In der industriellen Fertigung ist die visuelle Qualitätskontrolle ein äußerst wichtiger Prozess, um beispielsweise auszuschließen, dass Kunden ein Auto mit fehlerhafter Schweißnaht erhalten oder defekte Komponenten im Innenleben einer elektrischen Zahnbürste zu einer verkürzten Lebensdauer führen. Die visuelle Qualitätskontrolle beschreibt im Wesentlichen das visuelle Prüfen von Fertigprodukten auf Defekte. In der technischen Betrachtung spricht man von Anomalien. Weil das Vertrauen von Kunden in Produkte wichtig, die Kontrolle jedoch sehr monoton ist, gibt es bereits sehr viele Ansätze diesen Prozess mithilfe von Machine Learning Algorithmen zu automatisieren und dadurch zu optimieren [0].
Die dabei eingesetzten Machine Learning Algorithmen kommen aus dem Bereich der Bildverarbeitung, im englischen als Computer Vision (CV) bezeichnet. In den letzten Jahren kam eine neue Form der Modelle in diesem Bereich auf - so genannte Vision Transformer Modelle. Durch diese Entwicklung ergibt sich die spannende Frage: Was sind Vision Transformer Modelle und welche Potenziale bieten sie im Bereich der industriellen Qualitätskontrolle?
INHALT
- Was sind Vision Transformer Modelle?
- Wie funktioniert die Anomalie Erkennung?
- Was bedeutet das für die visuelle Qualitätskontrolle?
- Fazit
Was sind Vision Transformer Modelle?
Um diese Frage zu beantworten, müssen wir einen kurzen Ausflug in den Bereich der Sprachverarbeitung machen. Dort gelten Transformer Modelle bereits seit mehreren Jahren als State-of-the-Art und spätestens seit ChatGPT ist diese Technologie in der breiten Masse allgemein bekannt. Für diesen Artikel interessant sind eine spezielle Art von Transformer Modellen – die Vision Transformer. Bei Vision Transformer Modellen handelt es sich um Modelle, welche denselben Mechanismus wie „klassische“ Transformer Modelle einsetzen, den Attention-Mechanismus [1], allerdings auf die Verarbeitung von Bildern spezialisiert sind [2]. An dieser Stelle ein kurzer technischer Deep Dive:
- Da Transformer ihren Ursprung in der Sprachverarbeitung haben, sind sie auf die Verarbeitung von Sequenzen spezialisiert. Bilder allerdings werden als Matrizen von Pixelwerten (0 - 255) dargestellt. Um die Verarbeitung von Bildern zu ermöglichen, werden diese in sogenannte Patches aufgeteilt. Das Modell bekommt dann einen Vektor von „geflatteten“ Patches als Input (Abbildung 1).
- Das Transformer Modell reichert den Eingabevektor während der Verarbeitung um Informationen an. Das Ergebnis dieses Prozesses ist ein Vektor oder eine Matrix die Information in Form von Zahlen enthält. Dieses Ergebnis wird als Latent Space bezeichnet.
- Im Gegensatz zu klassischen Computer Vision Modellen (CNNs), wird der Eingabevektor während der Verarbeitung nicht komprimiert. Der Nachteil der fehlenden Komprimierung ist, dass Vision Transformer im Vergleich zur CNNs sehr groß sind. Ein sehr bekanntes und weit eingesetztes CNN ist ResNet [3].
- Der Vorteil von Vision Transformer Modellen gegenüber CNNs ist, dass sie globale Zusammenhänge in Bildern besonders gut erfassen können [2]. Das heißt wenn eine Information links oben in einem Bild mit einer Information rechts unten zusammenhängt, ist das aus dem erzeugten Latent Space eines Vision Transformer Modells tendenziell besser ersichtlich als aus dem Latent Space eines CNN-Modells.
- Da es Bilder in beliebig großer Auflösung geben kann, ist die Größe von Vision Transformern ein ziemliches Problem. Vor allem für Produktionsszenarien, in denen Hardware mit begrenzter Kapazität verfügbar ist, sind sie dadurch ungeeignet. Dieses Problem wird durch die Entwicklung so genannter hierarchischer Vision Transformer angegangen. Diese Modelle verwenden Patch-Merging Layer, um die Größe der verarbeiteten Bilder während des Lernprozesses zu reduzieren [4]. Abbildung 1 zeigt die Architektur des hierarchischen Vision Transformer Modells EsViT. Dieses Modell in von der Größe (Parameteranzahl) vergleichbar mit ResNet.
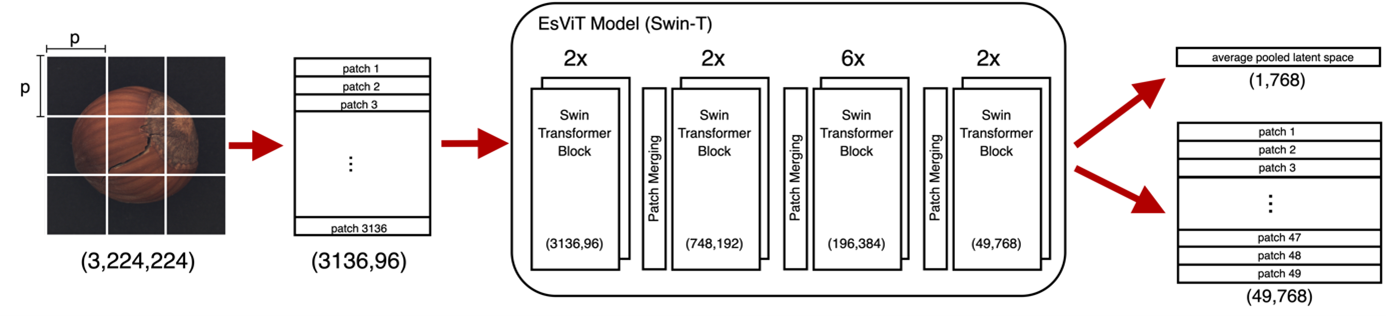
Abb. 1: Hierarchische Vision Transformer Architektur am Beispiel des Modells EsViT
Wie funktioniert die Anomalie Erkennung?
Datensätze zur Anomalie Erkennung sind oft sehr unausgeglichen – es gibt einen sehr hohen Anteil an normalen und einen sehr geringen Anteil an anormalen Daten. Aus diesem Grund und weil teilweise schwer vorhergesagt werden kann welche Anomalien auftreten können, kann es schwer sein ein Modell darauf zu trainieren das Aussehen von Anomalien direkt zu lernen. Stattdessen werden oft Ansätze bevorzugt, die das Aussehen von normalen Daten lernen [5]. Bei diesen Unsupervised-Learning Methoden werden im Training nur normale Daten verwendet. Das Modell lernt dadurch die Verteilung der normalen Daten. Wenn das trainierte Modell anormale Daten bekommt, liegen diese außerhalb oder am Rand der gelernten Verteilung und können so identifiziert werden. Abbildung 2 zeigt eine High-Level Architektur des Trainings- und Anomalie Erkennungsprozesses. Das Erste Modell in dem Prozess wird als Encoder bezeichnet. Es ist dafür zuständig das Wissen aus den Bilddaten zu extrahieren und komprimiert darzustellen. Dieses Modell kann ein Vision Transformer oder ein CNN sein. Es wird vortrainiert verwendet und nicht angepasst. Das zweite Modell, der Decoder, ist das eigentliche Modell zur Anomalie Erkennung. Es ist dafür zuständig, die Verteilung der normalen Daten zu lernen. Bei der Anomalie Erkennung ist es dann in der Lage auf Bildebene zu sagen, ob ein Defekt vorliegt und auf Pixelebene zu markieren, wo sich der Defekt befindet. Da diese Modelle eine Wahrscheinlichkeit für jeden Eintrag im Latent Space berechnen, ist die Modellgröße stark davon abhängig wie groß der Latent Space ist – je komprimierter die Information, desto besser.
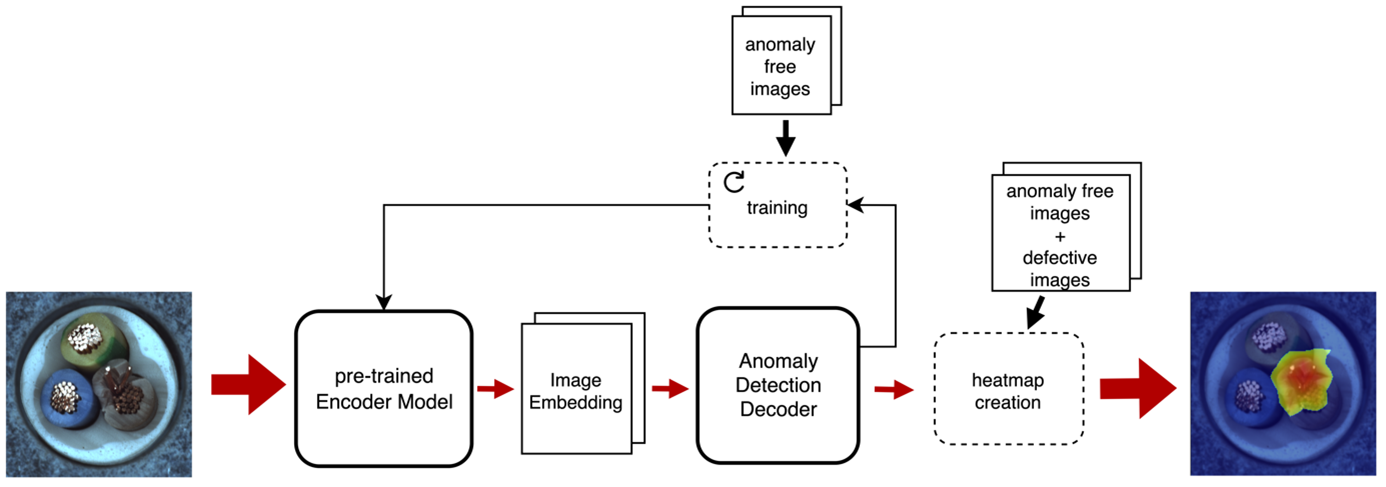
Abb. 2: High-Level Architektur des Trainings- und Anomalie Erkennungsprozess
Was bedeutet das für die visuelle Qualitätskontrolle?
1. Bessere Performance
In der visuellen Qualitätskontrolle können verschiedene Arten von Anomalien auftreten [5]:
- Textuelle Anomalien beziehen sich auf die Unversehrtheit eines Produktes und können zum Beispiel Verunreinigungen, Risse, Löcher oder Kratzer sein. Sie zu erkennen erfordert wenig semantische Informationen.
- Funktionale Anomalien beziehen sich auf die Korrektheit eines Produkts bezogen auf einen konkreten Anwendungsfall. Das kann zum Beispiel ein falsch eingestecktes Kabel oder ein falsch platzierter Transistor sein. Diese Anomalien zu erkennen, benötigt viel semantische Informationen.
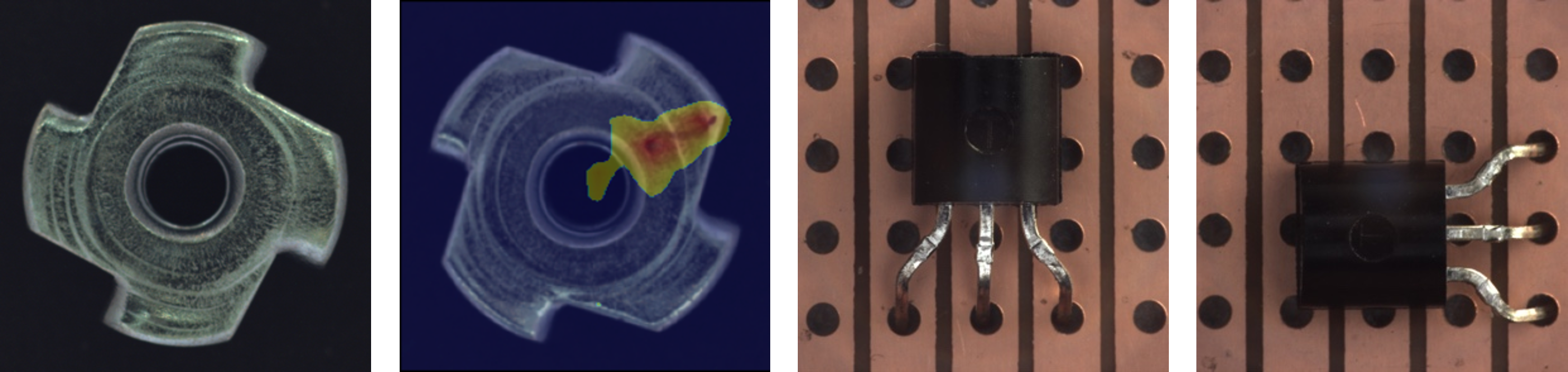
Abb. 3: links Metallzahnrad intakt und mit Kratzer (textuelle Anomalie), rechts richtig und falsch platzierter Transistor (funktionale Anomalie). Bilder aus dem MVTecAD Datensatz [6].
Durch die Erkennung globaler Zusammenhänge mithilfe des Attention Mechanismus sind Vision Transformer sehr gut geeignet, um semantische Informationen aus einem Bild zu extrahieren [2]. Der erzeugte Latent-Space enthält dabei mehr Informationen und ist trotzdem kleiner als bei der Nutzung von ResNet. In durchgeführten Experimenten hat der mit ResNet erzeugte Latent Space 2048 Einträge (Features) und der mit einem großen Vision Transformer erzeugte Latent Space nur 768. Das führt dazu, dass trotz dreimal größerem Encoder die Größe des Gesamtmodells etwas kleiner ist. In Tabelle 1 sind die Ergebnisse der verschiedenen Modelle im Vergleich zu sehen. Die verwendete Metrik ist die Area Under Receiver Operating Characteristics Curve (AUROC) auf Bildebene (AD) und auf Pixelebene (AL). Die ROC-Kurve zeigt die Spanne zwischen True-Positive und False-Positive Rate. Trotz geringerer Größe sind die Anomalie Erkennungsergebnisse bei Nutzung des großen Transformer Modells, DeiT, besser als bei Nutzung des ResNet Modells. Das EsViT Modell erzeugt ebenfalls einen Latent Space der Größe 768. Das gesamte Modell ist damit nicht einmal halb so groß wie mit der Verwendung von ResNet. Die Ergebnisse sind allerdings deutlich schlechter.
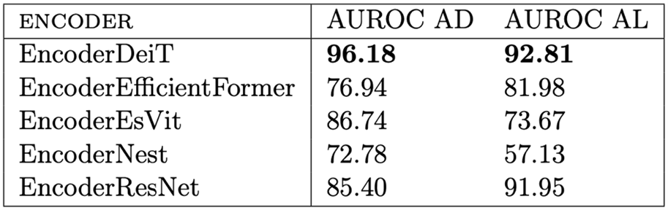
Tabelle 1: Vergleich der Performance der verschiedenen Encoder Modelle. DeiT ist ein großer Transformer, die drei folgenden Modelle sind hierarchische Transfomer, das letzte Modell, ResNet, ist ein CNN.
2. Flexiblere Modelle
Unternehmen haben oft eine große Produktpalette, welche sich kontinuierlich verändert - neue Produkte kommen hinzu oder bestehende verändern sich. Außerdem gibt es unterschiedliche Anforderungen daran was bei einem Produkt als Anomalie angesehen wird und was nicht – kleine Kratzer oder Staubpartikel können bei manchen Produkten unproblematisch, bei anderen hingegen kritisch sein. Das hat zur Folge, dass ein Modell zur Qualitätskontrolle für jedes Produkt individuell angepasst werden muss. In einem Unternehmen mit vielen Produkten und einer hohen Änderungsfrequenz kann das zu erheblichem Aufwand bei der Entwicklung solcher Modelle führen.
Die Nutzung von vortrainierten Vision Transformer Modellen bietet dabei zwei große Vorteile:
- Geringere Trainingszeit durch Minimierung der Größe des zu trainierenden Modells
- Einfachere Datenvorbereitung bei neuen/ geänderten Produkten
=> Keine Notwendigkeit der synthetischen Herstellung von Bildern mit möglichen Defekten
Fazit
Große Vision Transformer Modelle verbessern die Performance von Anomalie Erkennungsmethoden, und haben das Potenzial die Größe des Gesamtmodells zu verringern. Hierarchische Vision Transformer erzeugen kleinere Modelle, liefern aber noch nicht die benötigte Ergebnisqualität. Trotz allem zeigen sie vielversprechende Ansätze und die Entwicklung in diesem Bereich geht weiter. Neueste hierarchische Modelle sind so klein, dass sie sogar auf Smartphones laufen können [7]. Diese spannende Entwicklung zeigt, dass Transformer Modelle nicht nur für GenerativeAI sondern auch für den Bereich der industriellen Fertigung sehr interessant werden können.
Die beschriebenen Ergebnisse sind Erkenntnisse aus meiner Masterarbeit. Die Arbeit wurde an der Hochschule Karlsruhe, an der Fakultät für Informatik und Wirtschaftsinformatik geschrieben und hat den Titel „Evaluating the use of pre-trained Vision Transformer models for visual quality control in industrial manufacturing“.
Mehr Informationen zu den technischen Details gibt es zudem in unserem zugehörigen Paper https://pabair.github.io/assets/ECML2024.pdf
Quellen
[0] T. Wang, Y. Chen, M. Qiao, and H. Snoussi, “A fast and robust convolutional neural network- based defect detection model in product quality control,” The International Journal of Advanced Manufacturing Technology, vol. 94, no. 9-12, pp. 3465–3471, 2018, issn: 0268-3768. doi: 10.1007/ s00170-017-0882-0. [Online]. Available: https://link.springer.com/content/pdf/10.1007/ s00170-017-0882-0.pdf?pdf=inlinelink.
[1] A. Vaswani, N. Shazeer, N. Parmar, et al., Attention is all you need. [Online]. Available: https: //arxiv.org/pdf/1706.03762.
[2] A. Dosovitskiy, L. Beyer, A. Kolesnikov, et al., An image is worth 16x16 words: Transformers for image recognition at scale, 2020. [Online]. Available: https://arxiv.org/pdf/2010.11929.
[3] K. He, X. Zhang, S. Ren, and J. Sun, Deep residual learning for image recognition, 2015. [Online]. Available: https://arxiv.org/pdf/1512.03385.
[4] C. Li, J. Yang, P. Zhang, et al., Efficient self-supervised vision transformers for representation learning. [Online]. Available: https://arxiv.org/pdf/2106.09785.pdf.
[5] X. Tao, X. Gong, X. Zhang, S. Yan, and C. Adak, “Deep learning for unsupervised anomaly localization in industrial images: A survey,” IEEE Transactions on Instrumentation and Measurement, vol. 71, pp. 1–21, 2022, issn: 0018-9456. doi: 10.1109/TIM.2022.3196436.
[6] Paul Bergmann, Kilian Batzner, Michael Fauser, David Sattlegger and Carsten Steger, “The MVTec Anomaly Detection Dataset: A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection” International Journal of Computer Vision, 2021
[7] Y. Li, J. Hu, Y. Wen, et al., “Rethinking vision transformers for mobilenet size and speed,” arXiv preprint arXiv:2212.08059, 2022.
Haben Sie Fragen oder benötigen Sie Unterstützung?
Mehr zu den Möglichkeiten von Künstlicher Intelligenz für Ihr Unternehmen finden Sie auf unserer Webseite.
Sprechen Sie uns auch gerne an.

Weitere Artikel










- Juli 2026
- Juni 2026
- April 2026
- Februar 2026
- Januar 2026
- Dezember 2025
- November 2025
- Oktober 2025
- August 2025
- Juli 2025
- Juni 2025
- Mai 2025
- April 2025
- März 2025
- Februar 2025
- Januar 2025
- Oktober 2024
- September 2024
- August 2024
- Juli 2024
- Juni 2024
- Mai 2024
- April 2024
- März 2024
- Februar 2024
- Januar 2024
- Dezember 2023
- November 2023
- September 2023
- August 2023
- Juli 2023
- Juni 2023
- Mai 2023
- April 2023
- Februar 2023
- Dezember 2022
- November 2022
- Mai 2022
- April 2022
- März 2022
- Januar 2022
- Dezember 2021
- November 2021
- Oktober 2021
- August 2021
- Juli 2021
- Juni 2021
- Mai 2021
- April 2021
- Dezember 2020
- Oktober 2020
- September 2020
iteratec
iteratec ist der Partner für alle, die zu den Gewinner:innen der digitalen Transformation gehören wollen. Mit individuellen, überlegenen Lösungen eröffnen wir unseren Kunden technologische wie unternehmerische Potenziale. Denn: Wenn Scheitern keine Option ist, sind wir der Partner, der den Unterschied macht. So haben wir seit 1996 mehr als 1.000 Projekte zum Erfolg geführt und eine Kundenzufriedenheit von 97%.