Machine Learning kann nur bei großen Datenmengen zum Einsatz kommen - oder?
Für viele mag das der erste Gedanke sein, jedoch ist das nicht ganz richtig. Im Folgenden stellen wir die Methode des Sequential Learnings (SL) vor, die es ermöglicht, auch mit wenigen Daten zuverlässige Vorhersagen zu treffen. Neben den theoretischen Ideen sehen wir uns auch einen konkreten Anwendungsfall an, in dem SL eingesetzt wird, um CO2 in der Zementproduktion einzusparen.
- Sequential Learning: Wenig Daten, viel Impact
- Sequential Learning im Kontext von KI & Machine Learning
- Sequential Learning in der Praxis: Wir optimieren die Zement-Herstellung
- Weitere Anwendungsfälle und Ausblick
1. Sequential Learning: Wenig Daten, viel Impact
Viele Systeme, die auf Künstliche Intelligenz (KI) zurückgreifen, lernen durch das wiederholte Training auf Basis bekannter Daten. Stellt euch einen Spamfilter vor: Er erkennt verdächtige E-Mails, da der Algorithmus viele Beispiele von Spam und gewöhnlichen E-Mails studiert. Anhand dieser Informationen lernt er zu unterscheiden, ob es sich um Spam handelt und kann das Gelernte auf neue E-Mails anwenden.
Dieser Ansatz funktioniert vor allem dann gut, wenn viele Beispiele vorhanden sind. Weniger erfolgreich ist der Lernprozess, wenn z.B. viele Einflussfaktoren für die Entscheidungsfindung relevant, gleichzeitig aber nur sehr wenige Beispiele verfügbar sind. Hier werden alternative oder modifizierte Ansätze benötigt, wie z.B. Sequential Learning.
2. Sequential Learning im Kontext von KI & Machine Learning
Bevor wir das Prinzip hinter Sequential Learning näher erklären, lohnt es sich, einige Begriffe im Themenbereich “KI” voneinander abzugrenzen.
KI selbst ist ein Oberbegriff für Maschinen, die automatisiert Aufgaben erledigen können. Konkrete Implementierungen basieren häufig auf maschinellem Lernen (engl. Machine Learning, ML), also speziellen Klassen von Algorithmen. Eine Unterklasse hiervon ist das Deep Learning, welches die Funktionsweise des Gehirns künstlich simuliert. Mehr Details zur Unterscheidung von KI, Machine Learning und Deep Learning können in diesem Blogartikel nachgelesen werden.
Der Ansatz des Sequential Learning beruht auf Bayes’scher Optimierung. Die Idee ist einfach: Mithilfe von wenigen bekannten Daten wird ein ML-Algorithmus trainiert. Mit dem trainierten Modell werden nun Vorhersagen für neue Daten gemacht. Während traditionelle ML-Algorithmen an dieser Stelle fertig sind, geht SL ein paar Schritte weiter.
Die Vorhersagen werden priorisiert mit dem Ziel, möglichst effizient Kandidaten zur Evaluierung auszuwählen. Wie diese Priorisierung im Detail aussieht, ist problemabhängig. Neben der Vorhersage selbst, kann zum Beispiel a priori Domänenwissen relevant sein.
Auf Basis der erfolgten Priorisierung erfolgt die Evaluierung. Dadurch lassen sich die Trainingsdaten sukzessive erweitern. Das Modell wird nun auf der erweiterten Datenbasis trainiert und kann somit bessere Vorhersagen machen. Dies wird sequentiell wiederholt, bis das Modell schließlich die gewünschte Performance aufzeigt. Durch die gezielte Auswahl zu evaluierender Datenpunkte, lässt sich der Lernprozess erheblich beschleunigen, so dass auch mit wenigen Beispielen bereits gute Vorhersagen möglich sind.
Insbesondere wenn die Evaluierung teuer und zeitaufwendig ist, kann Sequential Learning daher eine hilfreiche Methode sein.
3. Sequential Learning in der Praxis: Wir optimieren die Zement-Herstellung
In einer Kollaboration mit der Bundesanstalt für Materialforschung und -prüfung (BAM) sind wir der Frage nachgegangen, wie SL dabei unterstützen kann, alternative Zementrezepturen als Basis für Beton zu identifizieren. Ein enorm relevantes Thema, da die Zementproduktion für ca. 8% des weltweiten CO2-Ausstoßes verantwortlich ist [1]. Alternative Zusammensetzungen und angepasste Verfahren, die gleichzeitig umweltfreundlicher sind und wichtige Eigenschaften von Beton (wie z.B. Druckfestigkeit) beibehalten, müssen so bald wie möglich identifiziert werden.
Es gibt jedoch zwei Probleme:
- Mögliche Kandidaten für Zusammensetzungen und Prozesse effizient zu formulieren.
- Für die gegebenen Kandidaten möglichst schnell und gezielt die vielversprechendsten zu finden.
Um Rezeptkandidaten zu entwickeln, die den vielzähligen Anforderungen aus der Normung standhalten, greifen Ingenieure auf einen großen Erfahrungsschatz zurück. Dieser Prozess ist mühsam und nicht skalierbar. Unsere Lösung hierbei: Wir haben die Fachlogik zur Rezepturentwicklung mit einem digitalen Zwilling abgebildet. Damit lassen sich weitestgehend automatisiert hunderte Rezepturen gleichzeitig formulieren [2, 3, 4].
Das Ergebnis sind hochkomplexe Rezepturen, die in der Regel durch etwa 40-50 Parameter charakterisiert werden. Gleichzeitig ist die Herstellung jeder dieser alternativen Rezepturen zeitaufwendig und mit hohen Kosten verbunden. Mit einer effizienten Herangehensweise vielversprechende Rezepturen zu finden ist somit der Kern des zweiten Problems.
Um zu verstehen, wie SL uns hier helfen kann, lohnt es sich unser Ziel zu präzisieren.
Das Ziel: Wir wollen mit möglichst wenigen Experimenten ein Material mit den gewünschten Eigenschaften finden, nämlich niedriger CO2-Ausstoß bei gleichzeitig ausreichend hoher Druckfestigkeit. Die relevante Metrik ist also nicht die präzise Vorhersage der Druckfestigkeit einer Rezeptur, sondern die Anzahl an Experimenten, die durchgeführt werden müssen, um eine Rezeptur mit gewünschten Eigenschaften zu finden.
Anhand eines ML-Modells, das initial mit wenig Datenpunkten trainiert wird, werden die Kandidaten nach dem Kriterium „Erreichen der Zieldruckfestigkeit und gleichzeitig CO2-Ausstoß minimieren“ bewertet. Oft ist es sinnvoll, die statistische Unsicherheit der Vorhersage mit einfließen zu lassen. Damit können neuartige Materialien auf ihr Potenzial getestet werden, die bisher noch nicht exploriert wurden.
Vielversprechend ist das vor allem dann, wenn bisherige Messungen noch nicht die erwünschten Ergebnisse bringen. Hier spricht man von Exploration, siehe auch Abbildung 1 (realistisches Setup im Kontext Zement & Beton).
| Abbildung 1: 2-dimensionale Projektion realistischer Betonrezepturen. Verschiedene Inseln sind zu erkennen: Innerhalb der Inseln sind die Variationen der Parameter klein im Gegensatz zu den Unterschieden zwischen Inseln. Wir sehen bekannte Werte als kleine Kreuze. Für alle anderen Rezepturen werden Vorhersagen gemacht und gewichtet. Neben Druckfestigkeit und CO2-Ausstoß wird die Unsicherheit der Vorhersage berücksichtigt. Vielversprechende Kandidaten werden insbesondere in noch nicht bekannten Inseln identifiziert. | 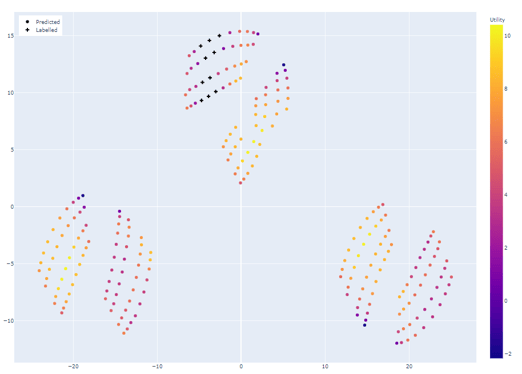 |
Wurde nun eine Vorhersage getroffen, wird die entsprechende Rezeptur tatsächlich im Experiment validiert. Dadurch gewinnen wir wertvolle neue Informationen. Denn das Experiment liefert einen neuen, gezielt ausgesuchten Messpunkt. Damit kann eine neue Iteration starten. Wieder wird mit dem ML-Modell eine Vorhersage gemacht und der am besten bewertete Kandidat im Labor hergestellt. Hier bietet es sich an, Schritt für Schritt die Gewichtung der Unsicherheit zu reduzieren, da immer mehr Bereiche des Parameterraums zumindest grob erschlossen sind. Vielversprechende Bereiche, also etwa mit relativ hohen Werten der Druckfestigkeit, sollten nun feiner abgetastet werden.
Insgesamt entsteht ein iterativer Feedback-Loop zwischen ML-Vorhersage und Experiment im Labor. Das System lernt sequentiell ganz im Sinne Bayes‘scher Optimierung. Diese Iteration stoppt, sobald tatsächlich ein Material mit den passenden Eigenschaften gefunden wurde (siehe Abbildung 2).
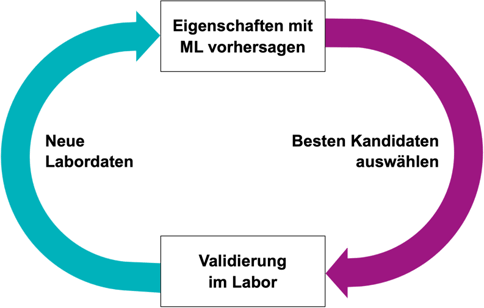 |
Abbildung 2: Sequential Learning Feedback Loop. Das Wechselspiel zwischen KI-Vorhersage und Experiment wird so lange iterativ durchgeführt, bis schließlich ein Material mit gewünschten Eigenschaften im Labor hergestellt wurde. |
Und der Mehrwert?
Wie viel schneller ist dieser Ansatz als zufälliges Auswählen und Verproben von Rezepturen? Dies hängt von einigen Kriterien ab, wie Anzahl initial bekannter Daten, gewählten ML-Algorithmen, Gewichtung von Unsicherheiten usw. Wir haben diese Einflussfaktoren im Detail mit der BAM untersucht und in einem Paper [5] veröffentlicht.
Es zeigt sich: Das Potential ist groß. Kurz zusammengefasst werden durchschnittlich deutlich weniger Experimente benötigt, um zum Ziel zu kommen. Sequential Learning kann uns also helfen, schneller und kostengünstiger umweltfreundlichere Baustoffe zu finden und somit einen wichtigen Beitrag für unser Klima leisten.
4. Weitere Anwendungsfälle und Ausblick
Das beschriebene Beispiel verdeutlicht das Potential und die Konzepte von SL. Diese sind generisch und können auch jenseits der Zement- und Betonforschung angewandt werden. Insbesondere in komplexen Systemen, die durch diverse Faktoren und Unsicherheiten charakterisiert werden können, kann SL helfen. Tatsächlich stehen viele Industrie- und Forschungszweige vor der Schwierigkeit auf Basis weniger Daten möglichst schnell Herstellungsprozesse usw. zu optimieren. Während die Forschung bereits verschiedene Problemstellungen zum Beispiel im Bereich chemischer Reaktionen [6] mithilfe von SL evaluiert, gibt es noch viele Bereiche, die von einer Adaption von SL profitieren können.
Insbesondere außerhalb der Forschung ist es zudem wichtig, auch „Nicht-IT-Experten“ zu SL abzuholen. Dazu ist es sinnvoll den Mitarbeitern intuitive Software zur Verfügung zu stellen, die dabei unterstützt, die genannten Ideen einfach zu realisieren. Im Rahmen unserer Kollaboration mit der BAM haben wir genau dies gemacht. Die Open Source Webanwendung SLAMD [2, 3, 4] erlaubt den Labormitarbeitern, alternative Zement- und Betonrezepturen zu pflegen und diese mit ML zu evaluieren. Dabei ist keine ML-Expertise, sondern nur das Fachwissen der Laboranten relevant. Über tatsächliches Verproben vorgeschlagener Materialien und die Möglichkeit, die App um Laborresultate anzureichern, lässt sich SL einfach und intuitiv realisieren. Da die App zudem flexibel ist und einfach erweitert werden kann, lassen sich auf ihrer Basis auch andere Anwendungsfälle realisieren, die relevant für unterschiedliche Branchen sein können.
Sie haben Fragen zum Thema oder benötigen Unterstützung beim Einsatz von KI-Methoden?
Hier gelangen Sie zum Kontaktformular auf unserer Website und können direkt in Verbindung mit unserem AI-& Data-Team treten:
Quellen:
[1] R. M. Andrew, "Global CO2 emissions from cement production," Earth System Science Data, p. 195–217, 26 January 2018.
[2] https://github.com/BAMresearch/WEBSLAMD
[3] https://slamd-demo.herokuapp.com/
[4] Christoph Völker, Benjami Moreno Torres, Ghezal Ahmad Zia, Rafia Firdous, Tehseen Rug, Felix Böhmer, Dietmar Stephan, Sabine Kruschwitz. "Searching for the needle in the haystack - a case study on how machine learning could help to find ideal sustainable building materials." Proceedings of RILEM Spring Convention-CMSS23, Rabat, Morocco, 2023.
[5] Christoph Völker, Benjami Moreno Torres, Tehseen Rug, Rafia Firdous, Ghezal Ahmad Jan Zia, Stefan Lüders, Horacio Lisdero Scaffino, Michael Höpler, Felix Böhmer, Matthias Pfaff, Dietmar Stephan, Sabine Kruschwitz. "Green building materials: a new frontier in data-driven sustainable concrete design." Journal of Cleaner Production, pre-print submitted, 2023. Available on ResearchGate.net: DOI: 10.13140/RG.2.2.29079.85925.
[6] B. Rohr, H. S. Stein, D. Guevarra, Y. Wang, J. A. Haber, M. Aykol, S. K. Suram and J. M. Gregoire, "Benchmarking the acceleration of materials discovery by sequential learning," Chem. Sci., vol. 11, no. 10, pp. 696-2706; doi 10.1039/C9SC05999G, 2020.
Weitere Artikel










- Juni 2026
- April 2026
- Februar 2026
- Januar 2026
- Dezember 2025
- November 2025
- Oktober 2025
- August 2025
- Juli 2025
- Juni 2025
- Mai 2025
- April 2025
- März 2025
- Februar 2025
- Januar 2025
- Oktober 2024
- September 2024
- August 2024
- Juli 2024
- Juni 2024
- Mai 2024
- April 2024
- März 2024
- Februar 2024
- Januar 2024
- Dezember 2023
- November 2023
- September 2023
- August 2023
- Juli 2023
- Juni 2023
- Mai 2023
- April 2023
- Februar 2023
- Dezember 2022
- November 2022
- Mai 2022
- April 2022
- März 2022
- Januar 2022
- Dezember 2021
- November 2021
- Oktober 2021
- August 2021
- Juli 2021
- Juni 2021
- Mai 2021
- April 2021
- Dezember 2020
- Oktober 2020
- September 2020
iteratec
iteratec ist der Partner für alle, die zu den Gewinner:innen der digitalen Transformation gehören wollen. Mit individuellen, überlegenen Lösungen eröffnen wir unseren Kunden technologische wie unternehmerische Potenziale. Denn: Wenn Scheitern keine Option ist, sind wir der Partner, der den Unterschied macht. So haben wir seit 1996 mehr als 1.000 Projekte zum Erfolg geführt und eine Kundenzufriedenheit von 97%.