„Wir lösen jetzt unsere Themen mit Machine Learning, also müssen wir nichts mehr programmieren!“ Ist das so? Ersetzt Machine Learning bald jede Programmieraufgaben und ist damit die klassische Softwareentwicklung unnötig?
Machine Learning ist kein neues Verfahren. Egal, ob Entscheidungsbäume, Clustering-Verfahren oder lernende künstliche neuronale Netze, die zugrundeliegenden Algorithmen sind im Wesentlichen nicht neu. Woher kommt dann der heutige Hype der selbstlernenden Maschinen und gibt es Grenzen der Systeme?
Inhalt
- Welche Machine Learning Systeme gibt es?
- Woher kommt der aktuelle Hype im Maschine Learning?
- Wo ist der Unterschied zum herkömmlichen Programmieren?
- Demnach werden Algorithmen zukünftig selbstlernend und ohne analytische Programmierung erstellt?
Welche Machine Learning Systeme gibt es?
Auf Basis der zugrundeliegenden Lernmethode gibt es drei klassische Unterscheidungen, wobei kombinierte Methoden möglich sind:
- Supervised Learning – Das System wird mit Inputdaten und bekannten Ergebniswerten trainiert. Mit diesen Trainingssets wird in dem System ein generalisiertes Gesetz gelernt, durch das die Inputdaten auf den Ergebniswerte abgebildet werden. Später können über das gelernte Gesetz auf Grund der Generalisierung neue Inputdaten verarbeitet werden.
- Unsupervised Learning – Zu den Inputdaten werde keine bekannten Ergebniswerte im Vorfeld definiert. Das System findet selbständig Strukturen oder Gesetzmäßigkeiten in den Inputdaten. Im Rahmen eines Versuchsprojektes von Google zu Unsupervised Learning wurde ein Deep Learning System mit 10 Millionen zufälligen Bildern ohne weitere Beschreibung gefüttert. Das System konnte selbständig 20.000 Gegenstände identifizieren und seine Interpretation einer Katze ausgeben.
- Reinforcement Learning – Das System bewegt sich in einem Environment mit einem vordefinierten Ziel. Die konkrete Durchführung erlernt das System selbständig bspw. autonomes Fahren. Meist werden hier Reward- und Penalty-Mechanismen eingesetzt, über die das System den Lernfortschritt selbst bestimmen kann.

Bei autonomen Fahren, dem Sieg gegen den Go-Meister oder Spracherkennungssystemen sind gelernte künstliche neuronale Netze die Basis für viele der heutigen „Wunder“, die fast täglich in der Zeitung stehen. Die heutigen Netze sind mit 20 oder sogar 150 Layer von den frühen Anfängen mit 2-3 Layer weit entfernt.
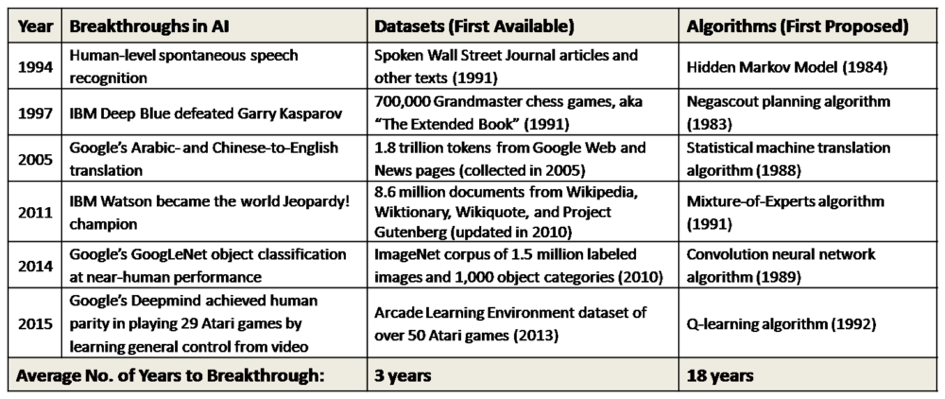
Der Hype basiert auf der Renaissance dieser künstlichen neuronalen Netze in Verbindung mit Deep Learning. Auf Basis von Lerndaten werden in den Netzen Strukturen gelernt. Dadurch entsteht im inneren eines Netzes ein Algorithmus, der die Lerndaten repräsentiert. Die Repräsentation muss genau genug sein, um neue Daten zuverlässig bewerten zu können. Sie darf allerdings nicht zu genau sein, da neue Daten bewertet werden sollen, die nicht in allen Eigenschaften den bisherigen entsprechen.
Motor für diese Renaissance ist die Entwicklungen der Technik und die Verfügbarkeit großer Datenmengen und Informationen. Beide Faktoren haben in den vergangenen Jahren einen Schub erlebt:
- Kostengünstige schnelle Rechner besitzen - den Computerspielen sei Dank - schnelle Grafikkarten, über die eine hohe Anzahl Gleitkommaoperationen und Matrizenrechnungen in kurzer Zeit durchgeführt werden können. Besonders künstliche neuronale Netze, egal ob Convolutional Neural Network, Recurrent Neural Network, mit oder ohne Deep Learning lernen über diese Operationen. Damit ist es möglich Deep Learning Networks mit bis zu 150 Layer in vernünftiger Zeit zu trainieren. Ein Projekt mit einem Netz dieser Größenordnung hätte in den 1990er Jahren mehrere Jahre Trainingszeit benötigt und die Kosten wären explodiert. Heute werden die Systeme teiloffen von Cloud-Anbietern als Service zur Verfügung gestellt. Jeder Hobbyanwender kann ein Machine Learning System aufbauen und in Software-as-a-Service-Modellen auf großen Daten skalieren lassen.
- Daten und Informationen sind über das Internet in großen Mengen verfügbar. Beispielsweise der Lernansatz des Supervised Learning braucht große Datenmengen, für die Inputdaten inklusive bekannter Ergebniswerte verfügbar sind. Diese Daten sind heute für viele Aufgabenstellungen im Internet verfügbar. Die verfügbaren Daten werden häufig sogar als der wichtigste Faktor gesehen.
Die zugrundeliegenden Algorithmen, die für Machine Learning Systeme als Modell bezeichnet werden, werden auf eine andere Weise als in der klassischen Programmierung erstellt.
In der analytischen Entwicklung von Algorithmen werden die Anforderungen oder Daten analysiert und daraufhin der Algorithmus umgesetzt und optimiert. Es ist beispielsweise theoretisch möglich, eine große Anzahl von Go-Spielen aus den letzten Jahre anzusehen, diese zu analysieren und daraus einen Algorithmus zu entwickeln, der vermutlich in Konsequenz dem im inneren des künstlichen neuronalen Netzes, das den Go-Meister geschlagen hat, entspricht. Die Frage ist, ob es mit vertretbarem Aufwand möglich ist eine solchen Algorithmus zu definieren, umzusetzen und zu testen.
Das ist die Stärke der Machine-Learning-Systeme. Sie entwickeln ihren Algorithmus selbst. In einer überschaubaren Trainingszeit wird aufgrund der Architektur des künstlichen neuronalen Netzes mit den Lerndaten ein Algorithmus generiert. Der erlernte Algorithmus ist im Verhältnis zum Lernsystem recht klein und kann für viele Anwendungen, wie Objekterkennung oder Spracherkennung, auf Mobiltelefonen laufen.
Ja, das ist als Zukunftsszenario vorstellbar. Alle Funktionen und Algorithmen sind grundsätzlich trainierbar. Das Trainieren der Systeme ist jedoch von der Verfügbarkeit der Lerndaten abhängig. Bei manchen Themen ist heute der klassische Weg der Implementierung von Algorithmen zielführender und einfacher, als einem System und die entsprechende Umgebung für das Training zu definieren.
Hierzu ein Beispiel: Es soll die einfache Addition a+b von einem Reinforcement Neural Network erlernt werden. Was ist zu tun? Das Netz benötigt eine Umgebung, in der es für das korrekte Erkennen des Ergebnisses belohnt wird. Die Beurteilung, ob ein gelerntes Ergebnis korrekt ist oder nicht, kann über die Berechnung a+b geprüft werden. Also muss die Funktion a+b programmiert werden, da sie das Netz beim automatischen Lernen unterstützt. Wenn die Funktion sowieso programmiert werden muss, macht es wenig Sinn sie danach noch einmal über ein Machine Learning System zu lernen. Hier ist die klassische Programmierung einfacher und schneller.
Die Stärken der Machine Learning Systeme liegen in Aufgaben, zu denen der Lösungsalgorithmus nicht in vernünftiger Zeit analysierbar ist oder in dem Aufbau von Systemen, die sich verändernden Umgebungen anpassen müssen. Ist der Algorithmus bekannt, ist die klassische Programmierung das Mittel der Wahl.
Noch Fragen?
Was bedeutet Machine Learning und wie kann Ihr Unternehmen vom Einsatz profitieren? Erfahren Sie, wie wir Sie beim Thema Machine Learning unterstützen können:
Weitere Artikel










- Juni 2026
- April 2026
- Februar 2026
- Januar 2026
- Dezember 2025
- November 2025
- Oktober 2025
- August 2025
- Juli 2025
- Juni 2025
- Mai 2025
- April 2025
- März 2025
- Februar 2025
- Januar 2025
- Oktober 2024
- September 2024
- August 2024
- Juli 2024
- Juni 2024
- Mai 2024
- April 2024
- März 2024
- Februar 2024
- Januar 2024
- Dezember 2023
- November 2023
- September 2023
- August 2023
- Juli 2023
- Juni 2023
- Mai 2023
- April 2023
- Februar 2023
- Dezember 2022
- November 2022
- Mai 2022
- April 2022
- März 2022
- Januar 2022
- Dezember 2021
- November 2021
- Oktober 2021
- August 2021
- Juli 2021
- Juni 2021
- Mai 2021
- April 2021
- Dezember 2020
- Oktober 2020
- September 2020
iteratec
iteratec ist der Partner für alle, die zu den Gewinner:innen der digitalen Transformation gehören wollen. Mit individuellen, überlegenen Lösungen eröffnen wir unseren Kunden technologische wie unternehmerische Potenziale. Denn: Wenn Scheitern keine Option ist, sind wir der Partner, der den Unterschied macht. So haben wir seit 1996 mehr als 1.000 Projekte zum Erfolg geführt und eine Kundenzufriedenheit von 97%.