
Die Weltgesundheitsorganisation schätzt, dass alleine im Jahr 2016 4.2 Millionen Menschen aufgrund von Feinstaubverschmutzungen vorzeitig gestorben sind. Laut dem Umweltbundesamt sind in Deutschland "[...] im Zeitraum 2007-2015 im Mittel jährlich etwa 44.900 vorzeitige Todesfälle durch Feinstaub verursacht" worden.
Feinstaub kann bis in die Nasenhöhle, Bronchien und Lungenbläschen inhaliert werden und von dort aus "Schleimhautreizungen und lokale Entzündungen in der Luftröhre und den Bronchien oder den Lungenalveolen bis zu verstärkter Plaquebildung in den Blutgefäßen, einer erhöhten Thromboseneigung oder Veränderung der Regulierungsfunktion des [...] Nervensystems" verursachen.
Nicht nur die gesundheitlichen Folgen sind gravierend. Einem Bericht der OECD und der WHO zufolge werden die volkswirtschaftlichen Schäden durch Feinstaubverschmutzung in Deutschland im Jahr 2010 auf 145 Mrd. US-Dollar geschätzt.
Somit wird deutlich, dass die Feinstaubverschmutzung der Luft von enormer gesellschaftlicher Relevanz ist. Im Folgenden beschreiben wir das Studentenprojekt Saubere Luft, das zukünftige Feinstaubwerte mit Machine Learning prognostiziert, um so vor erhöhter Feinstaubgefahr mithilfe einer Webapplikation zu warnen.

- Was genau ist eigentlich Feinstaub?
- Unser Studentenprojekt: Saubere Luft
- Phase 1: Problemklassifikation, explorative Datenanalyse und Machine Learning
- Phase 2: Entwicklung der Web-App
- Fazit des Projektes
Was genau ist eigentlich Feinstaub?
Feinstaub, englisch Particulate Matter (PM), besteht aus für den Menschen unsichtbaren Staubteilchen, die z. B. durch Nutzung von PKWs und Luftverkehr, Kraft- und Fernheizwerken, Öfen und Heizungen in Wohnhäusern in die Luft gelangen. Diese Staubteilchen werden durch ihre Korngröße unterschieden: PM10-Feinstaub bezeichnet alle Staubteilchen, die einen Durchmesser von maximal 10 µm haben. Bei PM2.5-Feinstaub hingegen handelt es sich um die noch kleineren und gefährlicheren Partikel, die einen Durchmesser von maximal 2.5 µm haben. Zum Schutz der Gesundheit wird seit 2005 europaweit ein PM10-Grenzwert von 50 µg/m³ verwendet. Dieser darf nicht häufiger als 35 mal im Jahr überschritten werden. Der Grenzwert des Jahresmittels liegt bei 25 µg/m³. Zur Einhaltung dieser Richtlinien wurden in Deutschland Luftreinhalte- und Aktionspläne etabliert. Zur Einhaltung dieser ist es wichtig, die Luftqualität lückenlos zu überwachen und Gebiete zu identifizieren, in denen häufig Überschreitungen auftreten.
Unser Studentenprojekt: Saubere Luft
In Bezug auf die Prävention von erhöhten Feinstaubwerten existieren aktuell Schwierigkeiten. Zum einen gibt es in vielen deutschen Städten nur wenige Sensoren. Kleine Orte verfügen teilweise über gar keine Sensoren, sodass die Feinstaubsituation nicht flächendeckend überwacht werden kann. Auch kann kaum proaktiv reagiert werden, da eine Überschreitung meistens erst im Nachhinein festgestellt wird. Daher haben wir uns zum Ziel gesetzt:
- Preiswerte Sensoren bzw. Messboxen entwickeln, die in größerer Stückzahl an Gemeinden, Unternehmen und an die Bürger gebracht werden können.
- Ein Machine-Learning-Modell trainieren, um zukünftige Überschreitungen des Feinstaubgrenzwertes frühzeitig zu erkennen.
In einem separaten Studentenprojekt ist bezüglich Punkt 1 ein Prototyp entstanden. Die Arbeit an der Messbox verdient ihren eigenen Blog-Artikel und wird hier nicht weiter betrachtet. Da der Messbox-Prototyp aktuell keine Daten aufzeichnet, wurde die App zur Vorhersage der Feinstaubwerte mit öffentlichen Sensordaten in zwei Phasen entwickelt:
- Problemklassifikation, explorative Datenanalyse und Machine Learning
- Entwicklung der eigentlichen Web-App
Problemklassifikation
Als Trainingsdaten für die verschiedenen Machine-Learning-Algorithmen möchten wir Wetter- und Feinstaubdaten verwenden. Die Feinstaubwerte sind die Zielvariable. Daher handelt es sich um eine klassische Supervised-Learning-Problemstellung, bei der die Wetterdaten unsere Descriptive Features und die Feinstaubwerte die Target Features sind. Zunächst mussten wir entscheiden, was genau wir überhaupt vorhersagen möchten:
- Einen genauen Feinstaubwert? Dann handelt es sich um ein Regressionsproblem
- Nur eine Grenzwertüberschreitung? Dann handelt es sich um ein Klassifikationsproblem
Für die Mehrheit der Bevölkerung ist ein genauer Feinstaubwert irrelevant. Meist sind die Menschen nur daran interessiert, ob aktuelle oder nah in der Zukunft liegende Feinstaubwerte gesundheitsgefährdend sind. Daher haben wir entschieden, lediglich vorherzusagen, ob der europäische PM10-Grenzwert von 50 µg/m³ überschritten wird oder nicht. Daraus resultieren zwei Klassen, die vorhergesagt werden können:
- Feinstaubgrenzwert < 50 µg/m³ (negative classification)
- Feinstaubgrenzwert >= 50 µg/m³ (positive classification)
Somit handelt es sich um ein binäres Klassifikationsproblem.
Explorative Datenanalyse und Preprocessing
Die Daten sind essenziell wichtig für den Erfolg eines Machine-Learning-Projektes. So besagt das Garbage-in-, Garbage-out-Konzept, dass qualitativ schlechte Trainingsdaten auch keine sinnvolle Prognose liefern können. Nachfolgend wird beschrieben, wie wir, angefangen mit der Beschaffung von Daten, zu einem Machine-Learning-Modell gelangt sind.
Die explorative Datenanalyse lässt sich dabei als Zyklus beschreiben, in dem sowohl Datenbeschaffung und Preprocessingschritte wie Datenformatierung und -bereinigung, als auch das Training des Machine-Learning-Algorithmus und eine Ergebnisanalyse betrieben werden. Somit wurden die einzelnen Schritte von uns teilweise mehrfach ausgeführt.

Datenbeschaffung
Zuerst steht die Frage im Vordergrund, welche Daten für das Projekt verwendet werden können. Hierzu haben wir uns an einem ähnlichen Projekt aus der Mongolei orientiert. So benötigen wir zum einen historische Wetter- und Feinstaubdaten, um das Machine-Learning-Modell zu trainieren. Diese sollten möglichst lückenlos sein und so weit wie möglich in die Vergangenheit zurückreichen. Zusätzlich benötigen wir selbstverständlich auch aktuelle Wetter- und Feinstaubdaten, die wir als Input für die nächste Prognose verwenden können.
In Deutschland ist auf Bundesebene das Umweltbundesamt (UBA) der erste Ansprechpartner, um Daten zur Luftqualität zu erhalten.
Dazu haben wir uns den Luftqualitätsindex des Umweltbundesamtes angesehen. Das UBA veröffentlicht zu den Messstation keine Wetterdaten. Diese könnte man aber aus anderen Quellen beziehen. Ein größeres Problem findet sich bei den veröffentlichten Feinstaubwerten. Leider werden hier anstatt der stündlichen Mittelwerte die historisch gleitenden 24-Stunden-Feinstaubwerte veröffentlicht.
Der gleitende 24-Stundenwert bezeichnet den Durchschnitt des aktuellen Feinstaubwertes und der vergangenen 23 Stunden. Zur Berechnung wird also das 24-Stunden-Fenster jeweils um eine Stunde verschoben. Somit haben bereits vergangene Messungen einen erheblichen Einfluss auf den aktuellen Wert.
Ein einfaches Beispiel zeigt, warum es unabdingbar ist, dass wir den tatsächlichen Stundenmittelwert verwenden und nicht den gleitenden 24-Studenten-Mittelwert:
Angenommen die vergangenen 23 Stunden lag der stündliche PM10-Wert bei 20 µg/m³, der aktuelle Messwert liegt bei 100 µg/m³. Dann liegt der aktuelle gleitende 24-Stunden-Mittelwert bei (23 * 20) + 100 = 23.3 [µg/m³]. Da 23.3 µg/m³ deutlich unter der Grenze von 50 µg/m³ liegt, nimmt man fälschlicherweise an, dass man bedenkenlos an die frische Luft gehen könne. In Wahrheit liegt der aktuelle PM10-Wert jedoch bei dem doppelten des europäischen Grenzwertes, der als gesundheitsgefährdend gilt.
So wird deutlich, dass unbedingt der stündliche Mittelwert benötigt wird. Daher ist das UBA als Datenquelle ausgeschlossen. Dies ist insofern bedauerlich, da wir so die Möglichkeit auf bundesweit einheitliche Daten verloren haben.
Anschließend haben wir uns auf die Landesebene konzentriert. In NRW veröffentlicht das Landesamt für Natur, Umwelt und Verbraucherschutz Nordrhein-Westfalen (LANUV) stündlich zu verschiedenen Messtandorten Wetter- und Feinstaubdaten. Doch auch hier finden sich in den historischen Aufzeichnungen in Bezug auf den Feinstaub erneut nur gleitende 24-Stunden-Feinstaubwerte. Da wir zunächst jedoch keine andere Datenquelle finden konnten, haben wir uns an die LANUV-Daten gehalten und als erste Messstation den Duisburger Rheinhafen gewählt, da hier im Gegensatz zu vielen anderen Stationen historische Daten vorhanden waren.
Auch haben wir eine Neusser Station verwendet, deren Daten nach einiger Zeit allerdings nicht mehr veröffentlicht wurden. Die Gründe dafür sind uns nicht bekannt. Verdeutlicht wird dadurch jedoch, dass eine Abhängigkeit von Dritten besteht, wenn sich auf externe Datenquellen verlassen wird. Da der jeweils aktuelle PM10-Wert vom LANUV als Stundenmittelwert veröffentlicht wird und nicht als gleitender Wert wie in den historischen Aufzeichnungen, entstand die Idee, die stündlich veröffentlichten Werte monatelang aufzuzeichnen, mit dem Ziel, diese Daten dann zu einem späteren Zeitpunkt als Trainingsdatensatz zu verwenden. Wir haben seit dem 15.08.2019 Daten der Duisburger Station (Rheinhafen) aufgezeichnet, was zu dem jetzigen Zeitpunkt etwa einem halben Jahr an Daten entspricht.
Letztendlich haben wir noch eine weitere Datenquelle gefunden, die weitreichende historische Wetter- und Luftdaten (inkl. Feinstaub) veröffentlicht: Das Stuttgarter Amt für Umweltschutz - Abteilung Stadtklimatologie veröffentlicht Jahreswerte von 1986-2019, Monatswerte von 1987-2020, Tageswerte von 2000-2020 und Halbstundenwerte von 1987-2020 für verschiedene Stationen in Stuttgart. Wir haben uns auf die Halbstundenwerte von 1987-2020 für die Station Stuttgart Schwabenzentrum konzentriert.
Da das ursprüngliche Ziel war, viel mehr Stationen an die App anzubinden, haben wir eine Schnittstelle zu DarkSky geschrieben. Dabei handelt es sich um einen Anbieter von globalen Wetterdaten. So hätten wir im Falle, dass zu manchen Feinstaubmessstationen keine Wetterdaten veröffentlicht werden, auf Dark Sky zurückgreifen können. Fraglich ist allerdings, wie gut Feinstaub- und Wetterdaten aus verschiedenen Quellen miteinander harmonieren. Nach dem Abschluss unseres Projektes wurde DarkSky von Apple übernommen. Die API wird nur noch bis Ende 2021 bereit gestellt, sodass man sich im Falle eines realen Betriebes unserer Anwendung erneut Gedanken über eine neue Datenquelle für Wetterdaten machen müsste.
Der vorangegangene Abschnitt zeigt, dass die Identifikation eines geeigneten Datensatzes enorm zeitaufwändig ist, auch wenn dies in der Theorie oftmals vernachlässigt wird, weil das Machine Learning an sich im Vordergrund steht. Auch wurde deutlich, dass es zum jetzigen Stand keine Datenquelle gibt, von der einheitliche Daten bezogen werden können, die den ganzen deutschen Raum abdecken. Jeder Standort, der über Feinstaubsensoren verfügt, muss mehr oder weniger einzeln an unser System angebunden werden, was zu enormem Aufwand führt. Das LANUV stellt Daten für mehrere Messorte zur Verfügung, die wir daher über die Änderung eines Konfigurationsparameters ohne zusätzlichen Aufwand anbinden können. Jedoch sind die Messdaten oftmals unvollständig. So fehlen bei manchen Stationen die Feinstaubwerte, bei anderen Informationen über den Wind. Deshalb ist klar, dass unser Projekt die Feinstaubvorhersagen nur für die beispielhaft ausgewählten Stationen durchführen kann.
Datenbereinigung
Im nächsten Schritt geht es darum, Lücken in den Daten zu entfernen/befüllen und unplausible Datenpunkte und Ausreißer zu erkennen.
Da im Stuttgarter Datensatz teilweise monatelang Werte für viele Features fehlen, haben wir entschieden, den Zeitraum von 2002-2020 als Trainingsdaten zu verwenden, da hier keine großen Lücken vorhanden sind. Features, die im besagten Zeitraum dennoch sehr große Lücken aufweisen, haben wir entfernt. Der Zeitraum von 18 Jahren entspricht 157680 Stunden und damit ungefähr ebenso vielen Messwerten. Dennoch gibt es weiterhin einige Stunden und Tage im Datensatz, für die nicht alle Messwerte vorhanden sind. Das liegt vermutlich daran, dass die Sensoren teilweise für Wartungsarbeiten ausgeschaltet und ausgebaut werden.
Im Folgenden wird beispielhaft dargestellt, wie häufig Messwerte innerhalb von zwei Tagen fehlen. Ähnliche Verläufe lassen sich im gesamten Datensatz immer wieder finden.
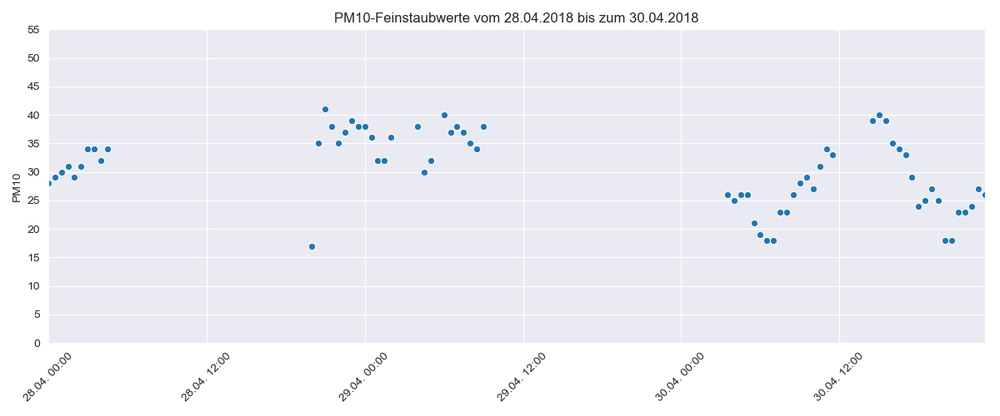
Es gibt verschiedene Strategien, um mit fehlenden Werten umzugehen. Wenn ein Feature sehr oft hintereinander fehlt, tendiert man dazu, die Datenpunkte zu entfernen. Wenn allerdings nur einzelne Werte fehlen, kann man diese gut durch den Mittelwert, das Minimum oder Maximum der umliegenden Werte ersetzen.
Fehlerhafte Messwerte, wie z.B. negative Feinstaubkonzentrationen (das mögliche Minimum ist 0 µg/m³), haben wir direkt zu Beginn aus dem Datensatz entfernt.
Schwieriger ist es, zu erkennen, ob ein hoher Feinstaubwert ein natürlicher Ausreißer oder ein Messfehler ist. Dies wird an zwei Beispielen verdeutlicht.
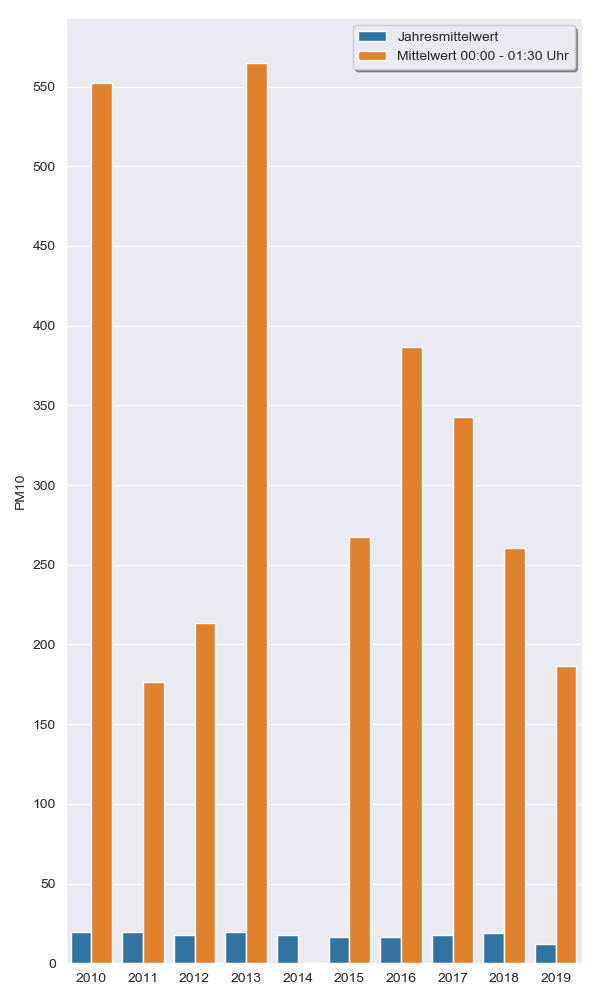
Zunächst betrachten wir die Stuttgarter Daten im Jahr 2018. Der Feinstaubmittelwert liegt 2018 am Stuttgarter Schwabenzentrum bei ungefähr 19.1 µg/m³. Am frühen Morgen am 01.01. waren die halbstündlichen PM10-Messungen wie folgt: 86 µg/m³, 370 µg/m³, 419 µg/m³, 155 µg/m³, 43 µg/m³, 17 µg/m³.
Ist die Messung von 419 µg/m³ ein Messfehler? Nein, denn aufgrund des Silvesterfeuerwerks kommt es in den ersten Frühmorgenstunden des 01.01 zu deutlich erhöhten Feinstaubwerten, wie ein Blick in die vergangenen Jahre zeigt.
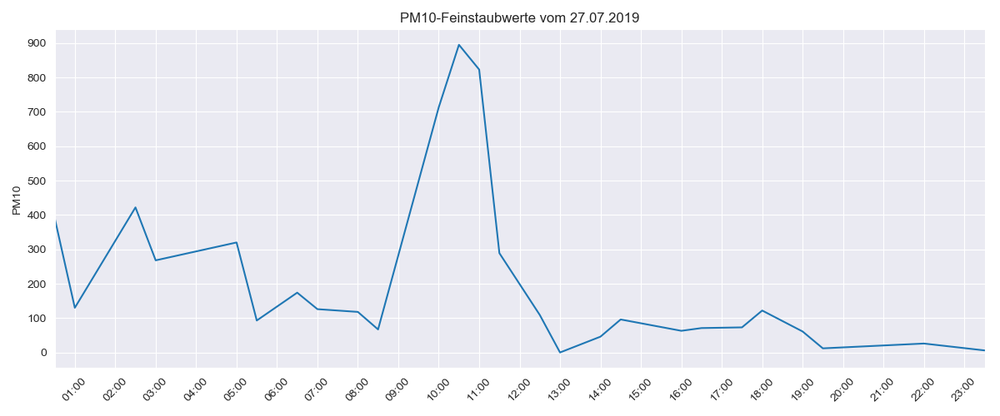
Kommen wir zum zweiten Beispiel: Am 27.07.2019 erreichte die PM10-Messung einen Wert von fast 900 µg/m³. In den Stunden zuvor traten zwar erhöhte Messwerte auf, danach sank der Wert jedoch sehr schnell wieder bis auf 0. Handelt es sich um einen Ausreißer oder einen plausiblen Wert?
Des Weiteren haben Tests gezeigt, dass manche Features gar keine Auswirkung auf den Feinstaubwert haben. Die Hinzunahme von Features wie UVA- und UVB-Strahlung hat nicht zu einer Verbesserung des Modells geführt. Diese Features konnten so also entfernt werden. Auch waren beispielsweise in den Stuttgarter Daten von einigen Features nicht nur die stündlichen Mittelwerte zu finden, sondern auch das stündliche Minimum und Maximum. Wir haben uns auf die Arbeit mit Mittelwerten beschränkt.
Am Ende blieben folgende Werte für einen Messzeitpunkt übrig:
- Datum und Uhrzeit
- Temperatur
- Luftfeuchtigkeit
- Windrichtung und -geschwindigkeit
- PM10-Wert
Im letzten Preprocessingschritt haben wir auf die Descriptive Features eine MinMax-Normalisierung angewandt. Dabei werden die Features jeweils so transformiert, dass die Werte zwischen 0 und 1 (inklusive) liegen.
Dies verhindert, dass manchen Features durch ihre unterschiedliche Skalierung eine höhere Bedeutung beigemessen wird und macht die Features damit vergleichbar. So verbessert sich in den meisten Fällen die Performance der Machine-Learning-Algorithmen. Das Target Feature muss nicht normalisiert werden.
Feature Engineering
In dieser Phase geht es darum, aus den vorhandenen Daten neue Features zu generieren. In unserem Fall haben wir zwei Arten von neuen Features erstellt:
- Zyklische Features
- Geshiftete Features
Zyklische Features
Bei den Zeitstempeln der Messpunkte handelt es sich um ein zyklisches Feature. Minuten, Stunden, Wochentage und Monate folgen einem gewissen Zyklus und tauchen so immer wieder in den Daten auf. Auch muss der Klassifikationsalgorithmus bspw. verstehen, dass Dienstag nach Montag kommt und 23:59 Uhr und 00:00 Uhr nur eine Minute voneinander entfernt liegen. Um diese Informationen verwenden zu können, kann man die Zeiteinheiten auf den Einheitskreis übertragen. Dies wird nun am Beispiel des Wochentages erläutert.
In der Ausgangssituation ist ein Python Pandas Dataframe data vorhanden, welches unter anderem die Spalte date mit dem Datum enthält.
Um zyklische Wochentage zu erstellen, extrahieren wir als erstes den Wochentag aus dem Datum (von Montag = 0 bis hin zu Sonntag = 6):
data['weekday'] = data['date'].dt.weekday
Dann teilen wir den Einheitskreis mit Kreisumfang von 2 pi in 7 Teile, ein Teil pro Wochentag, und erstellen zwei neue Spalten, weekday_sin und weekday_cos:
data['weekday_sin'] = np.sin(data['weekday'] * (2 * np.pi / 7))
data['weekday_cos'] = np.cos(data['weekday'] * (2 * np.pi / 7))
Die Spalte weekday wird nun nicht mehr benötigt und kann entfernt werden. Das Gleiche machen wir für alle temporalen Features (Minuten, Stunden und Monate). Die Jahreszahl ist nicht zyklisch.
Geshiftete Features
Da wir mit time-series-Daten arbeiten, hängen die aktuellen Messwerte natürlich auch von den vorangegangenen ab. Wenn der Feinstaubwert um 13 Uhr extrem hoch ist, wird er um 14 Uhr vermutlich immer noch erhöht sein.
Um damit umgehen zu können und zu wissen, wie schnell sich manche Features verändern, muss der Machine-Learning-Algorithmus wissen, wie die Feinstaubwerte in den vergangenen Stunden waren.
In unserem Projekt gehen wir davon aus, dass in etwa die Feinstaubkonzentration der letzten sechs Stunden einen Einfluss auf den aktuellen Messwert haben könnte. D.h. dass wenn der Feinstaubwert vor sieben Stunden extrem erhöht war, hat dies nur noch einen indirekten Einfluss auf unser Modell (da ja dann der Wert vor sechs Stunden wahrscheinlich auch erhöht war).
Wir erzeugen also für jeden Messwert fünf neue Features, in dem wir die Messwerte der vergangenen Stunden als neue Spalten in das Dataframe shiften.
Dies ist in Abb. 6 dargestellt.
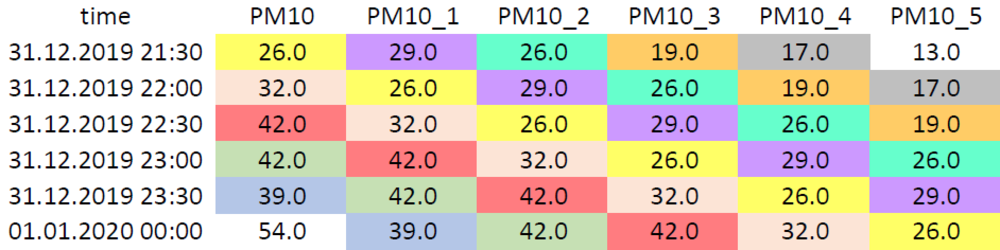
Abb. 6: Geshiftete PM10-Werte im Dataframe
Machine Learning
Insgesamt hat sich unser Projekt mit drei verschiedenen Vorhersageszenarien beschäftigt, die sich vor allem durch das Target Feature, aber auch durch die Descriptive Features, unterscheiden. Die unterschiedlichen Szenarien werden nun kurz skizziert:
- Den ersten Fall haben wir bereits beschrieben. Dabei stehen uns vergangene Wetter- und Feinstaubdaten zur Verfügung. Zusätzlich shiften wir die Werte, um einen zeitlichen Zusammenhang herzustellen. Prognostiziert wird dann, in Abhängigkeit vom Veröffentlichungsintervall der Messstation, der PM10-Wert der nächsten (halben) Stunde. Die zukünftigen Wetterdaten für den Zeitpunkt, für den wir den PM10-Wert vorhersagen, bleiben hier unbekannt.
- Der zweite Fall ähnelt dem ersten. Zusätzlich zu den vergangenen Daten werden jedoch noch zukünftige Wetterdaten (zum Zeitpunkt, für den die Prognose gemacht wird) von DarkSky bezogen. So bleibt die einzige Unbekannte der zukünftige PM10-Wert. Es ist nicht sicher, ob durch verschiedene Quellen ein Bias entsteht.
- Im dritten Fall wird die durchschnittliche PM10-Klasse des Folgetages prognostiziert. Dazu erstellen wir ein neues Target Feature in den Trainingsdaten, welches den PM10-Mittelwert der nächsten 24 Stunden angibt. Das bedeutet, für die Messwerte am 01.01.2020 um 13:00 Uhr speichern wir eine weitere Spalte, die den PM10-Mittelwert vom 01.01.2020 14:00 Uhr bis zum 02.01.2020 um 13:00 Uhr enthält.
Die erste Option beschreibt den Fall, der von unserer Anwendung implementiert wird. Für die anderen beiden Optionen wurden bereits die Grundlagen in der App implementiert, Messungen über die Qualität der Prognosen existieren hierzu aber noch nicht. Zielzustand war es, dass der Nutzer später über das Frontend auswählen kann, welches Target Feature er angezeigt bekommt.
Um die Performance der verschiedenen Algorithmen zu vergleichen, haben wir die Implementierungen aus der Python-Library sklearn verwendet. Die einzelnen Algorithmen haben wir jeweils mit einer 10-fachen Kreuzvalidierung auf dem Stuttgarter Datensatz getestet und dabei Accuracy, Precision und Recall gemessen. Besonders wichtig ist in unserem Anwendungsfall ein hoher Recallwert, da eine gesundheitsgefährdende Grenzwertüberschreitung auf keinen Fall unentdeckt bleiben sollte.
Neben einfachen Verfahren wie dem K-Neighbors-Classifier und einem Decisiontree-Classifier haben wir auch komplexere Algorithmen wie Gradient-Boosting-Classifier und Adaboost-Classifier evaluiert. Die besten Ergebnisse im ersten Vorhersageszenario erzielte letztendlich der XGBoost-Classifier. Der Adaboost-Classifier hat zwar einen leicht besseren Recallscore, wie Abb.7 zeigt. Jedoch ist der F1-Score des XGBoost-Classifiers deutlich besser, weshalb wir uns schlussendlich für diesen Klassifikator in unserer Anwendung entschieden haben.
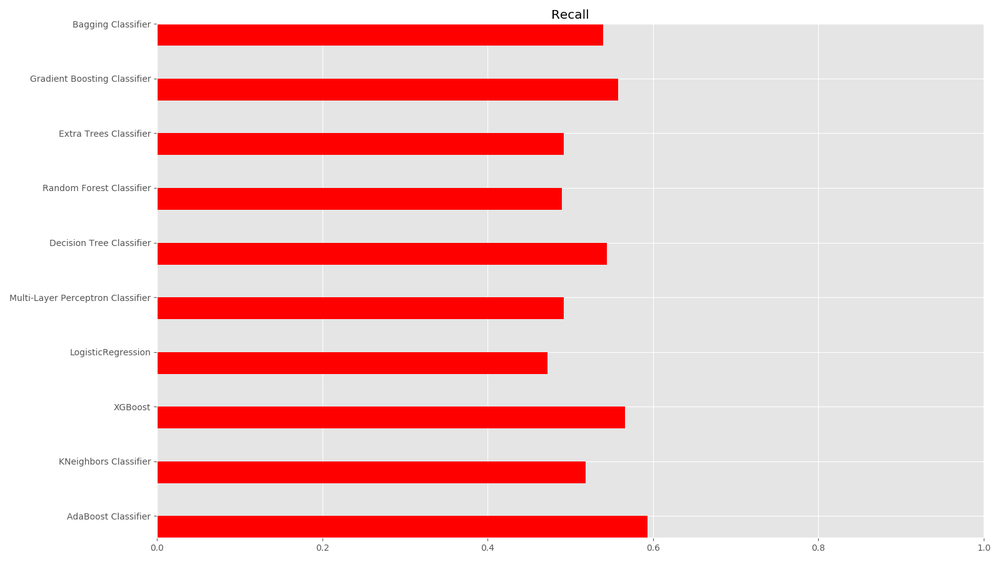
Auch hier wird der Unterschied zwischen stündlichen und gleitenden 24-Stunden-Feinstaubwerten erneut deutlich. Nutzt man die gleitenden Werte der Duisburger Datenquelle, fallen die Scoring-Metriken deutlich besser aus. So erreicht man folgende Werte für die Vorhersage von Grenzwertüberschreitungen (PM10 >= 50 µg/m³):
- Accuracy: 0.986
- Precision: 0.820
- Recall: 0.727
Der sehr gute Accuracy-Score resultiert daraus, dass nur wenige positive Datenpunkte vorhanden sind. So würde das ausschließliche Prophezeien, dass keine Grenzwertüberschreitung vorläge, auch zu sehr einem sehr guten accuracy-Score führen.
Ein weiteres langfristiges Ziel war es, ein kaskadierendes Vorhersage-Modell zu konstruieren. Dabei würden wir den PM10-Wert der nächsten Stunde vorhersagen und diese Vorhersage dann mit in die Vorhersage des PM10-Wertes in zwei Stunden einbeziehen. Dies könnte man für die nächsten 24 Stunden so fortführen. Diese Möglichkeit wurde allerdings noch nicht umgesetzt. Daher können wir über die Performance eines kaskadierenden Modells keine Aussage treffen. Ein weiterer Punkt, der bisher außer Acht gelassen wurde, jedoch enormes Potenzial für eine bessere Performance bietet, ist das Hyperparametertuning. Da später die aufgezeichneten Daten als Trainingsdatensatz verwendet werden sollen, muss hier beachtet werden, dass mit zunehmender Größe des Datensatzes auch die Trainingszeit des Klassifikationsalgorithmus steigt. Da das Parametertuning enorm zeitintensiv ist, muss das Trainieren und Tuning parallel zum eigentlichen Betrieb der App stattfinden, da zu jedem Zeitpunkt ein trainiertes Modell vorhanden sein muss.
Phase 2: Entwicklung der Web-App
Wir haben entschieden, unser Projekt in Python zu entwickeln, da die Programmiersprache mit Bibliotheken wie sklearn, pandas, seaborn und numpy der de facto Standard für Data Science und Machine Learning ist. Die Architektur unseres Projektes bestand aus vier verschiedenen Komponenten:
Als Gerüst für die eigentliche Hauptanwendung haben wir das Webframework Flask gewählt. Wir haben zwei Endpoints für das Frontend zur Verfügung gestellt:
- Einen für die Auswahl der gewünschten Messstation, deren Werte man betrachten möchte.
- Einen für das Templaterendering, um die Vorhersagen und die eigentlichen Messwerte, aber auch das Scoring der Vorhersagen anzuzeigen.
Weiterhin existiert ein Endpoint, über den eine PM10-Vorhersage für die nächste Stunde getriggert werden kann, wenn ein neuer Messwert vorhanden ist.
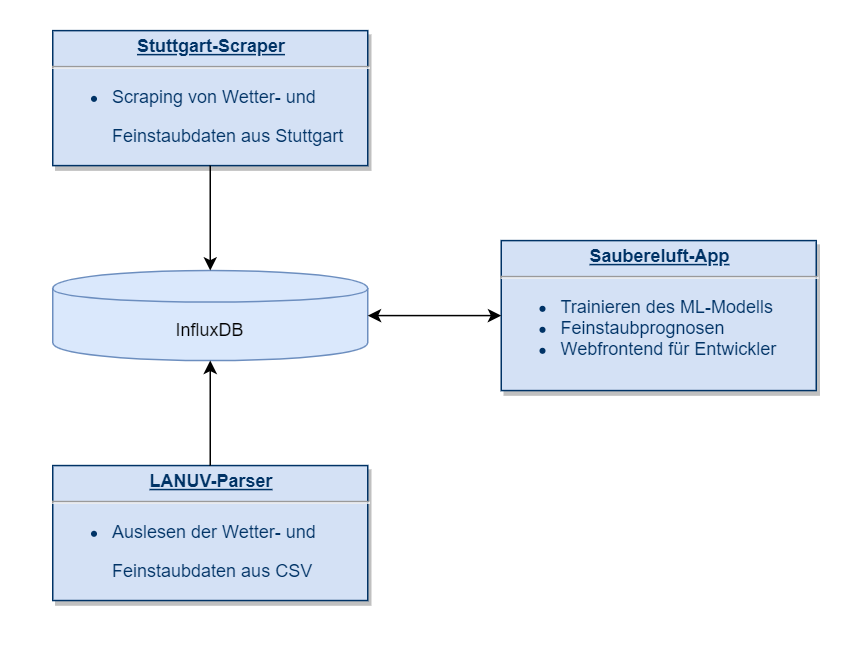
Der gesamte Datenverarbeitungsteil und das Machine Learning wird auch in dieser Komponente erledigt. Die zweite Komponente ist der Datenspeicher. Dazu haben wir die Timeseries-Datenbank InfluxDB verwendet. Sowohl die aktuellen Messwerte als auch die vorhergesagten PM10-Werte haben wir in derselben Datenbank gespeichert, allerdings in verschiedenen Measurements, was in InfluxDB das Pendant zu einer Tabelle in einer relationalen Datenbank darstellt.
Da die Daten aus heterogenen Quellen stammen, wird das Auslesen der aktuellen Messwerte der verschiedenen Stationen jeweils über separate Anwendungen durchgeführt. So wird je nach Messstation entweder eine CSV-Datei heruntergeladen und ausgelesen oder die Messwerte werden direkt von einer Website gescraped und in unsere InfluxDB geschrieben.
Zur Verwaltung der Infrastruktur haben wir OpenShift verwendet. Nachfolgend ist der Datenfluss in unserem Projekt dargestellt. Die zwei Systeme zur Datensammlung schreiben die aktuellen Messwerte in die Datenbank. Die Hauptapplikation verwendet diese Messwerte aus der Datenbank zur Berechnung zukünftiger PM10-Werte.
Die zwei Datensammlungssysteme könnten die Messwerte natürlich auch direkt an die Hauptapplikation geben. Durch unsere Architektur erreichen wir aber eine permanente Persistierung der Daten, sodass wir im Laufe der Zeit unsere eigenen Trainingsdatensätze generieren können.
Fazit des Projektes
Insgesamt gab es die größten Probleme bei der Auswahl geeigneter Datensätze. Schnell wurde festgestellt, dass zum aktuellen Zeitpunkt eine flächendeckende Feinstaubprognose mit öffentlichen Daten in Deutschland nicht möglich ist. Eigene Sensoren aufzustellen würde, auch wenn der Preis für eine einzelne Messbox gering wäre, aufgrund der großen Anzahl an benötigten Sensoren zu einem hohen finanziellen Aufwand führen.
Trotzdem hat unser Projekt gezeigt, dass zumindest für einzelne Stationen das Prognostizieren von zukünftigen Feinstaubwerten durchaus möglich ist. In unserem Fall wurde oftmals das erste Überschreiten des Grenzwertes nicht festgestellt, dafür aber die darauffolgenden. Natürlich besteht bei einem Recall von 0.73 Verbesserungsbedarf. Die Lösung könnte hier unter anderem im Parametertuning liegen.
Auch könnte es durchaus lohnenswert sein, sich mit Datensätzen aus anderen Ländern zu beschäftigen. Da beispielsweise in einigen asiatischen Staaten eine deutlich schlechtere Luftqualität vorherrscht, ist es möglich, dass man aufgrund von mehr positiven Datenpunkten (also Grenzwertüberschreitungen) ein genaueres Modell mit einer besseren Performance erhält.
Noch Fragen?
Was bedeutet Machine Learning und wie kann Ihr Unternehmen vom Einsatz profitieren? Erfahren Sie, wie wir Sie beim Thema Machine Learning unterstützen können:
Weitere Artikel










- Juli 2026
- Juni 2026
- April 2026
- Februar 2026
- Januar 2026
- Dezember 2025
- November 2025
- Oktober 2025
- August 2025
- Juli 2025
- Juni 2025
- Mai 2025
- April 2025
- März 2025
- Februar 2025
- Januar 2025
- Oktober 2024
- September 2024
- August 2024
- Juli 2024
- Juni 2024
- Mai 2024
- April 2024
- März 2024
- Februar 2024
- Januar 2024
- Dezember 2023
- November 2023
- September 2023
- August 2023
- Juli 2023
- Juni 2023
- Mai 2023
- April 2023
- Februar 2023
- Dezember 2022
- November 2022
- Mai 2022
- April 2022
- März 2022
- Januar 2022
- Dezember 2021
- November 2021
- Oktober 2021
- August 2021
- Juli 2021
- Juni 2021
- Mai 2021
- April 2021
- Dezember 2020
- Oktober 2020
- September 2020
iteratec
iteratec ist der Partner für alle, die zu den Gewinner:innen der digitalen Transformation gehören wollen. Mit individuellen, überlegenen Lösungen eröffnen wir unseren Kunden technologische wie unternehmerische Potenziale. Denn: Wenn Scheitern keine Option ist, sind wir der Partner, der den Unterschied macht. So haben wir seit 1996 mehr als 1.000 Projekte zum Erfolg geführt und eine Kundenzufriedenheit von 97%.






.jpg)


