Cloud-native vs. Rechenzentrum
Im ultimativen Infrastrukturvergleich treten zwei unterschiedliche Plattformansätze einer Anwendungsfamilie gegeneinander an. Anhand der Prinzipien der 12-Factor App vergleichen wir eine cloud-native mit einer Rechenzentrum-basierten Infrastruktur:
-
Teil 2: Factor III: Config - Store config in the environment
-
Teil 3: Factor IV: Backing Services - Treat backing services as attached resources
- Teil 4: Factor VII: Port Binding – Export services via port binding
In dieser Runde erfahren Sie, wie durch Stage-unabhängige Konfigurationen mehr Flexibilität erreicht werden kann.
Inhalt
Aussage Factor III: Config
Der erste Faktor, den wir genauer betrachten wollen, lautet Config - Store config in the environment [12F2]. Damit ist gemeint, dass alle Konfigurationen, die von Stage zu Stage variieren, nicht im Code, sondern über Umgebungsvariablen gesetzt werden. Hier ist es wichtig anzumerken, dass es dabei nicht nur um Quellcode geht, sondern insbesondere auch um weitere eingecheckte Dateien, die das Laufzeitverhalten der Applikation näher spezifizieren, wie zum Beispiel application-<PROFIL>.yml Files in Spring Boot Applikationen. Die Trennung von Konfiguration und Code, die durch einen solchen Ansatz erreicht wird, kann technisch auch über den Einsatz eines Konfigurationsservers wie Spring Cloud Config Server erfolgen. In der folgenden Diskussion werden wir uns jedoch auf die direkte Verwendung von Umgebungsvariablen beschränken.
Aus dem Einsatz des Faktors ergeben sich zwei große Vorteile. Eine konsequente Umsetzung des Faktors stellt sicher, dass jeglicher Code, der solche Konfigurationen verwendet, Stage-unabhängig ist. Außerdem wird dadurch eine striktere Entkopplung zwischen Anwendungscode und Konfiguration erreicht. V.a. müssen wir keine Änderungen an unserer Codebasis vornehmen, wenn neue Stages hinzukommen. Dies ist in der Welt der Cloud besonders relevant, da hier schnell und nach Bedarf Umgebungen erzeugt werden können, um zum Beispiel eine dedizierte Stage für Lasttests zu haben. In diesem Zusammenhang macht es Sinn anzumerken, dass damit auch die Umsetzung eines weiteren Faktors (Dev/prod parity- Keep development, staging, and production as similar as possible) begünstigt wird, den wir in einem späteren Teil der Serie detailliert analysieren werden.
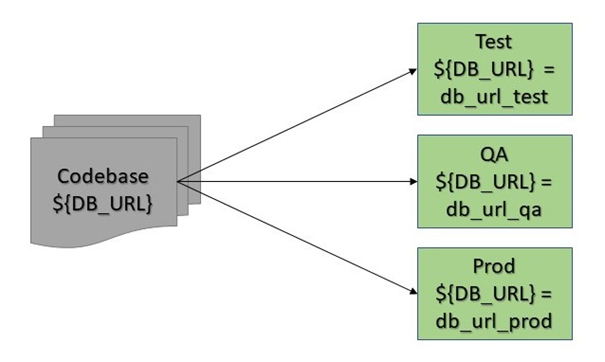
Zusätzlich zur Unabhängigkeit des Codes von der Stage minimieren wir durch den konsequenten Einsatz von Umgebungsvariablen auch die Gefahr, Konstanten in Git einzuchecken, die geheim bleiben sollen. Der Faktor hat also auch einen positiven Impakt auf das Thema Sicherheit.
Typische Konfigurationsparameter sind unter anderem URLs oder Schlüssel, die benötigt werden, um die Kommunikationen zwischen Anwendung und angebundenen Diensten zu ermöglichen. Ein naheliegendes Beispiel ist die JDBC-URL zur Verbindung mit der Datenbank. Aber auch selbst definierte Konfigurationen, die erlauben, Stage-abhängig Funktionalität zu steuern, zum Beispiel zur Verwendung von Feature Toggles, fallen unter die betrachtete Kategorie von Parametern.
Stage-unabhängige Konfigurationen im Rechenzentrum
APP1 verletzt dieses Prinzip bedingt durch die Betriebsumgebung an mehreren Stellen. Um dies besser zu verstehen, lohnt es sich zwei konkrete Verletzungen im Detail zu betrachten. Das erste Beispiel ist sehr generisch, da es die Konfiguration der Datenbank betrifft. Um Spring Boot mit der Datenbank zu verbinden, müssen Werte wie URL, User und Passwort gesetzt werden. Typischerweise, so auch in APP1, gibt es pro Stage eine eigene Datenbank-Instanz. In einer Spring Boot Applikation können wir nun mittels externalized configuration pro Stage eine eigene application-<STAGE_NAME>.yml erzeugen und die entsprechenden Werte zur Laufzeit wie folgt injizieren.
spring:
datasource:
url: <DB_URL_DER_STAGE>
username: <DB_USER_DER_STAGE>
password: <DB_PASSWORT_DER_STAGE>
Dies ist auch der im Rechenzentrum gewünschte und in APP1 umgesetzte Ansatz. Eine solche Verwendung externalisierter Konfiguration hilft uns nun zwar dabei, Konstanten aus den Java Dateien zu entfernen. Dennoch verletzten wir bei diesem Ansatz weiterhin das Prinzip, Code und Konfiguration zu trennen. Da die Konstanten hart in den jeweiligen application-<STAGE_NAME>.yml Dateien einzutragen sind, ist pro Stage eine eigene Datei nötig. Beim Build bzw. Deployment-Prozess auf eine gegebene Stage muss entsprechend darauf geachtet werden, die korrekte Datei zu verwenden. Dies führt zu mehreren potenziellen Fehlerquellen und codeseitig zu einer stärkeren Asymmetrie zwischen verschiedenen Stages. Im Rahmen der 12-Factor App sind die Parameter unabhängig von der Stage als Umgebungsvariablen zu setzen. Es ist nur noch eine application.yml notwendig, die entsprechend der Umgebung, auf der die Anwendung ausgeführt wird, die Variablen auflöst und zur Laufzeit injiziert. Der von Cloud Foundry verwendete Mechanismus wird weiter unten noch genauer erläutert.
Eine zweite Verletzung der Trennung von Code und Konfiguration in APP1 finden wir in der Umsetzung eines Caching-Mechanismus basierend auf Hazelcast. Bei der konkreten Realisierung dieser Lösung gibt es zwei verschiedene Möglichkeiten: embedded-topology oder client-server-topology. Im ersten Fall verwendet die Applikation eine integrierte Hazelcast-Variante. Dies bedeutet zwangsläufig, dass bei einem Deployment auf mehreren Servern entsprechend viele eingebettete Hazelcast-Konfigurationen gepflegt werden müssen, damit der Cache konsistente Daten über alle Server liefert. Im zweiten Fall lebt Hazelcast außerhalb der Anwendung und läuft auf einem eigenen Server. Die Anwendung agiert dann als Client. Die Daten aus dem Hazelcast-Cache kommen also über das Netzwerk in die Anwendung. Die Applikation selbst muss den Zustand der Daten nicht kennen. In APP1 wurde auf die eingebettete Variante gesetzt — einer der Hauptgründe dafür war der zusätzliche Bedarf an Infrastruktur, der im Falle einer client-server-topology vonnöten gewesen wäre. Die Bereitstellung neuer Server seitens des Rechenzentrums ist teuer, hätte mehrere Wochen in Anspruch genommen und der Hazelcast-Server hätte als neue Anwendung durch die Entwickler und den Betrieb dokumentiert und aktuell gehalten werden müssen.
Zur Umsetzung der gewählter embedded-topology Lösung war es notwendig im Code eine Discovery-Strategie festzulegen. Diese wird benötigt, um Hazelcast mitzuteilen, welche Strategie benutzt werden soll, um die Daten der verschiedenen Server synchron zu halten. Aufgrund von Vorgaben durch das Rechenzentrum haben wir die sogenannte TCP/IP-Strategie verwendet. Dazu müssen die IP-Adressen der involvierten Server in die Konfiguration von Hazelcast eingetragen werden. Nun sind diese Parameter offensichtlich abhängig von der Stage. Für eine 12-Factor App würde die Konfiguration in etwa wie folgt innerhalb der application.yml gesetzt:
hazelcast:
network:
tcpip:
ips: ${SERVER_IPS}
und diese dann über @Value im Code verwendet. Die Auflösung der Variable würde dabei durch die Umgebung, auf der der Code ausgeführt wird, erfolgen (mehr Details hierzu werden im Kontext von Cloud Foundry weiter unten erläutert). Dadurch wird erreicht, dass der entsprechende Code stage-unabhänig ist und ein einmal gebautes Artefakt auf jeder Stage deployed werden kann.
Da die Prozesse im Rechenzentrum hingegen eine Stage-abhängige application-<STAGE_NAME>.yml erwarten, in der die IP-Adressen explizit gesetzt werden, sehen wir uns wieder mit dem gleichen Problem konfrontiert, auf das wir schon bei der Konfiguration der Datenbank hingewiesen haben.
Neben der hier beschriebenen Verletzung der 12-Factor App wollen wir zudem darauf hinweisen, dass die gewählte embedded-topology auch gegen einen weiteren Faktor, Backing Services, verstößt. Dies werden wir in einem dedizierten Artikel im Detail erläutern.
Stage-unabhängigen Konfigurationen in der Cloud
Diese Problematik wird durch verschiedene Mechanismen von Cloud Foundry (und Spring Boot) elegant umgangen. Viele relevante Parameter werden durch Cloud Foundry als Umgebungsvariablen direkt bei der Erstellung von bereitgestellt. Diese können über die Kommandozeile wie folgt eingesehen werden:
cf env <APP_NAME>
wobei wir mit <APP_NAME> einen Stage-abhängigen Applikationsnamen, zum Beispiel APP2-test bezeichnen. Bei Bedarf können die gezeigten Werte nun wieder über @Value in den Code eingebunden werden. Falls zusätzliche Variablen benötigt werden, können diese bequem mit dem Befehl
cf set-env <APP_NAME> <ENV_VAR_KEY> <ENV_VAR_VALUE>
gesetzt werden.
Bei der Erzeugung der MySQL-kompatiblen Variante von AWS Aurora, die in APP2 verwendet wird, werden die für Spring benötigten Konfigurationsparameter alle direkt erzeugt. Wir können die Umgebungsvariablen in einer übergreifenden application.yml Datei verwenden und folglich mit nur einer Datei die Verbindungen für beliebige Stages konfigurieren. Tatsächlich geht die Kombination Cloud Foundry und Spring Boot hier noch einen Schritt weiter. Mithilfe der sogenannten auto reconfiguration entfällt sogar die explizite Deklaration der datasource innerhalb der application.yml. Cloud Foundry rekonfiguriert dabei automatisch die notwendigen Bean Deklarationen, um den angebundenen Datenbank-Dienst und die Anwendung zu verknüpfen.
Während wir in APP1 Hazelcast zur Zwischenspeicherung von Daten verwenden, erreichen wir dies in APP2 mit AWS ElasticCache Redis. Bei der Erzeugung des Dienstes mit der Cloud Foundry CLI werden verschiedene Umgebungsvariablen wie zum Beispiel
vcap.services.redis.credentials.host
vcap.services.redis.credentials.port
zur Verfügung gestellt. Diese Variablen werden mithilfe einer Spring Boot Konfiguration in die Anwendung injiziert:
@Value("${vcap.services.redis.credentials.host}")
private String host;
@Value("${vcap.services.redis.credentials.port}")
private String port;
@Bean()
RedissonClient redissonConfiguration() {
Config config = new Config();
serverConfig.addNodeAddress("rediss://" + this.host + ":" + this.port);
return Redisson.create(config);
}
Eine Stage-abhängige Pflege der entsprechenden Parameter in verschiedenen Konfigurationsdateien ist folglich nicht mehr vonnöten. Code und Konfiguration sind somit explizit voneinander getrennt.
Fazit
Wir haben gesehen, wie Cloud Foundry und Spring Boot dabei helfen, Umgebungsvariablen bereitzustellen, die zur Laufzeit pro Stage in unsere Codebasis injiziert werden. Aus Sicht der Cloud ist dieser Ansatz aus vielerlei Gründen wünschenswert. Unter anderem wird dadurch sichergestellt, dass Instanzen und ganze Stages schnell und nach Bedarf erzeugt werden können, ohne dabei Anpassungen im Code vornehmen zu müssen. Daraus ergibt sich auch, dass verschiedenen Umgebungen ein einziges Artefakt zugrundeliegt. Dies führt zu mehr Stabilität und Verringerung von Fehlern, die Stage-spezifisch auftreten. Die Frage, die sich bei dem von uns präsentierten Vergleich aufdrängt, ist, inwieweit eine solche Umsetzung im Rechenzentrum möglich und wünschenswert ist. Dazu sei gesagt, dass technisch im Prinzip nichts gegen eine konsistente Verwendung von Umgebungsvariablen spricht. Problematisch sind die Prozesse, die hier strikt geregelt sind und fordern, dass Werte über Stage-abhängige Konfigurationsdateien gesetzt werden. Auch wenn der Mehrwert, den wir in der Cloud durch die Umsetzung dieses Faktors gewinnen, bedeutender ist, als es im Rechenzentrum der Fall ist, so gäbe es dennoch einige Vorteile, die wir auch dort hätten. Das Management der Umgebungen wäre aufseiten des Codes deutlich übersichtlicher, da nur noch eine application.yml für die nötigen Konfigurationen notwendig wäre. Außerdem lagern wir potenziell geheime Informationen aus dem Code aus. Damit verringern wir die Gefahr, aus Versehen Werte in Git einzuchecken, die dafür nicht bestimmt sind. Ein Nachteil, der sich aus der Umsetzung des Faktors im Rechenzentrum ergibt, sei hier aber auch erwähnt. Die Umgebungsvariablen müssen hier händisch pro Server gepflegt werden (Händisch kann hier sowohl manuell als auch über Skripte gesteuert bedeuten). Zudem wird oft eine Vielzahl von Anwendungen im Rechenzentrum betrieben. Die Pflege von Umgebungsvariablen für alle Anwendungen kann daher schnell unübersichtlich werden. Manueller Aufwand und Betrieb vieler Applikationen kann folglich schnell zu Fehlern führen.
Cloud Foundry stellt im Gegensatz hierzu, wie oben näher beschrieben, viele der relevanten Parameter direkt bei Erstellung der jeweiligen Dienste automatisch bereit. Das Mikro-Management der Infrastruktur durch die Entwickler wird somit minimiert. Die Plattform übernimmt die meisten Aufgaben für uns. Dies führt zu Übersicht und vereinfacht die Arbeit mit Umgebungsvariablen.
Noch Fragen?
Weiter Informationen und Hilfestellungen rund um die Gestaltung und Weiterentwicklung hochperformanter IT-Infrastrukturen und Applikationslandschaften finden Sie unter:
Referenzen:
[12F2]: THE TWELVE-FACTOR-APP - III. Config, siehe: https://12factor.net/config
Weitere Artikel










- Juni 2026
- April 2026
- Februar 2026
- Januar 2026
- Dezember 2025
- November 2025
- Oktober 2025
- August 2025
- Juli 2025
- Juni 2025
- Mai 2025
- April 2025
- März 2025
- Februar 2025
- Januar 2025
- Oktober 2024
- September 2024
- August 2024
- Juli 2024
- Juni 2024
- Mai 2024
- April 2024
- März 2024
- Februar 2024
- Januar 2024
- Dezember 2023
- November 2023
- September 2023
- August 2023
- Juli 2023
- Juni 2023
- Mai 2023
- April 2023
- Februar 2023
- Dezember 2022
- November 2022
- Mai 2022
- April 2022
- März 2022
- Januar 2022
- Dezember 2021
- November 2021
- Oktober 2021
- August 2021
- Juli 2021
- Juni 2021
- Mai 2021
- April 2021
- Dezember 2020
- Oktober 2020
- September 2020
iteratec
iteratec ist der Partner für alle, die zu den Gewinner:innen der digitalen Transformation gehören wollen. Mit individuellen, überlegenen Lösungen eröffnen wir unseren Kunden technologische wie unternehmerische Potenziale. Denn: Wenn Scheitern keine Option ist, sind wir der Partner, der den Unterschied macht. So haben wir seit 1996 mehr als 1.000 Projekte zum Erfolg geführt und eine Kundenzufriedenheit von 97%.