Unsupervised und Supervised Learning
Vergangenen Sommer fragte sich Stefan Blum, ob wir durch Machine Learning nicht mehr programmieren dürfen, weil uns der Computer alles abnimmt. „Ganz so weit ist es noch nicht“, lautete sein Fazit. Im heutigen Artikel überlegen wir uns, ob wir Machine Learning eigentlich auch ohne das ganze Technik-Brimborium verstehen und ausprobieren können.
Machine Learning ist im Zusammenhang mit Künstlicher Intelligenz (KI), Big Data und weiteren Buzzwords wie Deep Learning und Neuronalen Netzen konstant in den Medien vertreten. Als Hauptzutaten werden massive Rechenpower (CPUs und/oder GPUs), riesige Datenmengen – eben Big Data – sowie ausgefeilte KI-Programmierbibliotheken (TensorFlow, Keras, Caffe etc.) genannt. Als wir Ende 2016 einen Einsteigerworkshop zum Thema Machine Learning hielten, fragten wir uns in der Vorbereitung, ob das wirklich alles nötig ist, um die zugrundeliegenden Konzepte zu verstehen und in die Thematik einzusteigen. Also haben wir die Herausforderung angenommen und einen Workshop gestaltet, den auch meine Oma oder ein Kind verstehen kann. OHNE Computer, OHNE große Datenmengen und OHNE Machine Learning APIs. Ganz und gar analog: nur mit Zettel, Stift. Machine Learning entmystifiziert, zum Anfassen und Begreifen, so lautete das Motto. Wie das funktioniert hat, wollen wir an dieser Stelle erzählen und zum Nachmachen anregen. Wir geben euch damit ein Werkzeug an die Hand, um das Thema Nicht-Informatikern und Mathematikern verständlich zu erklären.
Die Blog-Serie
In diesem ersten Teil der Blog-Serie gehen wir auf Unsupervised und Supervised Machine Learning ein. Ein zweiter Blog-Eintrag wird sich dann mit Reinforcement Learning beschäftigen.
Inhalt
Wie kann man nochmal lernen?
Bevor wir richtig loslegen, wiederholen wir die drei grundsätzlichen Methoden im Machine Learning: Unsupervised Learning, Supervised Learning und Reinforcement Learning. Was war das nochmal?
Unsupervised Learning
- Wie bringe ich Ordnung in meine Bauklotzkiste?
- Clustering, Mustererkennung
Supervised Learning
- Wie lerne ich Äpfel von Orangen zu unterscheiden?
- Klassifikation, Regression
Reinforcement Learning
- Wie bringe ich meinem Sohn ein Brettspiel bei?
- Reinforcement Learning

Unsupervised Learning
Unsupervised Learning (hier: Clustering) wird in der Regel auf Daten angewandt, bei denen man vorab keine Information über innere Zusammenhänge hat. Man möchte aber gerne mehr über die Daten erfahren – zum Beispiel, ob die Daten nicht doch verschiedenen Kategorien oder Klassen angehören. Um das zu überprüfen, gruppiert man die „nahe beieinander stehenden“ Daten. Wie funktioniert das ohne Verwendung eines Computers?
Zuerst dürfen die Beispieldaten nicht zu kompliziert sein. Um eine Lösung auf dem Papier erreichen zu können, betrachtet man optimalerweise für jedes Beispiel nur zwei Eigenschaften. Wir fanden die Idee spannend, einfach die Teilnehmer des Experiments selbst anhand der beiden Eigenschaften Dienstjahre sowie Entfernung Geburtsort – Arbeitsplatz (Distanz) zu clustern. Dadurch wollten wir mehr über uns und unsere Kollegen erfahren. Man kann aber auch ganz andere Werte oder Eigenschaften verwenden. Seid kreativ! Die Daten könnten also so aussehen:
| Mitarbeiter | Dienstjahre | Distanz [km] |
|---|---|---|
| Angela | 15 | 400 |
| Sigmar | 8 | 200 |
| Frank-Walter | 8 | 300 |
| Andrea | 6 | 500 |
| Christian | 2 | 400 |
| Thomas | 12 | 600 |
| Ursula | 13 | 800 |
Im Folgenden sind zwei Beispiele von Clustering-Algorithmen zum selber ausprobieren aufbereitet:
Bastelanleitung: Single-linkage
Material: Pinnwand/Whiteboard, Kärtchen oder Post-Its, Stift
Vorbereitung: Jeder Teilnehmer des Clustering-Experimentes bekommt ein Kärtchen, das er mit seinem Namen oder Kürzel beschriftet – seinen Avatar.
Info: Beim Single-linkage-Algorithmus berechnet sich der Abstand zweier Cluster aus dem Abstand der zwei am nächsten zueinander liegenden Cluster-Mitglieder. Die Anzahl der Ergebnis-Cluster muss nicht zwingend vorab festgelegt werden. Dies korrespondiert mit dem vollständigen Aufbau einer Baumhierarchie. Diese kann dann auf beliebiger Ebene geschnitten werden, um die gewünschte Anzahl an Clustern zu bekommen. Wir werden aber zwei Cluster als Wunschergebnis festlegen.
Und so geht ihr vor:
- Zeichnet ein Koordinatensystem ans Whiteboard. Tragt auf der X-Achse die Dienstjahre und auf der Y-Achse die Distanz auf.
- Jeder Teilnehmer heftet nun seinen Avatar an der richtigen Stelle ins Koordinatensystem.
- Jeder Avatar ist jetzt per Definition ein Cluster. Im weiteren Verlauf werden Cluster zusammengeführt, um größere Cluster zu bekommen.
- Überlegt euch eine Anzahl an Clustern, die ihr als Ergebnis haben wollt. Das ist euer Abbruchkriterium für den Single-linkage Algorithmus (z. B. 2 Cluster).
- Finde die beiden Cluster mit dem geringsten Abstand zueinander.
- Verbinde die beiden Cluster durch eine Linie. Ein neues, größeres Cluster entsteht.
- Wenn die Anzahl der Cluster > 2 macht weiter mit 5., ansonsten sind wir fertig und haben zwei Ergebniscluster.
Das Ergebnis in unserem Beispiel würde dann mit zwei Zielclustern wie folgt aussehen (die Kantenbeschriftung gibt die Verbindungsreihenfolge an):
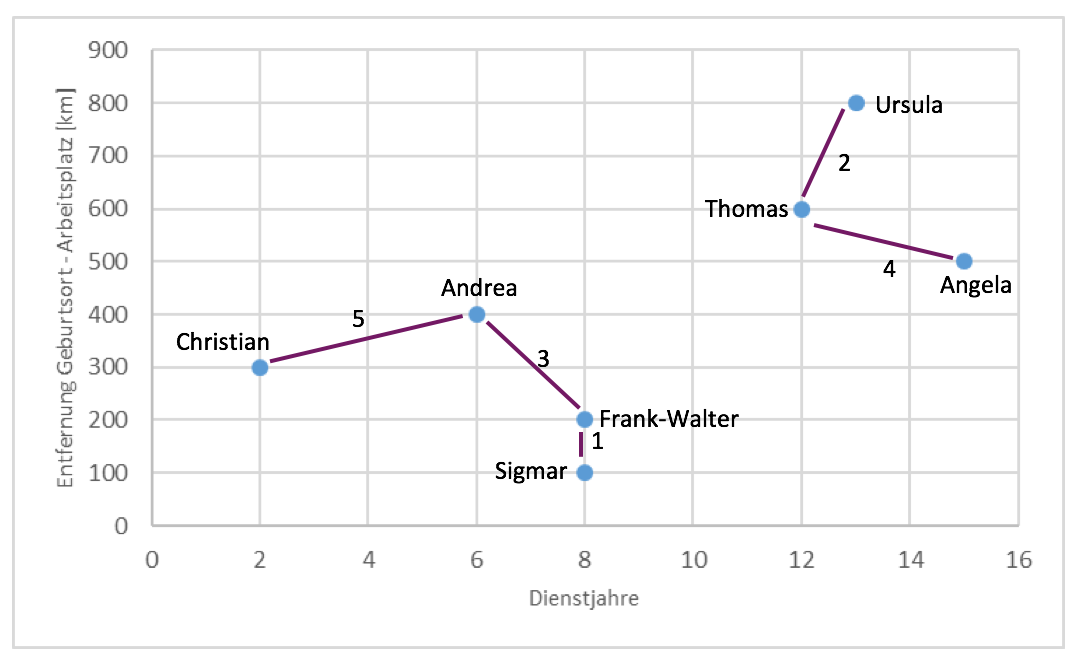
Jetzt kommt noch der kreative Teil: Ihr müsst das Ergebnis interpretieren. Ist es möglich, aus der gefundenen Gruppierung Erkenntnisse abzuleiten? In unserem Beispiel müssten wir uns Fragen, ob bzw. was die altgedienten Mitarbeiter Angela, Ursula und Thomas vom Rest unterscheidet. In diesem konstruierten, niederdimensionalen Beispiel ist eine echte Erkenntnis aber sicher schwer abzuleiten. Man kann feststellen, dass neuere Mitarbeiter nicht mehr so weit vom beruflichen Einsatzort entfernt geboren sind. Nimmt die Bodenständigkeit zu? Gab es Änderungen im Recruiting? Weitergehende Analysen wären hier nötig.
Bastelanleitung: k-Means
Material: Pinnwand/Whiteboard, Kärtchen oder Post-Its in drei Farben, Stift
Vorbereitung: Jeder Teilnehmer des Experimentes bekommt drei Kärtchen in unterschiedlicher Farbe, die er jeweils mit seinem Namen oder Kürzel beschriftet – seinen Avatar. Je ein weiteres Kärtchen jeder Farbe wird mit einem großen X markiert. Dies sind die Cluster-Mittelpunkte.
Info: Beim k-Means-Algorithmus muss die Anzahl der berechneten Cluster vorab festgelegt werden. In unserem Beispiel wählen wir k = 3.
Und so geht ihr vor:
- Zeichne ein Koordinatensystem ans Whiteboard. Trage auf der X-Achse die Dienstjahre und auf der Y-Achse die Distanz auf.
- Initialisierung: Heftet die drei Cluster-Mittelpunkte an beliebige Stellen ins Koordinatensystem.
- Jeder Teilnehmer heftet nun seinen Avatar an der richtigen Stelle ins Koordinatensystem (alle nutzen die selbe Farbe).
- Zuordnung: Jeder prüft nun, welchem Cluster-Mittelpunkt sein Avatar am nächsten ist und passt die Farbe seines Avatars dementsprechend an.
- Anpassung: Jetzt werden die Cluster-Mittelpunkte so verschoben, dass sie als X-Wert und Y-Wert die Mittelwerte aller Cluster-Mitglieder haben.
Iteration: Schritte 4 und 5 werden nun so lange wiederholt, bis sich entweder die Zuordnung oder die Position der Cluster-Mittelpunkte nicht mehr ändert.
Supervised Learning
Supervised Learning (hier: Klassifikation) wird angewandt, wenn man für seine Daten beschreibende Labels hat und für zukünftige noch unbekannte Beispiele diese Labels zuordnen will. Um Klassifikation auf dem Papier auszuprobieren, wollen wir einen Automaten basteln, der Obst sortieren kann. Er klassifiziert das Obst auf Grund der Eigenschaften Farbe und Form. Zuerst betrachten wir wieder unsere Daten, in diesem Fall ein gemischter Obstkorb. Zu jedem dieser Obststücke wissen wir, zu welcher Obstsorte (Labels: Apfel, Birne, …) es gehört und welche Farbe und Form es hat.

Um später überprüfen zu können, wie gut unsere Automaten Obst sortieren, teilen wir unseren Obstkorb zufällig in zwei Teile: Eine Menge, um den Automaten zu trainieren und eine zur späteren Überprüfung.
Im Folgenden gibt es eine Bastelanleitung für zwei Methoden, solch einen Obstsortierautomaten auf dem Papier zu bauen bzw. zu trainieren:

Bastelanleitung: Entscheidungsbaum
Material: Papier, Ausdruck der Trainingsmenge in Farbe, Stift, Schere
Vorbereitung: Druckt die Trainingsdaten in Farbe aus und schneidet jedes der 15 Obststücke einzeln aus.
Teilt euch in drei Gruppen auf (optional).
Info: Wie sieht ein Entscheidungsbaum aus und wie funktioniert er grob:
- Ein Entscheidungsbaum hat Knoten (Entscheidungspunkte) und Blätter (Klassen, Ergebnis)
- Man nimmt die Trainingsdaten und baut einen Entscheidungsbaum so auf, dass alle Trainingsdaten korrekt einsortiert werden
- Bei Aufbau müssen wir:
- Die Eigenschaft wählen, welche die Menge am besten aufteilt
- Einen Knoten für diese Eigenschaft erstellen und die Trainingsdaten aufteilen
- Wiederholt mit jedem Tochterknoten so vorgehen bis diese Knoten nur noch Elemente einer Klasse haben.
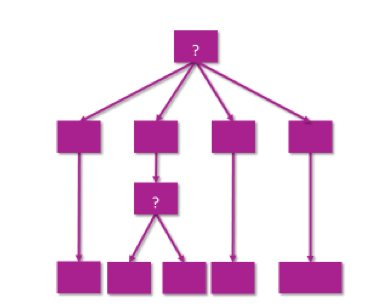

Und so geht ihr vor:
Seht Euch das Beispielergebnis mit nur fünf zufälligen Obststücken und den beispielhaften Entscheidungsbaum an:
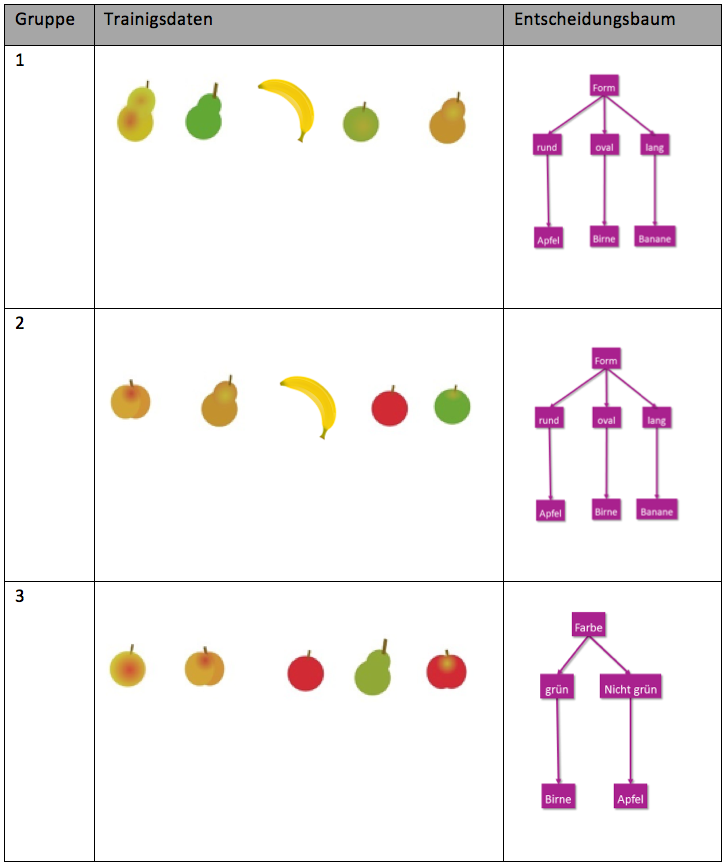
Was passiert, wenn ihr die Trainingsdaten zwischen den Gruppen austauscht?
- Aus manchem Apfel wird eine Birne oder umgekehrt.
Weshalb passiert das?
- Die Trainingsmengen sind zu klein. Dadurch passt sich das Ergebnis zu stark an die Trainingsdaten an. Sobald unerwartete neue Daten dazu kommen, werden sie falsch klassifiziert.
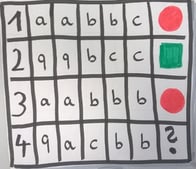
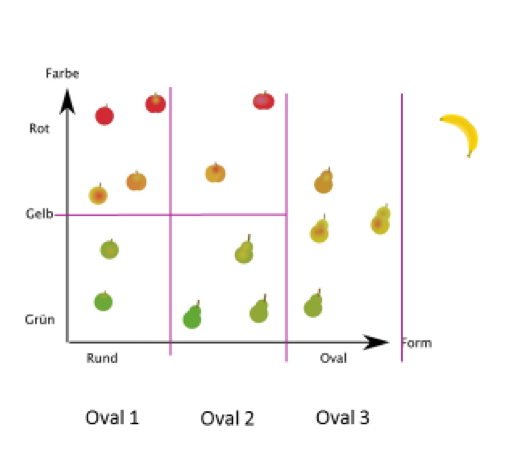
Konstruiert nun einen geeigneten Baum basierend auf allen 15 Trainingsbeispielen. Als Hilfsmittel könnt ihr die Obststücke wie folgt sortieren:
Der Ergebnis-Entscheidungsbaum könnte zum Beispiel so aussehen:
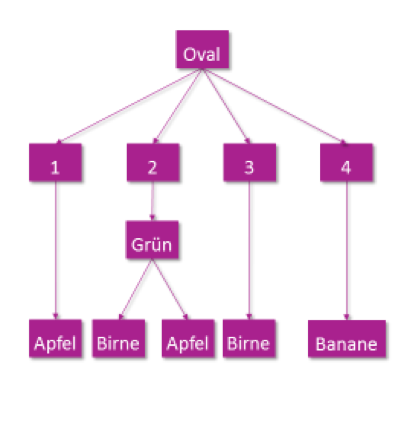 Abschließend prüfen wir mit den beiseite gelegten Testdaten, wie gut der Baum geeignet ist, Obst zu sortieren. Dafür zählen wir einfach, wie viele der verbleibenden 16 Obststücke richtig sortiert werden.
Abschließend prüfen wir mit den beiseite gelegten Testdaten, wie gut der Baum geeignet ist, Obst zu sortieren. Dafür zählen wir einfach, wie viele der verbleibenden 16 Obststücke richtig sortiert werden.
 Außer dem leicht ovalen (oval = 2) grünen Apfel werden alle Obststücke richtig einsortiert. Das entspricht einer Genauigkeit von 93,75%.
Außer dem leicht ovalen (oval = 2) grünen Apfel werden alle Obststücke richtig einsortiert. Das entspricht einer Genauigkeit von 93,75%.
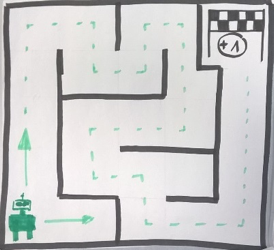
 Doch auch dieser Automat hat natürlich seine Grenzen. Was passiert, wenn eine Obstsorte einsortiert werden soll, die beim Training nicht vorhanden war? Das Bild zeigt ein rundes,
Doch auch dieser Automat hat natürlich seine Grenzen. Was passiert, wenn eine Obstsorte einsortiert werden soll, die beim Training nicht vorhanden war? Das Bild zeigt ein rundes,
oranges Obst => Laut Entscheidungsbaum ist es ein Apfel.
Bastelanleitung Neuronales Netz
Material: ausgedrucktes Aufgabenblatt „Obstsortierer“, Stift und Papier
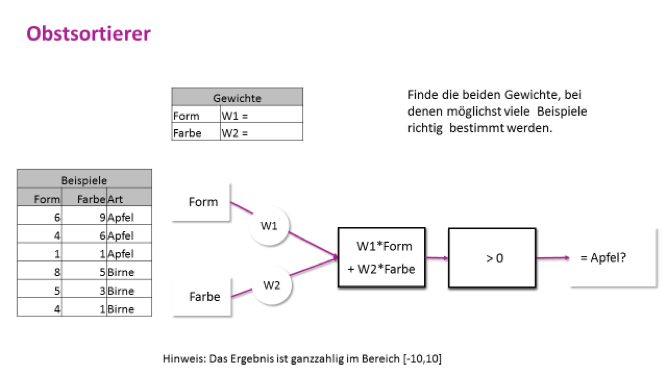
Info: Neuronale Netze können nicht direkt mit kategorischen Daten arbeiten. Deswegen rechnen wir die Form und Farbe des Obstes in Zahlenwerte um. Um mit dem Neuronalen Netz ein Modell zu trainieren, nehmen wir eine kleinere Obstmenge, um nicht zu viel rechnen zu müssen. Außerdem unterscheiden wir vorerst nur zwischen Äpfeln und Birnen und zwar mit einer einfachen Entscheidungsfunktion: Wenn das Ergebnis größer ist als 0, sagen wir das Obst ist ein Apfel, ansonsten ist es eine Birne.
- Initialisiert die Gewichte w1 und w2 mit beliebigen Werten (z. B. 3 und -3)
- Für jedes Trainingsbeispiel:
- Berechnet den Wert der Formel w1*Form + w2*Farbe
- Prüft, ob im Falle eines Apfels ein positives und im Fall einer Birne ein negatives Ergebnis herauskommt
- Falls nicht, passt die Gewichte dementsprechend an
- Sobald die Gewichte so angepasst sind, dass alle Trainingsbeispiele korrekt klassifiziert werden, seid ihr fertig.
Testet die Vorhersage mit den verbleibenden Obstbeispielen. Wie viele werden korrekt einsortiert?
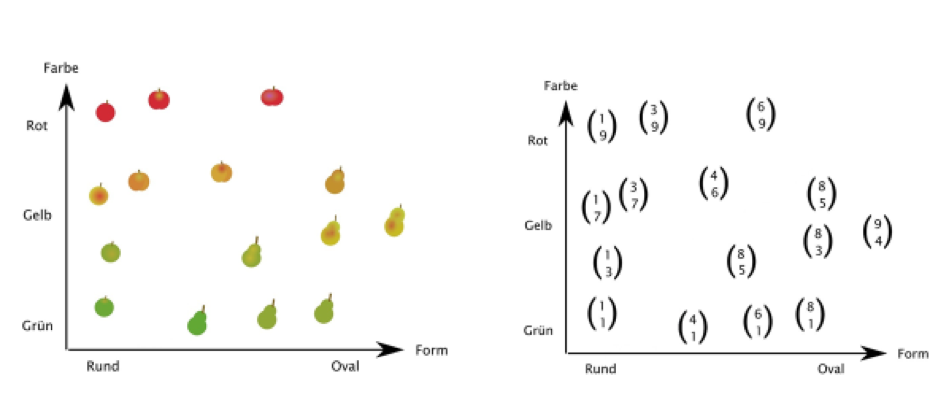
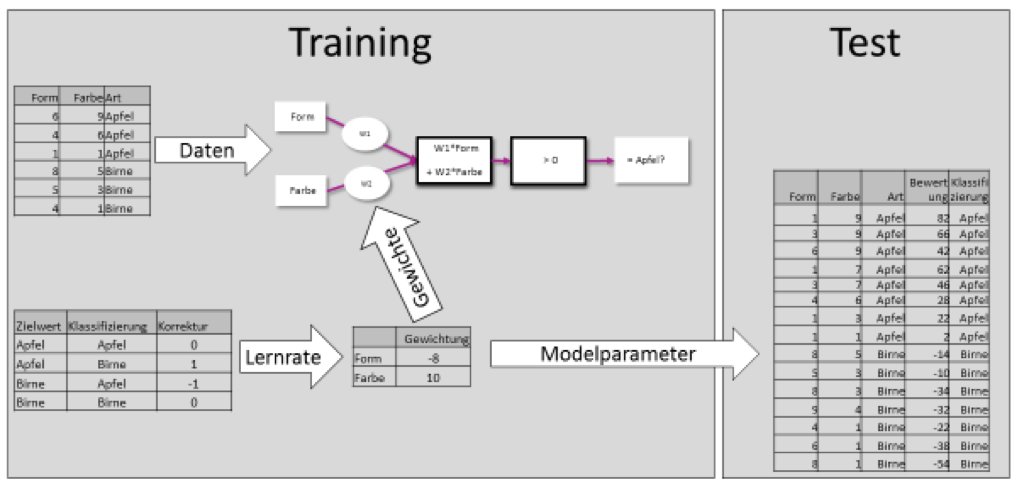
Bei „echten“ neuronalen Netzen wird statt der Schwellwertentscheidung „>0“ häufig eine sigmoide Funktion verwendet. Anhand dieser Funktion kann man das Ausmaß des Vorhersagefehlers bestimmen und die Gewichte systematisch proportional zu diesem Fehler anpassen. Da wir mit Stift und Papier einfach rechnen wollen, bleiben wir bei der Schwellwertfunktion. Ein Ergebnisbeispiel seht ihr hier:
Ausblick
Nachdem wir uns in diesem ersten Teil der Blog-Serie mit Unsupervised und Supervised Machine Learning auseinandergesetzt haben, könnt ihr euch im zweiten Teil der Serie auf ein Reinforcement Learning Tutorial mit Zettel und Stift freuen!
Noch Fragen?
Was bedeutet Machine Learning und wie kann Ihr Unternehmen vom Einsatz profitieren? Erfahren Sie, wie wir Sie beim Thema Machine Learning unterstützen können:
Weitere Artikel










- Juni 2026
- April 2026
- Februar 2026
- Januar 2026
- Dezember 2025
- November 2025
- Oktober 2025
- August 2025
- Juli 2025
- Juni 2025
- Mai 2025
- April 2025
- März 2025
- Februar 2025
- Januar 2025
- Oktober 2024
- September 2024
- August 2024
- Juli 2024
- Juni 2024
- Mai 2024
- April 2024
- März 2024
- Februar 2024
- Januar 2024
- Dezember 2023
- November 2023
- September 2023
- August 2023
- Juli 2023
- Juni 2023
- Mai 2023
- April 2023
- Februar 2023
- Dezember 2022
- November 2022
- Mai 2022
- April 2022
- März 2022
- Januar 2022
- Dezember 2021
- November 2021
- Oktober 2021
- August 2021
- Juli 2021
- Juni 2021
- Mai 2021
- April 2021
- Dezember 2020
- Oktober 2020
- September 2020
iteratec
iteratec ist der Partner für alle, die zu den Gewinner:innen der digitalen Transformation gehören wollen. Mit individuellen, überlegenen Lösungen eröffnen wir unseren Kunden technologische wie unternehmerische Potenziale. Denn: Wenn Scheitern keine Option ist, sind wir der Partner, der den Unterschied macht. So haben wir seit 1996 mehr als 1.000 Projekte zum Erfolg geführt und eine Kundenzufriedenheit von 97%.









