder möglich. Dabei muss aber auch die Anwendung neu gestartet werden. Theoretisch kann dabei eine Downtime mithilfe eines green-blue oder rolling deployments vermieden werden [CF3, CF4]. Wir sollten uns allerdings die Frage stellen, inwieweit wir unsere Anwendung und deren Betrieb anpassen möchten, um eine Aufgabe zu lösen, die nicht der eigentlichen Anwendungslogik und Fachlichkeit entspringt. Wir würden mit dem Ansatz Konzepte koppeln, die getrennt sein sollen. Dies ist weder vom Standpunkt generischer Prinzipien des Software-Designs noch aus Sicht der 12-Factor App wünschenswert.
Eine möglichst flexible und robuste Lösung für dieses Problem, die zusätzlich die Datenkonsistenz beim Erstellen eines Dumps garantiert, war schließlich die Erstellung einer eigenen Mini-Anwendung (database-dumper-importer) pro Space. Die Idee lässt sich wie folgt zusammenfassen: Der database-dumper-importer soll in der Lage sein, sich mit der Datenbank über ssh zu verbinden, einen Dump mittels mysqldump zu erstellen und diesen dann in einem S3-Bucket abzulegen. Von dort aus kann dann bei Bedarf ebenfalls über den Dumper ein Import stattfinden. Nachdem ein solches Vorgehen typischerweise verschiedene Stages involviert, wird der Bucket als Shared Service eingebunden.
Da der Dumper in der Lage sein muss, Cloud Foundry-, MySQL- und AWS-Befehle auszuführen, bietet es sich zudem an, die Anwendung als Docker Container zu deployen. Die Verwaltung des Docker Images erfolgt über die Elastic Container Registry (ECR) von AWS. Zusätzlich müssen S3 und MySQL als Dienste an unsere Mini-Applikation angebunden werden. Da der Dumper nur zum Zweck der Kommunikation mit der Datenbank und zum Hochladen eines Dumps in einen Bucket existiert, sollte er nur bei Bedarf gestartet und mit minimalem Arbeitsspeicher (128MB) ausgestattet werden. Außerdem besteht kein Bedarf, den Dumper über einen Endpunkt zu erreichen. Folglich wird keine Route benötigt. Die Erstellung einer solchen Anwendung könnte schematisch wie folgt aussehen (einige Optionen wurden hier ausgelassen):
cf push <APP_NAME> \
-m 128M \
--no-route \
--no-start \
--docker-image "${ECR_URI}" \
--docker-username "${ECR_ACCESS_KEY}" \
cf bind-service <APP_NAME> <DB_NAME>
cf bind-service <APP_NAME> <S3_NAME>
cf enable-ssh <APP_NAME>
wobei <APP_NAME>, <DB_NAME> und <S3_NAME> die Namen unserer Mini-Anwendung, der Datenbank und des S3-Buckets repräsentieren und ECR_URI und ECR_ACCESS_KEY Umgebungsvariablen sind, die bei Erstellung der Registry angelegt werden und deren Zugang ermöglichen.
Caching & Logging
Um einen Kontrast zur oben beschriebenen Situation hinsichtlich Caching und Logging in APP1 aufzuzeigen, wollen wir einen Blick auf die entsprechende Umsetzung in APP2 werfen. Hier werden AWS ElasticCache Redis bzw. eine Umsetzung des ELK-Stacks eingebunden. Im Falle von Redis haben wir einen von unserer Applikation unabhängigen Dienst. Folglich müssen die Container, die APP2 ausführen, keinen Arbeitsspeicher für das Caching bereitstellen. Stattdessen ist Redis von allen Instanzen unserer Anwendung anhand einer spezifischen URL erreichbar (mehr Details hierzu findet der Leser in unserem letzten Beitrag zum Faktor Config). Die Datenkonsistenz über alle Instanzen ist folglich automatisch gewährleistet und muss nicht mehr in Form von Konfigurationen von Discovery Mechanismen oder Ähnlichem sichergestellt werden. Ähnliches gilt für das Logging. Die geschriebenen Logs werden als Events verarbeitet und aggregiert. Kibana liefert uns die gesammelte Information aller Server.
Austausch von Diensten
Auch wenn wir in APP2 noch keinen der eingebundenen Dienste durch Alternativen ersetzt haben, lohnt es sich kurz zu illustrieren, wie dies gemacht werden kann. Über den Befehl cf unbind-service <APP_NAME> <SERVICE_NAME> kann die Bindung des Services an die Anwendung gelöst werden. Wurde der neue Dienst mithilfe der create und bind-service Anweisungen an die Applikation angebunden und Code-seitig die nötigen Konfigurationen und Bean-Deklarationen ersetzt, so kann der nicht mehr benötigte Dienst (inklusive service-keys) über
cf delete-service-key <SERVICE_NAME> <KEY_NAME>
cf delete-service <SERVICE_NAME>
gelöscht werden. Diese simplen Schritte können selbstständig durch das Entwicklungsteam abgearbeitet werden. Im Gegensatz dazu ist die Ersetzung von verwendeter Software im Rechenzentrum oft mit Bereitstellung neuer Server und dem expliziten Management der Dienste durch den Betrieb verknüpft.
Offene Punkte
Zum Abschluss unserer Diskussion wollen wir noch darauf aufmerksam machen, dass APP2 Frontend und Backend gemeinsam als eine ausführbare .jar-Datei ausliefert. Nachdem wir darauf im Rahmen des Beitrags zum Faktor Port Binding genauer eingehen werden, wollen wir an dieser Stelle darauf aufmerksam machen, dass dieses Vorgehen aus Sicht der Backing Services als problematisch betrachtet werden kann. Wir könnten den Angular Client als eine eigenständige Applikation deployen, die das Spring Boot Backend als attached ressource konsumiert. Letztere ist selbst wiederum als Applikation zu betrachten und bindet als solche die Dienste aus oben gezeigtem Architekturdiagramm ein. Obwohl dies definitiv ein valider Punkt ist, war es für die Entwicklung und den Betrieb von APP2 bisher keine zwingende Notwendigkeit eine solche Aufteilung vorzunehmen. Ändern sich die Anforderungen, sodass zum Beispiel eine Aufteilung des Backends in einzelne Microservices notwendig wird, wäre auch die Abspaltung des Frontends in eine eigenständige Applikation zu bevorzugen.
Fazit
Adaptieren wir den Ansatz, Dienste als lose gekoppelte Ressourcen zu betrachten, die von unserer Applikation konsumiert werden, so ergeben sich diverse Vorteile, die nicht nur auf die Cloud beschränkt sind. Zwar bietet die Cloud den perfekten Rahmen, um diese Sichtweise optimal ausnützen zu können. Allerdings würde die Umsetzung des Backing Services Faktors auch im Rechenzentrum viele Vorteile bieten. Insbesondere haben wir gesehen, dass die Datensynchronisation oder Analyse der Logs deutlich vereinfacht würde. Eine entsprechende Umsetzung ist grundsätzlich auch im Rechenzentrum denkbar. Dazu ist aber in der Regel die Beschaffung und Konfiguration von neuer Infrastruktur notwendig. Dies kostet Zeit und Geld und ist alles andere als leichtgewichtig. Zusätzlich sieht der Prozess im Rechenzentrum nicht vor, dass das Entwicklungsteam Konfigurationen der Dienste selbstständig anpassen kann. Vielmehr muss dies an den Betrieb kommuniziert und von diesem übernommen werden. Dies führt dazu, dass Änderungen, die technisch schnell umgesetzt werden können, erst mit einigem Verzug tatsächlich bereitstehen.
Dennoch lohnt es sich auf Dauer trotzdem für die Idee der Backing Services zu argumentieren und einzutreten. Tatsächlich wurden im Bereich des Loggings auch schon viele Schritte in diese Richtung unternommen. Dazu werden wir noch mehr in einem weiteren Beitrag der Reihe zu sagen haben. Durch die eingeschränkte Flexibilität im Hinblick auf Infrastruktur ist aber nicht anzunehmen, dass im Rechenzentrum schnell und nach Bedarf Dienste getestet und ausgetauscht werden können. Dieser Vorteil scheint exklusiv der Cloud vorenthalten zu sein.
Noch Fragen?
Weiter Informationen und Hilfestellungen rund um die Gestaltung und Weiterentwicklung hochperformanter IT-Infrastrukturen und Applikationslandschaften finden Sie unter:
Referenzen:
[12F3]: THE TWELVE-FACTOR-APP - IV. Backing services, siehe: https://12factor.net/backing-services
[CF2]: Accessing Services with SSH, siehe: https://docs.cloudfoundry.org/devguide/deploy-apps/ssh-services.html
[CF3]: Rolling App Deployments, siehe: https://docs.cloudfoundry.org/devguide/deploy-apps/rolling-deploy.html
[CF4]: Using Blue-Green Deployment to Reduce Downtime and Risk, siehe: https://docs.cloudfoundry.org/devguide/deploy-apps/blue-green.html
Weitere Artikel










- Juni 2026
- April 2026
- Februar 2026
- Januar 2026
- Dezember 2025
- November 2025
- Oktober 2025
- August 2025
- Juli 2025
- Juni 2025
- Mai 2025
- April 2025
- März 2025
- Februar 2025
- Januar 2025
- Oktober 2024
- September 2024
- August 2024
- Juli 2024
- Juni 2024
- Mai 2024
- April 2024
- März 2024
- Februar 2024
- Januar 2024
- Dezember 2023
- November 2023
- September 2023
- August 2023
- Juli 2023
- Juni 2023
- Mai 2023
- April 2023
- Februar 2023
- Dezember 2022
- November 2022
- Mai 2022
- April 2022
- März 2022
- Januar 2022
- Dezember 2021
- November 2021
- Oktober 2021
- August 2021
- Juli 2021
- Juni 2021
- Mai 2021
- April 2021
- Dezember 2020
- Oktober 2020
- September 2020
iteratec
iteratec ist der Partner für alle, die zu den Gewinner:innen der digitalen Transformation gehören wollen. Mit individuellen, überlegenen Lösungen eröffnen wir unseren Kunden technologische wie unternehmerische Potenziale. Denn: Wenn Scheitern keine Option ist, sind wir der Partner, der den Unterschied macht. So haben wir seit 1996 mehr als 1.000 Projekte zum Erfolg geführt und eine Kundenzufriedenheit von 97%.







