
Formula Student Competition 2018 mit iteratec und municHMotorsport
Willkommen zum zweiten Teil der Formula-Student-Blogreihe!
Diese Blogreihe ist für alle, die schon immer einen Blick hinter die Kulissen eines selbstständig organisierten studentischen Projekts werfen wollten, bei dem ein Rennfahrzeug im sechsstelligen Bereich ohne jegliche Beaufsichtigung gebaut wird. Und dieses Fahrzeug auch noch autonom auf einer Rennstrecke mit 65km/h navigiert!
Diese Blogreihe rund um die Formula Student Competition 2018 mit municHMotorsport besteht aus drei Teilen:
- Teil 1: Was ist Formula Student Driverless und Anforderungsanalysen?
- Teil 2: Umfelderkennung mit Darknet YOLO
- Teil 3: Modellbasierte Trajektorienplanung
In diesem Blog-Post soll es speziell um die Umfelderkennung gehen. Zudem soll es euch ermöglicht werden, mit relativ geringem Aufwand unser System zu Hause nachzumachen und mit euren eigenen Daten zu testen. Hier kommt uns der minimalistische Ansatz wieder zu Gute, da lediglich eine Webcam und ein Laptop nötig sind. Für Real-time Performance ist zudem eine Grafikkarte nötig - GTX 1050 oder vergleichbar.
Inhalt
- System
- Umfelderkennung
- Training
- Distanzschätzung
- Tracking
- Lucas-Kanade-Methode
- Putting it all together
- Ausblick
System
Wichtig ist erstmal, uns mit der Software Pipeline des Gesamtsystems auszukennen. Bei der Umfelderkennung befinden wir uns ganz am Anfang und sitzen genau an der Schnittstelle zwischen unserer Sensorik und der Software. Hierbei gilt es, die Bilder aus unserem Kamerasystem möglichst schnell und effizient auf unserer Recheneinheit zu verarbeiten. Ziel dieser Verarbeitung ist es, Objekte auf den Farbbildern zu lokalisieren, zu klassifizieren und anschließend ihre Position bezüglich der Kamera zu schätzen.
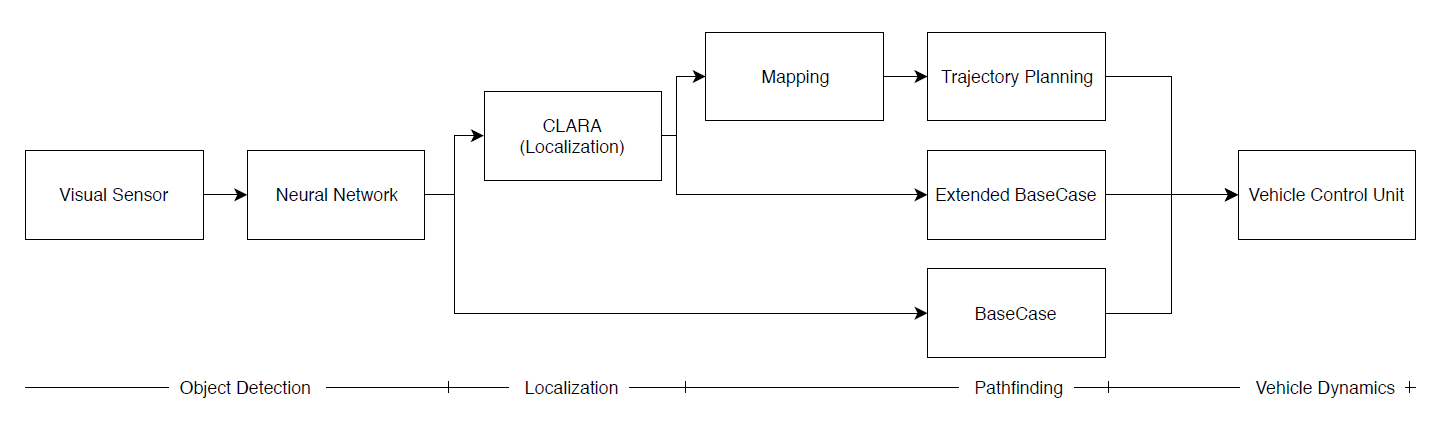
Softwaresystem-Diagramm
Umfeldmodell
Die Rennstrecke wird von uns als 2D-Koordinatensystem abgebildet. In unserem Falle sind nur vier unterschiedliche Hindernisse möglich, deren genaue Abmaße uns bekannt sind. Der Ursprung ist im Falle des Kamerasystems die Kamera, für das gesamte System liegt dieser jedoch auf dem Center of Gravity - also den Massenschwerpunkt - des Fahrzeuges, lediglich mit der X-Achse in Längsrichtung und Y-Achse in Querrichtung.
Die Koordinaten der erkannten Objekte werden in Polarkoordinaten gespeichert, damit sie später verarbeitet und in eine lokale Karte eingefügt werden können.
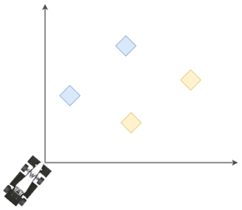 Die Vereinfachung auf zwei Dimensionen erlaubt es uns, diverse Algorithmen leichter und effizienter zu gestalten. Da die meisten Strecken, auf denen wir fahren, keine starken Gefälle vorzeigen, führt dieses vereinfachte Modell auch nicht zu großen Fehlern.
Die Vereinfachung auf zwei Dimensionen erlaubt es uns, diverse Algorithmen leichter und effizienter zu gestalten. Da die meisten Strecken, auf denen wir fahren, keine starken Gefälle vorzeigen, führt dieses vereinfachte Modell auch nicht zu großen Fehlern.
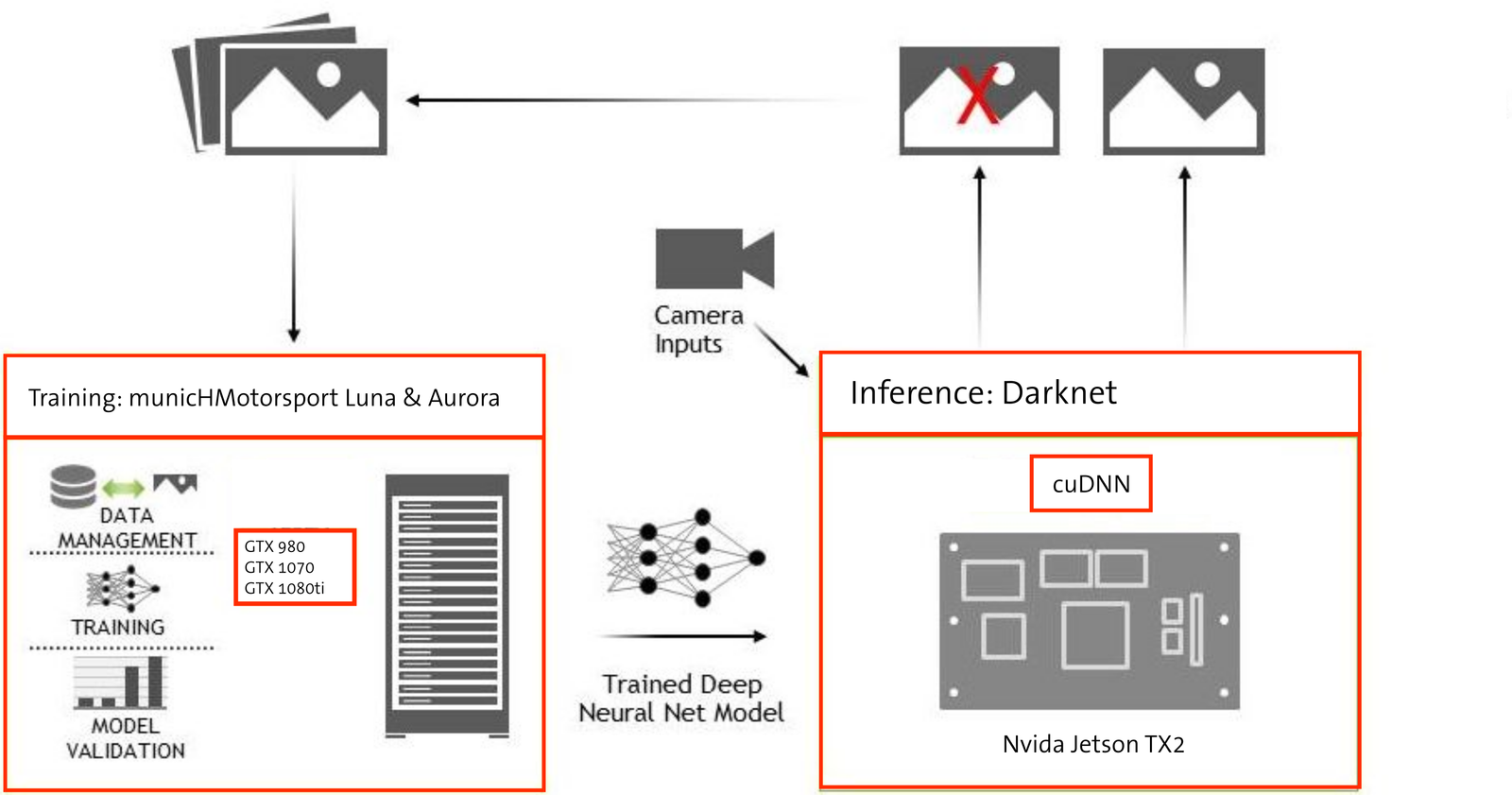
municHMotorsport Deep Learning Pipeline
Alternative-Deep-Learning-Objekterkennung
Für die Aufgabe, auf Farbbildern Objekte zu erkennen und zu klassifizieren, gibt es mehrere Algorithmen und neuronale Netze, die benutzt werden können. Zusätzlich dazu gibt es natürlich noch herkömmliche Methoden der Bildverarbeitung, die in Frage kommen.
 Alternative Deep-Learning-Ansätze (DL), die wie Darknet YOLO auch in Echtzeit laufen könnten, waren zum Zeitpunkt unserer Entscheidung zum Design der Objekterkennung SSD und Faster R-CNN. Letzteres ist leider trotzdem zu langsam für unsere Anwendung, obwohl durch die Trennung der Lokalisierung und Klassifizierung auf zwei gekoppelte neuronale Netze eine höhere Genauigkeit erzielt wird.
Alternative Deep-Learning-Ansätze (DL), die wie Darknet YOLO auch in Echtzeit laufen könnten, waren zum Zeitpunkt unserer Entscheidung zum Design der Objekterkennung SSD und Faster R-CNN. Letzteres ist leider trotzdem zu langsam für unsere Anwendung, obwohl durch die Trennung der Lokalisierung und Klassifizierung auf zwei gekoppelte neuronale Netze eine höhere Genauigkeit erzielt wird.
SSD hingegen erweist eine ähnliche Genauigkeit wie YOLO bei erheblich niedriger Geschwindigkeit, wodurch es auch ausschied. Würde es nicht auf einem speziellen Branch von Caffe basieren, wäre die Nutzung von TensorRT möglich gewesen, um unter Umständen sogar schneller zu sein als YOLO.
Faster R-CNN
Die Entscheidung gegen herkömmliche Methoden ergab sich aus dem Grund, dass wir ein Objekterkennungsmodul entwerfen wollten, das möglichst robust gegenüber unterschiedlichen Wetter- und Witterungsbedingungen sein sollte. Mittels Supervised Learning ist es ausreichend, die Trainingsdatensätze bei unterschiedlichen Bedingungen aufzunehmen. Mit Data Augmentation können diese zudem programmatisch angereichert werden. Insgesamt können wir dadurch Zeit und Ressourcen sparen, die bei herkömmlichen Methoden wie Kantenerkennung in spezielle Farbfilter einfließen müssten. Zudem funktionieren diese nur bei bestimmten Bedingungen gut und nur Spezialisten können sie anpassen. Neue Bilder aufnehmen und in den Trainingsdatensatz einpflegen, ist wesentlich einfacher und kann teamübergreifend erledigt werden.
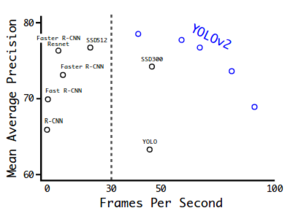
Imagenet mAP vs FPS
You Only Look Once (YOLO): Unified, Real-time Object Detection
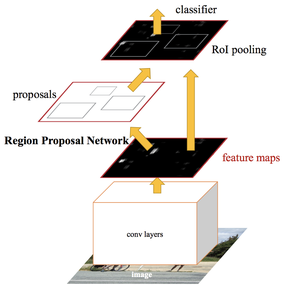
 Bei YOLO wird basierend auf dem Output von einem Feature-Extractor-Netzwerk sowohl eine Klassifizierung über eine Softmax-Funktion, als auch eine multinomiale logistische Regression für die jeweilige Bounding Box durchgeführt. Beides passiert im sogenannten Region-(YOLOv2) oder YOLO-Layer (YOLOv3).
Bei YOLO wird basierend auf dem Output von einem Feature-Extractor-Netzwerk sowohl eine Klassifizierung über eine Softmax-Funktion, als auch eine multinomiale logistische Regression für die jeweilige Bounding Box durchgeführt. Beides passiert im sogenannten Region-(YOLOv2) oder YOLO-Layer (YOLOv3).
Die Erkennnung von Objekten bei beiden Ausführungen des YOLO-Algorithmus basieren auf der Feature Map, die vom Feature-Extractor-Netzwerk ausgegeben wird.
YOLO Layer
Erwartet wird ein Input in Form M x N x D
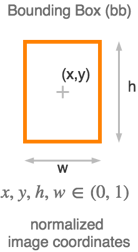
Mit M und N wird der Grid bestimmt, auf dem die Erkennung durchgeführt wird. Auf der Grafik sieht man den Fall, in dem M = N = 19 gilt. Für jedes Kästchen im M x N Grid werden die Koordinaten - bx, by, bh, bw - von genau einer Bounding Box für jeden Dimension Prior berechnet, die Wahrscheinlichkeit, dass diese Bounding Box ein Objekt ist obj und für jede mögliche Klasse eine zugehörige Wahrscheinlichkeit cn.
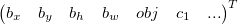
Erkennungsvektor
Dimension Priors sind Rechtecke, die als Basis für die Bounding-Box-Regression dienen. Für bessere Ergebnisse beim Trainieren können diese auf die eigenen Daten mittels K-means clustering angepasst werden.
Die Form des Outputs des Feature Extractors kann anhand der Anzahl an Dimension Priors und unterschiedlichen Klassen berechnet werden: D = priors * (classes + 5)
Hier sollen einige dieser Werte an einer der Config-Dateien der YOLOv2 Architektur veranschaulicht werden:
#yolov2-voc.cfg
...
[convolutional]
size=1
stride=1
pad=1
# D = 5 * (20 + 5)
# D = 125
filters=125
activation=linear
[region]
# Dimension Priors: x_unten_links, y_oben_rechts
# In diesem Fall 5 Dimension Priors
anchors = 1.3221, 1.73145, 3.19275, 4.00944, 5.05587, 8.09892, 9.47112, 4.84053, 11.2364, 10.0071
bias_match=1
# Anzahl an Klassen
classes=20
# Anzahl an Koordinaten, die vorhergesagt werden
coords=4
# Anzahl an Dimension Priors, siehe anchors
num=5
softmax=1
jitter=.3
rescore=1
# Parameter für die Gewichtung der Loss Function: https://pjreddie.com/media/files/papers/YOLO9000.pdf
object_scale=5
noobject_scale=1
class_scale=1
coord_scale=1
absolute=1
# Ab diesem obj-Wert wird die entsprechende Erkennung beim Training nicht für die Berechnung der Loss Function benutzt
# Dient zur Stabilisierung des Trainings, limitiert aber auch die maximale Genauigkeit der Bounding Boxes
thresh =.6
random=1
Dimension Priors
Training
Datensätze
| Name | Anteil von gesamten Datensatz | Bestandteile | Zweck |
|---|---|---|---|
| Train | 90% | Handlich annotierte Bilder, synthetische Bilder und erweiterte Bilder | Trainieren der Modelle. |
| Dev | 5% | Handlich annotierte Bilder | Überprüfung der aufgestellten Evaluationsmetriken, um Modelle zwischen Iterationen anzupassen. |
| Valid | 5% | Handlich annotierte Bilder | Validierung der Modelle. Überpfrüfung, dass nicht auf Train und Dev overfitted wurde. Kommt aus derselben Verteilung wie Dev. |
 Mit dem Unity Cone Simulator konnten wir innerhalb kürzester Zeit und plattformübergreifend dynamische Szenen erstellen, zu denen wir automatisch Bild- und Label-Paare generieren konnten.
Mit dem Unity Cone Simulator konnten wir innerhalb kürzester Zeit und plattformübergreifend dynamische Szenen erstellen, zu denen wir automatisch Bild- und Label-Paare generieren konnten.
Der Validierungsdatensatz wird während der Entwicklung der Modelle nicht benutzt. Zudem sollten Entwicklungs- und Validierungsdatensätze aus derselben Verteilung kommen, sodass verlässliche Ergebnisse erzielt werden können.
Die Rahmenbedingungen, zu denen unsere Objekterkennung zum Einsatz kommen würde, waren von Anfang an klar: Farbige Pylonen auf grauer Asphaltstrecke.
Einige relevante Einflussgrößen konnten wir aber nicht vorhersagen, zum Beispiel:
- Wetterbedingungen
- Lichtbedingungen
- Rennstreckenbedingungen (Schlaglöcher, Unebenheiten, Höhenprofil)
- Hintergrund der Strecken (Zuschauertribünen, kleine orange Pylonen)
Unser Trainingsdatensatz besteht aus Pylonenbildern vor unterschiedlichen Hintergründen und Umgebungen. Wie auf dem aus einer Stichprobe des Trainingsdatensatzes bestehenden Mosaikbildes erkenntlich, haben wir bei der Erhebung der Daten darauf geachtet, dass eine möglichst große Variation an Bedingungen zutraf. Zudem haben wir noch rund 3000 Bilder aus dem KITTI Datensatz benutzt, um genügend Bilder ohne Pylonen im Datensatz zu haben. Das ist vor allem dann wichtig, wenn man die Wahrscheinlichkeit möglichst gering halten will, dass ein Modell overfitted ist.

Ausschnitt unseres Datensatzes von über 6000 Bilder
 Zusätzlich zur Datenerhebung mit unserem Stativwagen - dieser ist ideal, um die Position der Kamera anzupassen und bei der Validierung der Objekterkennung außerhalb des Autos ähnliche Rahmenbedingungen zu haben - half uns eine Kooperation mit anderen Formula Student Teams, unseren Datensatz zu vergrößern. Mit dem norwegischen FS Team der NTNU aus Trondheim, revolve, wurden über 1000 Bilder im Rahmen eines 1:1 Tauschs gewonnen.
Zusätzlich zur Datenerhebung mit unserem Stativwagen - dieser ist ideal, um die Position der Kamera anzupassen und bei der Validierung der Objekterkennung außerhalb des Autos ähnliche Rahmenbedingungen zu haben - half uns eine Kooperation mit anderen Formula Student Teams, unseren Datensatz zu vergrößern. Mit dem norwegischen FS Team der NTNU aus Trondheim, revolve, wurden über 1000 Bilder im Rahmen eines 1:1 Tauschs gewonnen.
Stativwagen
Trainingsablauf
1. Festlegung von Fehlermetriken und Zielwerten
2. Funktionierende End-to-End Pipeline aufbauen
3. System in hauptsächlich abgekapselte Komponenten aufteilen, um eine iterative Analyse durchzuführen
1. Datenerhebung und Annotierung
2. Hyperparameter anpassen
Evaluationsmetriken
Notwendige Bedingungen:
- Frames per Second (FPS)>= 10Hz Als einziger Sensor zur Aufnahme von Umfelddaten war die Laufzeit der Objekterkennung eine ausschlaggebende Größe für die Leistung des Gesamtsystems. Unter dieser Schranke war eine zufriedenstellende Funktion des Autos nicht zu gewährleisten.
- Durchschnittliche Intersection over Union (IoU)>= 60% Die durchschnittliche IoU ist der beste Proxy für die Güte der Bounding Boxes, den wir im Laufe des Projekts gefunden haben. In der Regel wird ein Wert von 50% als Schranke für eine erfolgreiche Erkennung genommen.
Zu optimierende Metriken:
- FPS
- avg. IOU
- Mean Average Precision (mAP): Die gemittelte durchschnittliche Präzision ermöglichte es uns, die Modelle für die Objekterkennung auf einem größeren Sicherheitsintervall zu prüfen, was für den dynamischen Einsatz sehr wichtig war.
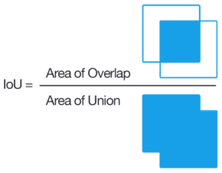
Validierung
Durchschnittliche Bounding Box Höhe/Breite Fehler und Winkelfehler (Fehler in X-Koordinate des Mittelpunkts der Bounding Box)
Da letztendlich das Objekterkennungsmodul eine möglichst genaue Lokalisierung von den Pylonen liefern muss, sind die maßgeblichen Gütekriterien die Eingangsgrößen der Distanzschätzung. Je näher die vorhergesagte Höhe/Breite der Bounding Box sowie der vorhergesagte horizontale Winkel, desto besser die Distanzschätzung.
Hyperparameter :
- Komplexität und Tiefe des Feature-Extractor-Netzwerks
- Auflösung des Objekterkennung-Grids
- Auflösung des Eingangbilds
- ignore_threshold: Ab welcher Überlappung mit der ground-truth Bounding Box kann der Fehler vernachlässigt werden?
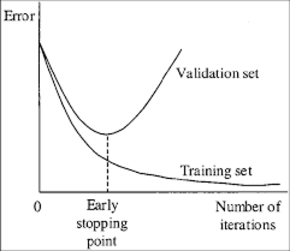
Overfitting
Label-Tool
Da wir mit Darknet YOLO Supervised Learning durchführen, brauchen wir natürlich möglichst viele annotierte Daten. Da es sehr zeitaufwendig ist, lohnt es sich an dieser Stelle die Suchmaschine der Wahl zu bemühen, da für herkömmliche Objekte relativ viele Datensätze online zur Verfügung stehen.
Das MM-label-tool liefert Labels in folgendem Format:
#mm-label.txt
# of objects
X-coord_links-unten X-coord_rechts-unten Y-coord_links-unten Y-coord_links-oben class
...Darknet erwartet Labels in folgendem Format:
#darknet-label.txt
class_index x_mid_norm y_mid_norm widt_norm height_norm
...Für unser Projekt passten wir ein simples Python Label-Tool auf unsere Anforderungen an, darunter eine leichtere Bedienung sowie Labels mit integrierten Distanzschätzungswerten. Das Ergebnis hiervon ist das MM-label-tool.
Ein alternatives Label-Tool von AlexeyAB gibt es auch als eigenständige Anwendung. Mit diesem Tool sind die Label auch schon direkt im richtigen Format. Wie immer kann die Anbindung an OpenCV Kopfschmerzen bereiten. Falls ein Fehler mit waitKeyEx() eintritt, sollten alle Vorkommen in main.cpp durch waitKey() ersetzt werden.
Label-Formatierung
Da das MM-label-tool die Labels nicht im richtigen Format liefert, um zu trainieren, müssen wir diese erst konvertieren. Hierfür gibt es eine einfache Haskell-Kommandozeile-Anwendung, die mit stack relativ leicht zu installieren und auszuführen ist. Alternativ gibt es noch ein Python Skript von Guanghan Ning, welches gegebenenfalls nach Bedarf erweitert werden kann. Dafür müssen nur Line 34 und Line 35 angepasst werden, um den Input und Output zu definieren.
Die Distanzschätzung der erkannten Objekte wird anhand der intrinsischen Parameter der Kamera und Maße sowohl des Sensors als auch der Objekte durchgeführt. Auf den nachfolgenden Grafiken ist der Vorgang gezeigt, für den Fall, dass die Höhe der Objekte für die Schätzung benutzt wird. Um die Breite zu benutzen, müssen lediglich alle angegebenen Höhen durch die zugehörigen Breiten ersetzt werden.

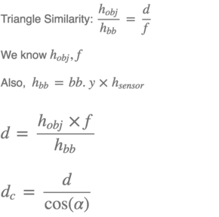
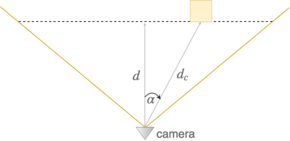
Was hier nicht erwähnt wird, ist die Rückrechnung auf die Egoperspektive. Unsere Distanzschätzung benutzt die Position der Kamera auf dem 2D-Koordinatensystem als Ursprung.
In CLARA werden diese Daten auf das Center of Gravity unseres Fahrzeugs zurück gerechnet mit Einbezug der Lokalisierung. Bei dieser Berechnung ist zudem die Latenz im System zu beachten, da zwischen der Aufnahme der Bilder, der Erkennung und Positionsschätzung der Objekte und dem Schicken der geschätzen Objekte über das lokale Netzwerk eine bestimmte Zeit vergeht.
Rektifizierung
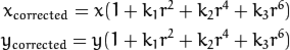
Rektifizierte Punkte
Mittels des OpenCV-Moduls calib3d konnten wir durch verschiedene Aufnahmen von Schachbrettmustern die intrinsischen Parameter und Parameter zur Rektifizierung unseres Kamerasystems herausfinden. Bei der Rektifizierung wird die radiale Verzerrung der Bilder entfernt.
Mit der sehr guten Dokumentierung von OpenCV geht das Ganze relativ schnell, sobald ein adäquates Schachbrettmuster zur Verfügung steht. In Großform präzise zu drucken wäre besser, wir haben uns nach einigen Tests mit aufgenommenen Bildern von einem projizierten Schachbrett zufrieden stellen müssen.
Zur Laufzeit war uns der Gewinn an Genauigkeit bei der Distanzschätzung jedoch nicht den Verlust an horizontalem Blickfeld wert, weshalb wir letztendlich die Bilder nicht rektifizierten.

Erkanntes Schachbrettmuster
Tracking
Bisher haben wir uns nur damit auseinander gesetzt, mehrere Objekte auf Farbbildern zu lokalisieren und zu klassifizieren. Für unseren Anwendungsfall ist die Taktrate der Erkennnug am Wichtigsten, da nur so gewährleistet werden kann, dass Objekte schnellstmöglich erkannt werden beim Eintreten in unser Blickfeld - bei scharfen Kurven zum Beispiel. Weil unser Modul aber in einem Regelkreis ist, und die einzigen Informationen zu der Strecke liefert, sollten wir so schnell wie möglich Informationen zu den erkannten Objekten liefern. Tracking besteht darin, eine bereits erkannte Region of Interest - unsere Bounding Boxes - über den Verlauf von zwei oder mehreren Bildern zu verfolgen. Diese Aufgabe ist wesentlich weniger aufwändig als die Objekterkennung und kann mit ihr sehr gut kombiniert werden.

Object Tracking
Indem wir Objekterkennung auf unserer integrierten GPU und das Tracking auf den CPUs laufen ließen, konnten wir zudem gewährleisten, dass wir nicht bei der Taktrate der Objekterkennung für das zusätzliche Verfolgen der Objekte einbußen mussten.
Das Tracking lief bei 50Hz bei einer Erkennnug, die mit 22Hz lief. Obwohl die mögliche Geschwindigkeit bei Kurven dadurch nicht geändert wird, macht es bei Bereichen, in denen die Pylonen lange im Blickfeld der Kamera sind, leichter, eine stetigere Planung zu berechnen und somit die Arbeit für unseren Regler zu erleichtern.
Optischer Fluss
Annahmen:
1. Die Intensität von Pixeln verändert sich nicht in aufeinanderfolgenden Bildern.
2. Benachbarte Pixel bewegen sich ähnlicherweise.
Lucas-Kanade-Methode
Mit dieser Methode wird die Gleichung für den optischen Fluss auf eine symmetrische Nachbarschaft von Pixeln erweitert, womit ein überbestimmtes System erreicht wird. In unserem System benutzten wir eine OpenCV Implementierung für optischen Fluss, um erkannte Objekte über Bildsequenzen verfolgen zu können.
Um den Lucas-Kanade optischen Fluss zu benutzen, muss auf L18 von src/yolo_dll_console.cpp der #define Ausdruck auskommentiert werden.
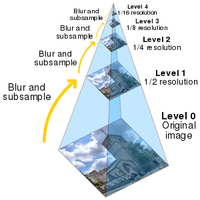
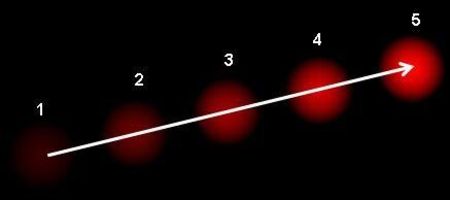
Bildpyramide Optischer Fluss Vektor über mehrere Bilder
Kalman-Filter
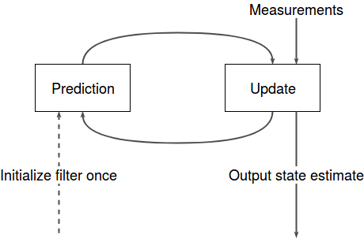
- Prediction/Vorhersage: Über ein mathematisches Modell eines Systems wird der nächste Zustand des Systems anhand des aktuellen vorhersagt.
- Update/Aktualisierung: Mittels Daten von Sensoren, die direkt oder indirekt Daten zum Zustand des Systems liefern, wird die Vorhersage verbessert.
Grundlegend werden beim Kalman-Filter Informationen zu der Modellierung des Systems und Messdaten kombiniert, um dessen Zustand besser schätzen zu können. Eine beispielhafte Anwendung des Kalman-Filters in Zusammenhang mit Objekterkennung auf Farbbildern ist auf folgendem Repo zu finden. Obwohl der Aufwand wesentlich höher ist, die Kalman-Filter zu parametrisieren, können die Ergebnisse hier wesentlich besser ausfallen.
#/bin/bash
git clone https://github.com/ddavid/darknet
# Makefile entsprechend den Kommentaren anpassen
# LIBSO flag auf 1 setzen
cd darknet
vim/nano/gedit/... Makefile
# Darknet builden
make -jFalls ihr eure eigenen Modelle trainieren wollt, müsst ihr erstmal mit dem Label-Tool eurer Wahl einen Trainingsdatensatz angemessener Größe erstellen. Hier sind in der Regel mindestens 2000 Bilder pro Klasse nötig, um gute Ergebnisse zu erzielen. Sollte dieser Aufwand zu hoch sein und die zu erkennenden Objekte innerhalb der Klassen der COCO, VOC oder Open Images Datensätze, können fertig trainierte Weights direkt von der Webseite des Verfassers von Darknet runtergeladen werden. Hierbei können sowohl Ausführungen von YOLOv3 als auch YOLOv2 interessant sein.
Mit den Bildern und Labeln im richtigen Format zur Hand können wir uns nun dem Training widmen. Darknet braucht unsere Hilfe, um zu wissen, mit welchen Bildern und Labeln es trainieren soll. Hierfür ist eine Textdatei nötig, die auf jeder Zeile einen relativen Pfad - vom Verzeichnis der Ausführung von ./darknet aus - zu einem Bild enthält. Die Anwendung erwartet die entsprechenden Label-Textdateien im selben Ordner oder wenn eines der Verzeichnisse im Pfad zu dem Bild “Images” heißt, auf demselben Pfad nachdem “Images” mit “Labels” ersetzt wird.
# train.txt
relative/path/image00001.JPG
relative/path/image00002.JPG
relative/path/image00003.JPG
relative/path/image00004.JPG
...Zudem ist noch wichtig, dass wir in einer Datei hinterlegen, mit welchen Klassen wir trainieren wollen. Hier sollte man dieselbe Datei hernehmen, die man beim Label-Tool schon hinterlegt hat, da die Reihenfolge gleich bleiben sollte. Die Indizierung der Zeilen wird für die Anzeige benutzt. Der Suffix der Datei spielt keine Rolle, hier könnte auch eine *.txt Datei benutzt werden.
# classes.names
person
dog
zebra
lion
...Nun fehlt nur noch eine Textdatei, die Informationen für Darknet zusammenfasst.
# test.data
classes=5
train = /absolute/path/to/train.txt
# Zum Trainieren nicht zwingend notwendig, für Evaluierung nach dem Training nützlich
valid = /absolute/path/to/dev.txt
names = /absolute/path/to/classes.names
# Hier werden unsere .weights Dateien regelmäßig gespeichert
backup = /absolute/path/to/backupNun kann das Training beginnen!
./darknet detector train test.data cfg/yolo-voc.2.0.cfg [*.backup]
Die optionale .backup-Datei dient dazu, eine abgebrochene Trainingseinheit weiterzuführen, hier sollten natürlich dieselben Config-Dateien benutzt werden.
Sobald das Training fertig ist, stehen wir vor der Qual der Wahl einer guten .weights Datei für unser Modell. Für ein schnelles Testen, erweist sich die Loss-Grafik für nützlich, für tiefere Evaluierung, können andere Funktionen der Darknet-Anwendung benutzt werden, wie ./darknet detector recall … oder ./darknet detector map … oder auch eigene Evaluierungsmetriken ergänzt werden. Dabei ist es wichtig, wenn nicht alle, eine große Stichprobe der .weights Dateien anzuwenden. Obwohl das Training in aller Regel zu einem geringen Wert der Verlustfunktion konvergiert, können Gewichte trotzdem zu sehr unterschiedlichen Ergebnissen führen, vor allem was die Güte der Bounding Boxes angeht.
Zudem will man natürlich auch keine Gewichte nehmen, bei denen es schon zu einem Overfitting der Daten gekommen ist.
In der folgenden Abbildung sieht man für eines unser Modelle, wie sich die durchschnittliche IoU verhält.
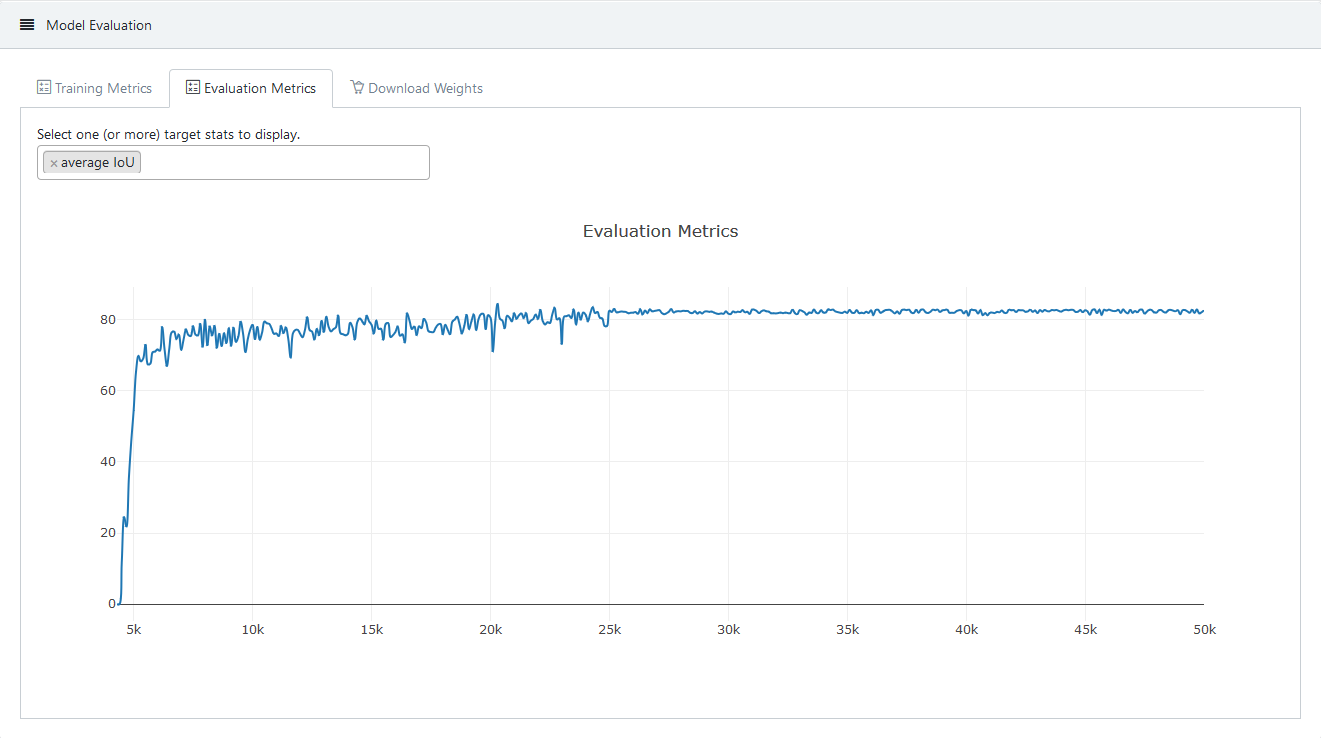
Verlauf der avg. IoU für alle trainierten Gewichte
Mit den richtigen Dateien zur Hand, kann das Ganze nun zur Probe gestellt werden. Mit dem folgenden Befehl, könnt ihr eure Ergebnisse mit einer Bilddatei testen.
./darknet detector test test.data cfg/yolo-voc.2.0.cfg backup/trained.weights image.jpgFür Live-Tests könnt ihr sowohl die ./darknet detector demo Befehle benutzen, als auch die Beispielanwendung ./uselib für die Nutzung von Darknet als Shared Library. Wenn ihr eine WebCam an eurem Laptop habt, könnt ihr sie mit ihrem Index ansprechen - in der Regel 0, wenn ihr nur eine verbundenen Kamera habt.
So könnt ihr mit ./uselib test.data yolo-voc.2.0.cfg backup/trained.weights cam_index euer Netz mit der verbundenen Kamera testen.
Und so könnten zum Beispiel die Ergebnisse aussehen ;)
Hier sieht man schon einige der Probleme, die mit YOLOv2 aufkommen können. Unsere Modelle wurden mit zufällig skalierten Bildern trainiert. Wenn man eine Skalierung zur Inferenz nimmt, die höher ist, als die, die beim Training aufkommen, kann man zwar kleinere Objekte besser erkennen, aber unter Umständen große Objekte nicht mehr - am blauen Hütchen links unten ersichtlich. Zusätzlich gibt es je nach Einstellung der confidence auch Fehlerkennungen, die in einem Verarbeitungsschritt nach der Erkennung gefiltert werden müssten.
Allerdings ist eine Erkennung von Hütchen auf eine Distanz von bis zu 15m bei diesen Bedingungen eine sehr gute Leistung.
Ausblick
In nächsten Teil der Blogreihe geht es um Trajektorienplanung, d.h. konkret: Es soll basierend auf einer Karte der Umgebung des Fahrzeugs (bestehend aus einem Track, der durch Hütchen markiert ist) eine möglichst schnelle Route inklusive der nötigen Fahrzeugparameter (Geschwindigkeit, Lenkwinkel, Beschleunigung etc.) durch den Track berechnet werden.
Noch Fragen?
Was bedeutet Machine Learning und wie kann Ihr Unternehmen vom Einsatz profitieren? Erfahren Sie, wie wir Sie beim Thema Machine Learning unterstützen können:
![]() David Dodel - schrieb seine Informatik-Bachelorarbeit bei iteratec und leitete das diesjährige municHMotorsport e.V. Driverless Projekt. Wir schätzen seine Beitrag und informieren, dass er nicht mehr bei iteratec tätig ist.
David Dodel - schrieb seine Informatik-Bachelorarbeit bei iteratec und leitete das diesjährige municHMotorsport e.V. Driverless Projekt. Wir schätzen seine Beitrag und informieren, dass er nicht mehr bei iteratec tätig ist.
Weitere Artikel










- Juni 2026
- April 2026
- Februar 2026
- Januar 2026
- Dezember 2025
- November 2025
- Oktober 2025
- August 2025
- Juli 2025
- Juni 2025
- Mai 2025
- April 2025
- März 2025
- Februar 2025
- Januar 2025
- Oktober 2024
- September 2024
- August 2024
- Juli 2024
- Juni 2024
- Mai 2024
- April 2024
- März 2024
- Februar 2024
- Januar 2024
- Dezember 2023
- November 2023
- September 2023
- August 2023
- Juli 2023
- Juni 2023
- Mai 2023
- April 2023
- Februar 2023
- Dezember 2022
- November 2022
- Mai 2022
- April 2022
- März 2022
- Januar 2022
- Dezember 2021
- November 2021
- Oktober 2021
- August 2021
- Juli 2021
- Juni 2021
- Mai 2021
- April 2021
- Dezember 2020
- Oktober 2020
- September 2020
iteratec
iteratec ist der Partner für alle, die zu den Gewinner:innen der digitalen Transformation gehören wollen. Mit individuellen, überlegenen Lösungen eröffnen wir unseren Kunden technologische wie unternehmerische Potenziale. Denn: Wenn Scheitern keine Option ist, sind wir der Partner, der den Unterschied macht. So haben wir seit 1996 mehr als 1.000 Projekte zum Erfolg geführt und eine Kundenzufriedenheit von 97%.









