Reinforcement Learning
Die Blog-Serie.
Im ersten Teil der Blog-Serie sind wir auf Unsupervised und Supervised Machine Learning eingegangen. In diesem Artikel beschäftigen wir uns nun mit Reinforcement Learning.
Inhalt
Methoden im Machine Learning
Bevor wir richtig loslegen wiederholen wir die drei grundsätzlichen Methoden im Machine Learning: Unsupervised Learning, Supervised Learning und Reinforcement Learning. Was war das nochmal?
Unsupervised Learning
- Wie bringe ich Ordnung in meine Bauklotzkiste?
- Clustering, Mustererkennung
Supervised Learning
- Wie lerne ich Äpfel von Orangen zu unterscheiden?
- Klassifikation, Regression
Reinforcement Learning
- Wie bringe ich meinem Sohn ein Brettspiel bei?
- Reinforcement Learning

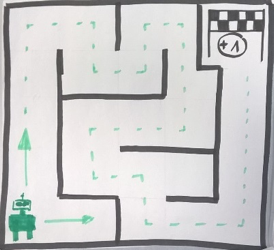
Heute geht es um Reinforcement Learning. Diese Form des Lernens wird angewandt, wenn man durch Interaktion mit der Umgebung beziehungsweise Feedback zu diesen Interaktionen lernen will, um ein Problem zu lösen. Man trainiert einen sogenannten Agenten. Dieser soll durch Interagieren mit seiner Umgebung eine Strategie zum Erreichen seines Ziels erlernen und diese möglichst optimieren. Ein in den Medien viel beachtetes Beispiel für Reinforcement Learning ist der Sieg von AlphaGo gegen den Profi-Spieler Lee Sedol beim Brettspiel Go. Das System AlphaGo wurde mittels Reinforcement Learning im Spiel gegen sich selber trainiert. Bei dem ersten System wurden noch grundlegende Regelwerke hinterlegt. AlphaGo Zero hatte diese nicht und lernte lediglich auf Basis von Reinforcement Learning, indem es gegen sein Vorgängersystem spielte. Nach wenigen Tagen übertrumpfte es seinen Vorgänger.
Ein Unterschied zu den Methoden des Supervised und Unsupervised Learning ist, dass der Algorithmus nicht aus einem existierenden Datensatz Muster lernt, sondern durch das Interagieren mit seiner Umwelt. Das heißt, dass erst durch das Handeln der Agenten die Daten zum Erkennen einer Strategie entstehen, was im Vergleich zu den anderen Algorithmen deutlich zeitaufwändiger und datenintensiver ist. Im Folgenden haben wir ein Beispiel zum selber ausprobieren aufbereitet:
Bastelanleitung Reinforcement Learning
Material:
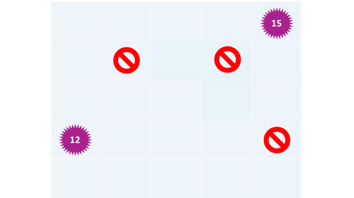
1. Spielplan mit abgedeckten Feldern, die Felder werden im späteren Spiel aufgedeckt. Der Agent soll eine Belohnung finden:

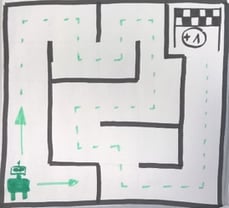
Spielplan mit aufgedeckten Feldern:
2. Tiger-Spielfigur

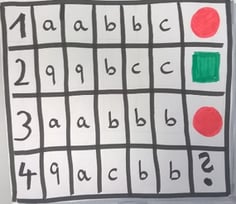
3. TIGER-Merktabelle für Aktionen, Farbstifte oder Klebepunkte (blau, grün, rot, gelb, schwarz)

4. Kugel-Beutel
Beutel mit Kugeln, je ein Beutel mit der Aufschrift T;I;G;E;R, in dem Kugeln der zugeordneten Farbe und Fehlkugeln (Verhältnis 5:1) liegen. Die Zuordnung ist
- T= blau
- I= rot
- G= grün
- E= gelb
- R= schwarz

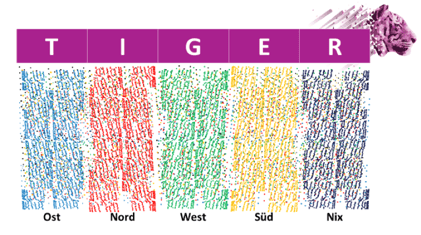

Die Spielvorgaben lauten:
- Es gibt Aktionen T-I-G-E-R, aus denen die Teilnehmer auswählen können.
- Die Anzahl der Digits soll am Ende maximiert sein
- Weitere Informationen gibt es nicht
Spielbeginn:
- Eine Aktion T-I-G-E-R wird durch die Teilnehmer ausgewählt. Solange wir keine Strategie haben, wählen wir zufällige Aktionen.
- Das Spiel "reagiert".
- Jede Aktion kostet ein Digit. Auf dem Digit Board wird ein Digit gestrichen
- Aus dem entsprechenden Kugel-Beutel wird eine Kugel gezogen
- Merkt euch die Aktion und die Farbe der gezogenen Kugel auf der TIGER -Merktabelle
- Der Tiger bewegt sich auf dem Spielbrett entsprechend der gezogenen Kugelfarbe
- Ist ein Ende-Feld (12/15)aufgedeckt, so ist das Spiel beendet. Falls nicht geht es wieder zu 1.
Spielende und Auswertung:
- Die Anzahl der Digits wird gezählt
- Über die TIGER-Merktabelle wird eine Vermutung abgegeben, welche Aktion zu welcher Farbe und damit Zugrichtung führt.
Auswertung für Reinforcement Learning:
Nach einem Durchgang können wir noch keine Strategie ableiten. Hätten wir bspw. 1000 Durchgänge gespielt, so könnte das Ergebnis sein:
- Wir haben nach und nach alle Felder aufgedeckt und kennen alle Spielfeldinhalte (leeres Feld, Belohnung, Hindernisse)
- Wir können die Reaktionen des Spiels aus der TIGER-Merktabelle abschätzen und damit Wahrscheinlichkeiten ableiten
- Wir könnten eine Strategie ableiten

Ableitung einer Gesamtstrategie
Wir geben jedem Feld einen Wert, der darstellt, welche maximale Anzahl Digits wir ausgehend von diesem Feld am Spielende erreichen können.
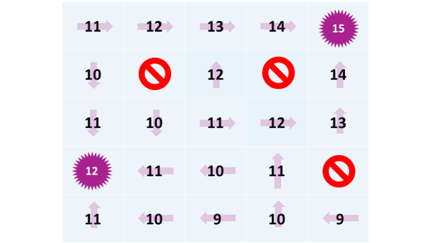
Danach können wir die Gesamtstrategie ableiten: Wähle die Aktion mit der du das Nachbarfeld mit dem höchsten Wert erreichst.
Mit diesem Beispiel haben wir ein Reinforcement-Learning-System simuliert. Wie beim richtigen Machine Learning haben wir als Agent versucht, unsere Belohnungen (Digits) zu maximieren. Zu Beginn wählten wir zufällige Aktionen und beobachteten die Reaktionen des Spiels. Nach häufigem Spielen und wiederholen konnten wir daraus eine Gesamtstrategie ableiten. Ganz und gar analog lässt sich so einfach nachvollziehen, wie diese Systeme prinizipiell funktionieren.
Noch Fragen?
Was bedeutet Machine Learning und wie kann Ihr Unternehmen vom Einsatz profitieren? Erfahren Sie, wie wir Sie beim Thema Machine Learning unterstützen können:
Weitere Artikel










- Juni 2026
- April 2026
- Februar 2026
- Januar 2026
- Dezember 2025
- November 2025
- Oktober 2025
- August 2025
- Juli 2025
- Juni 2025
- Mai 2025
- April 2025
- März 2025
- Februar 2025
- Januar 2025
- Oktober 2024
- September 2024
- August 2024
- Juli 2024
- Juni 2024
- Mai 2024
- April 2024
- März 2024
- Februar 2024
- Januar 2024
- Dezember 2023
- November 2023
- September 2023
- August 2023
- Juli 2023
- Juni 2023
- Mai 2023
- April 2023
- Februar 2023
- Dezember 2022
- November 2022
- Mai 2022
- April 2022
- März 2022
- Januar 2022
- Dezember 2021
- November 2021
- Oktober 2021
- August 2021
- Juli 2021
- Juni 2021
- Mai 2021
- April 2021
- Dezember 2020
- Oktober 2020
- September 2020
iteratec
iteratec ist der Partner für alle, die zu den Gewinner:innen der digitalen Transformation gehören wollen. Mit individuellen, überlegenen Lösungen eröffnen wir unseren Kunden technologische wie unternehmerische Potenziale. Denn: Wenn Scheitern keine Option ist, sind wir der Partner, der den Unterschied macht. So haben wir seit 1996 mehr als 1.000 Projekte zum Erfolg geführt und eine Kundenzufriedenheit von 97%.