
Cloud-native vs. Rechenzentrum
Im ultimativen Infrastrukturvergleich treten zwei unterschiedliche Plattformansätze einer Anwendungsfamilie gegeneinander an. Anhand der Prinzipien der 12-Factor App vergleichen wir eine cloud-native mit einer Rechenzentrum-basierten Infrastruktur:
-
Teil 2: Factor III: Config - Store config in the environment
-
Teil 3: Factor IV: Backing Services - Treat backing services as attached resources
-
Teil 4: Factor VII: Port Binding – Export services via port binding
- Teil 5: Factor X: Dev/Prod parity – Keep development, staging, and production as similar as possible
In dieser Runde erfahren Sie, wie die Angleichung der Stages eine frühere Fehlererkennung unterstützt.
Inhalt
Aussage des Faktors Dev/Prod Vergleichbarkeit
Dev/Prod Parity [12F5] betont drei Konzepte, die eine cloud-native Anwendung umsetzen soll. Plakativ können wir diese wie folgt auflisten:
- Minimierung der Zeit zwischen Entwicklung und Deployment
- DevOps Mentalität
- Local = Test = QA = Prod
Der erste Aspekt ist selbsterklärend. Code soll nicht erst nach Wochen oder Monaten auf einer Zielumgebung, sondern am besten direkt nach der Entwicklung dort installiert werden. In traditionellen Anwendungen kann dies aus mehreren Gründen oft nicht gewährleistet werden. Oft fehlt die nötige Automatisierung, die es zum Beispiel ermöglicht direkt nach einem git push eine Pipeline zu triggern, die den Code baut, Tests durchführt und im Erfolgsfall die Anwendung deployed. Während dies über entsprechende Maßnahmen durch die Entwickler verbessert werden kann, stellen fest definierte Prozesse in Bezug auf Betrieb und Deployment das wesentliche Problem dar. So sind kontinuierliche Deployments vonseiten des Betriebs häufig nicht vorgesehen. Außerdem führt eine Trennung von Entwicklung und Betrieb dazu, dass Entwickler oft keine Hoheit über die Build- und Deployment Pipelines sowie weitere für den Betrieb relevante Infrastruktur wie Datenbanken haben. Die Pipelines und Zielsysteme können also nicht in einem Maße selbstständig verwaltet werden, welches es erlaubt, kontinuierlich zu deployen und damit die Zeit zwischen Schreiben des Codes und dessen Installation zu minimieren. Dies macht deutlich, dass der erste und zweite Punkt stark miteinander gekoppelt sind. Wird DevOps gelebt, so haben die Entwickler größere Kontrolle über die Zielsysteme und damit auch die Möglichkeit schnell zu deployen. Indirekt hängt damit auch der letzte Aspekt zusammen. Die Gleichungskette "Local = Test = QA = Prod" besagt, dass die verschiedenen Stages, auf denen unser Code ausgeführt wird, möglichst ähnlich sein sollen. Insbesondere sollen die erzeugten Artefakte und verwendeten Dienste wie zum Beispiel Datenbanken oder Caches die gleichen sein. Es wäre somit keine gute Idee, lokal und auf Test auf MySQL zu setzen, in QA und Produktion aber eine PostgreSQL zu verwenden. Die jeweilige Anzahl an Instanzen und deren Hardwareausstattung kann aber natürlich variieren. So macht es zum Beispiel Sinn auf frühen Stages weniger Anwendungsinstanzen zu deployen und die verwendeten Dienste mit weniger Speicher auszustatten. Wichtig bei dem diskutierten Faktor ist also die Homogenität der gewählten Dienste auf den verschiedenen Stages und nicht deren vertikale und horizontale Skalierung. Letztere sollte anhand anderer Kriterien bestimmt werden, wie etwa konkrete Testszenarios mit einer oder mehreren Instanzen, Performance- und Durchsatzmessungen usw.
Neben den Faktoren Config und Port Binding, die wir bereits in vorherigen Beiträgen diskutiert haben, wird die Homogenität der verschiedenen Umgebungen vor allem durch Befolgung dieser Regel sichergestellt. Haben wir die Hoheit über Systeme und Pipelines, so können wir mithilfe von Skripten und Infrastructure as Code automatisiert sicherstellen, dass Umgebungen sich möglichst gleichen. Da auf Automatisierung gesetzt wird, ist zudem sichergestellt, dass der Ansatz skalierbar und wieder verwendbar ist.
Offensichtlich ergeben sich aus der Umsetzung des Faktors diverse Vorteile. Schnelle und regelmäßige Deployments führen zu schnelleren Tests auf Zielumgebungen und optimieren damit Feedback-Zyklen. Eine DevOps Mentalität motiviert das Entwicklungsteam, indem es ihm größere Verantwortung überträgt und somit zu größerer Flexibilität verhilft. Natürlich setzt dies aber die nötigen Skills und den Willen dazu voraus, diese neuen Aufgaben zu übernehmen.
Der Mehrwert obiger Gleichung liegt auf der Hand. Je ähnlicher sich die Stages sind, desto geringer wird die Gefahr, erst spät Bugs zu entdecken. So ist es besonders ärgerlich einen Fehler erst im produktiven Betrieb durch einen Nutzer gemeldet zu bekommen, wenn er durch eine Angleichung der gewählten Technologien schon auf einer Testumgebung hätte entdeckt und behoben werden können.
Stage-Homogenisierung mit Hindernissen im Rechenzentrum
Da APP1 eine Anwendung ist, die nach strikt geregelten Prozessen im Rechenzentrum betrieben wird, ist die Umsetzung obiger Ideen nur sehr bedingt möglich. Um unsere Probleme zu verstehen, lohnt es sich einen Blick auf die entsprechende Serverlandschaft und Prozesse zu werfen. Die Anwendung wird auf jeweils zwei Servern auf einer Test-, QA- und produktiven Umgebung deployed. Releases erfolgen dabei pro Sprint alle drei Wochen. Die Releases werden aber nicht durch das Entwicklungsteam, sondern durch den Betrieb installiert. Zuvor gibt es während des Sprints Deployments von Snapshot-Versionen auf der Test Umgebung. Diese Deployments können zwar bei Bedarf durch die Entwickler getriggert werden. Allerdings können die entsprechenden Jenkins Pipelines nicht vom Team konfiguriert werden. Dies ist Aufgabe des Betriebs. QA stellt in gewisser Weise einen Kompromiss zwischen Test und Produktion dar. Hier können die Entwickler bei Bedarf Snapshot-Versionen deployen. Dies ist aber mit der Einstellung eines Change Prozesses verknüpft. Das Deployment des Releases auf QA einige Tage vor Livegang wird hingegen wieder vom Betrieb ausgeführt.
Die hier beschriebenen Prozesse erschweren die Umsetzung von Dev/Prod parity. Ein kontinuierliches Deployment auf Test ist prinzipiell möglich. Schließlich können wir bei Bedarf den entsprechenden Jenkins Job starten. Da wir aber keinen Einblick in die Konfiguration des Jenkins haben, sind wir bei der Analyse von fehlgeschlagenen Jobs stark eingeschränkt. Ist der Fehler nicht auf unseren Code, sondern auf Konfigurationsänderungen zurückzuführen, können wir ihn nicht selbstständig beheben. Stattdessen ist Kommunikation mit dem Betrieb notwendig. Wurde das Problem dann gefixt, müssen wir den Job erneut starten. Im Optimalfall läuft der Job nun durch. Im Fehlerfall ist ein weiterer Kommunikationszyklus vonnöten. Dies ist zeitintensiv und für die Entwickler undurchsichtig. Kontinuierliches Deployment auf Test ist also möglich, aber nur mit den beschriebenen Einschränkungen.
Auf QA und insbesondere auf Produktion ist die Situation deutlich schwieriger. Auf QA ist die Einstellung eines Change Prozesses für das Deployment notwendig. Die durch den Betrieb bereitgestellten Jobs sind zudem andere als im Falle von Test. Es besteht auch hier die Gefahr, dass Deployments oder vorgelagerte Jobs fehlschlagen und die Ursache für den Entwickler nicht nachvollziehbar sind. Die Kombination aus striktem Prozess mittels Change und Undurchschaubarkeit der individuellen Jobs führt dazu, dass auf QA nicht kontinuierlich, sondern nur wenn es zwingend notwendig ist, deployed wird. Nachdem festgelegt ist, dass nur alle drei Wochen Releases auf Produktion eingespielt werden (Ausnahme sind Hotfix Releases, die allerdings auch einer Genehmigung bedürfen), ist hier eine Minimierung der Zeit zwischen Entwicklung und Deployment ausgeschlossen. Als offensichtliche Konsequenz der beschriebenen Prozesse lässt sich zusammenfassend festhalten, dass DevOps in APP1 nicht möglich ist.
Zum Thema "Lokal = Test = QA = Prod" sei gesagt, dass seitens der Entwickler und des Betriebs das Bemühen besteht, die Umgebungen möglichst ähnlich aufzubauen. So wird zum Beispiel auf allen Stages mit Oracle und Hazelcast gearbeitet. Die tatsächliche Umsetzung stellt sich aber häufig als schwierig heraus. Da die Datenbanken und weitere Infrastruktur-Ressourcen durch den Betrieb verwaltet werden, ist reger Austausch zwischen Entwicklungsteam und Betrieb notwendig, um sicherzustellen, dass die Anwendung sich bei Updates oder Neuinstallationen auf allen Umgebungen gleich verhält. Um die Problematik deutlich zu machen, ist es instruktiv ein Beispiel herauszugreifen. Zur Übermittlung von Daten musste eine neue Schnittstelle basierend auf RVS (Filetransfer mithilfe eines Fileshares auf den Servern) realisiert werden. Codeseitig haben wir dazu die entsprechende Datei erzeugt und dann im Filesystem abgelegt. Von dort wird das File mithilfe von Symlinks in zwei Ordnern innerhalb des Shares abgelegt. Dabei dient einer der Ordner zur Archivierung und Fehleranalyse in APP1. Aus dem zweiten Ordner wird die Datei mittels RVS an den Schnittstellenpartner übertragen. Der Aufbau der Schnittstelle benötigte also neben der eigentlichen Implementierung die Bereitstellung des Fileshares, sowie die Einrichtung von entsprechenden Ordnern und Symlinks, die mit den passenden Rechten ausgestattet sein müssen, damit die Anwendung Dateien dort ablegen kann. Die nachfolgende Abbildung illustriert den Workflow:
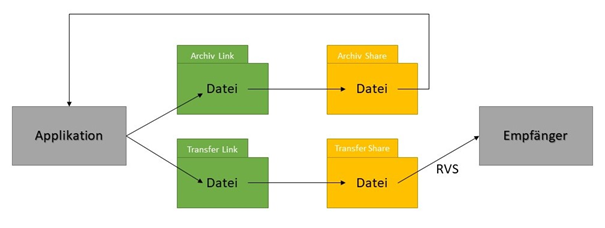 Die Bereitstellung der Shares auf Test, QA und Produktion wurde dabei komplett vom Betrieb übernommen. Die nötigen Konfigurationen der Filesysteme der verschiedenen Server haben aber zu größeren Abstimmungsschwierigkeiten geführt. Während sich das Entwicklungsteam mit den Servern der Test-Umgebung verbinden kann, dort über root Rechte verfügt und somit die Konfigurationen selbst vorgenommen hat, war dies auf QA und Produktion nicht möglich. Die Prozesse sehen hier vor, dass dies durch den Betrieb umgesetzt wird. Dies führte dazu, dass die Umsetzung auf Test schnell durchgeführt und getestet werden konnte. Darauf aufbauend wurde der Betrieb informiert mit der Bitte die Filesysteme der QA- und produktiven Server analog einzurichten. Leider hat dies immer wieder zu Abstimmungsproblemen geführt. So wurden zum Beispiel Rechte nicht korrekt gesetzt, was dazu führte, dass unsere Applikation nicht in die entsprechenden Verzeichnisse schreiben durfte. Da die Entwickler nicht berechtigt sind, sich mit den Servern auf QA und Produktion zu verbinden, konnte die Einrichtung auch nicht auf Level des Filesystems überprüft werden. Stattdessen musste dies über die Funktionalität selbst geschehen. Das heißt aber auch, dass das Feature erst sinnvoll für den Livegang getestet werden konnte, als es schon auf Produktion deployed war.
Die Bereitstellung der Shares auf Test, QA und Produktion wurde dabei komplett vom Betrieb übernommen. Die nötigen Konfigurationen der Filesysteme der verschiedenen Server haben aber zu größeren Abstimmungsschwierigkeiten geführt. Während sich das Entwicklungsteam mit den Servern der Test-Umgebung verbinden kann, dort über root Rechte verfügt und somit die Konfigurationen selbst vorgenommen hat, war dies auf QA und Produktion nicht möglich. Die Prozesse sehen hier vor, dass dies durch den Betrieb umgesetzt wird. Dies führte dazu, dass die Umsetzung auf Test schnell durchgeführt und getestet werden konnte. Darauf aufbauend wurde der Betrieb informiert mit der Bitte die Filesysteme der QA- und produktiven Server analog einzurichten. Leider hat dies immer wieder zu Abstimmungsproblemen geführt. So wurden zum Beispiel Rechte nicht korrekt gesetzt, was dazu führte, dass unsere Applikation nicht in die entsprechenden Verzeichnisse schreiben durfte. Da die Entwickler nicht berechtigt sind, sich mit den Servern auf QA und Produktion zu verbinden, konnte die Einrichtung auch nicht auf Level des Filesystems überprüft werden. Stattdessen musste dies über die Funktionalität selbst geschehen. Das heißt aber auch, dass das Feature erst sinnvoll für den Livegang getestet werden konnte, als es schon auf Produktion deployed war.
Die Diskussion zeigt, dass in APP1 das Bemühen besteht, die Stages möglichst zu homogenisieren. Dies wird durch festgesetzte Strukturen und die Verwendung klassischer Ansätze zur Bereitstellung von Infrastruktur aber deutlich erschwert.
Gelebte DevOps Kultur in der Cloud
Wie sieht die Situation in der Cloud und insbesondere in APP2 aus? Die Entwickler haben hier die Hoheit über die verwendete Infrastruktur und CI/CD Pipelines. Eine DevOps Kultur mit all ihren Vorteilen kann hier gelebt werden. Je nach Bedarf wird die Anwendung auf drei oder vier Stages mit variabler Ausstattung an RAM und Anzahl an Instanzen deployed. Eine Test-Umgebung kann zum Beispiel mit deutlich weniger Ressourcen auskommen, als es in Produktion der Fall ist. Eine unserer Stages dient genau der Umsetzung des CI/CD Konzepts. Sobald Code gepushed wird, baut der verwendete Jenkins das Artefakt und pushed es nach erfolgreichem Build in die Cloud. Dort werden schließlich benötigte Umgebungsvariablen aufgelöst und die Anwendung auf der spezifizierten Anzahl von Instanzen ausgeführt. Somit ist die Zeit zwischen Entwicklung und Deployment auf einer Zielumgebung minimal. Fehler im Build oder beim Betrieb in Cloud Foundry können schnell gefunden und behoben werden.
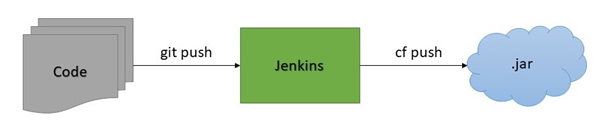
Für die anderen Stages, insbesondere Produktion, wird das Deployment manuell getriggert. Dies ist nötig, da Releases momentan noch in Drei-Wochen-Zyklen bereitgestellt werden. Da wir sicherstellen, dass die Stages in Bezug auf verwendete Dienste gleich aufgebaut sind, ist beim Release aber nicht mit großen Überraschungen diesbezüglich zu rechnen, vorausgesetzt die Anwendung läuft erfolgreich auf der CI/CD Stage. Natürlich kann es zu unerwartetem Verhalten bei erhöhter Last kommen. Dazu empfehlen wir aber entsprechende Lasttests auszuführen und basierend auf den Resultaten Produktion passend zu skalieren.
Die Gleichheit der Stages aus Infrastruktursicht stellen wir folgendermaßen sicher: In einem ersten Schritt überlegen wir uns, welche Dienste aus dem Marketplace von Cloud Foundry verwendet werden sollen. Abhängig von der Stage ist noch abzuwägen, welcher Plan für einen gegebenen Service passend ist, also mit welchen Ressourcen der Dienst ausgestattet werden soll. Zusätzlich müssen wir bei der Auswahl der Dienste auf Aspekte wie Sicherheits- und allgemeine Unternehmensrichtlinien achten. Die Dienste binden wir dann auf jeden der Spaces an unsere Anwendung (mehr Details dazu findet der Leser im Teil Backing Services der Serie). Da wir die entsprechenden Befehle nicht manuell pro Stage ausführen wollen, haben wir Skripte erstellt, die dies für uns übernehmen. Somit verringern wir Fehlerpotenzial durch eine Vielzahl manueller Schritte und erhöhen die Geschwindigkeit und Flexibilität bei Bedarf neue Stages hinzuzufügen, um zum Beispiel einen temporären Space für Lasttests zu haben. Zur Verdeutlichung zeigen wir im folgenden Listing einen kurzen und vereinfachten Auszug aus dem entsprechenden app_create.sh Skript:
login "${SPACE_CONFIG_FILE}" "${SPACE}"
cf push -f "${MANIFEST_FILE}" --no-start
bind_service "${APP_NAME}" "${DATABASE_SERVICE_NAME}"
bind_service "${APP_NAME}" "${REDIS_SERVICE_NAME}"
...
cf start "${APP_NAME}"
Zuerst loggen wir uns auf dem gewünschten Space ein. Intern stellt die login Funktion sicher, dass dazu ein technischer User mit entsprechenden credentials verwendet wird. Danach wird die Anwendung gepushed, aber vorerst nicht gestartet. Wie in unserem Beitrag zum Thema PortBinding genauer beschrieben, wird zur Definition der verwendeten Ressourcen ein sogenanntes Manifest bereitgestellt. Der Pfad zur Datei wird über den MANIFEST_FILE Parameter übergeben.
Die Anwendung wird nicht direkt gestartet, weil zuerst die nötigen Services an die Applikation gebunden werden müssen. Unter der Annahme, dass diese mittels cf create-service zuvor erstellt wurden, kann das Binding in den bind_service Befehlen erfolgen. Dabei handelt es sich um eine Utility-Funktion, die cf bind-service ausführt und sich um Fehlerbehandlung kümmert. Zur Veranschaulichung zeigen wir dies explizit nur für die Datenbank und für Redis. Im tatsächlichen Skript werden alle von APP2 konsumierten Dienste hier an die Applikation gebunden. Einen Überblick über diese Dienste findet der Leser im Beitrag Backing Services der Reihe.
Neben app_create.sh gibt es eine analoges Skipt zur Löschung eines gesamten Spaces. Hier ist darauf zu achten, dass auch alle angebundenen Dienste entfernt werden. Neben diesen Skripten haben wir noch eine Reihe weiterer Skipte erstellt, die uns helfen einen automatisierten Betrieb auf Cloud Foundry sicherzustellen. Dazu gehören unter anderem Skripte für das Management einzelner Dienste oder die Erstellung, Aufbewahrung und den Import von Datenbank-Dumps.
Tatsächlich sind wir bei der Automatisierung sogar noch einen Schritt weiter gegangen. Statt direkt die Skripte auszuführen, haben wir ein eigenes, auf Python basierendes, Command Line Interface geschrieben, über das wir alle Interaktionen mit Cloud Foundry steuern können. Das Aufsetzen eines Spaces erfolgt somit bequem mit dem Befehl
acme space create <SPACE> --deploy-app
wobei acme der Name der CLI ist und <SPACE> durch den gewünschten Namen des Spaces, zum Beispiel Test, zu ersetzen ist. Die intern verwendete Logik bedient sich der Click-Bibliothek von Python, die der Erstellung von CLIs dient. Die CLI selbst ruft intern wiederum die oben genannten Shell Skripte auf.
Für die lokale Entwicklung empfehlen wir zudem auf den Einsatz isolierter Container zu setzen, in denen die entsprechenden Dienste ausgeführt werden. Dies ist vor allem bei Diensten wichtig, die essenziell für unsere Anwendung sind, wie etwa die Datenbank oder In-Memory Datastore. In docker-compose.yml deklarieren wir die Dienste, die von unserer App lokal eingebunden werden sollen:
database:
container_name: APP2-db
image: mysql:5.7
volumes:
- <DATADIR_MYSQL>:/var/lib/mysql
ports:
- 3306:3306
environment:
- MYSQL_ROOT_PASSWORD=<MYSQL_PASSWORD>
redis:
container_name: APP2-redis
image: redis:5.0.7
volumes:
- <DATADIR_REDIS>:/data
ports:
- 6379:6379
Da die Cloud häufig mit zusätzlichen Abstraktionen arbeitet, können wir nicht garantieren, dass die lokale Anwendung die Cloud identisch widerspiegelt, kommen aber möglichst nah dran. Zudem führt das kontinuierliche Deployment auf die CI/CD Stage dazu, dass unser Code schnell dort getestet werden kann, wo er letztlich laufen soll.
Fazit
Dev/Prod parity ist ein Prinzip, dass für eine DevOps Kultur plädiert und dabei hilft Fehler früh zu erkennen und somit Bugs auf Produktion zu verhindern. Wir haben gesehen, dass die Angleichung der verschiedenen Stages sowohl in der Cloud als auch im Rechenzentrum umgesetzt werden kann. In letzterem Fall führt die Trennung zwischen Entwicklung und Betrieb allerdings zu immensem Abstimmungsaufwand. Ebenso ist aufgrund dieser Trennung weder DevOps noch eine Minimierung der Zeit zwischen Entwicklung und Betrieb möglich. Theoretisch ist es hier aber denkbar, eine solche Kultur zu etablieren. Hätten die Entwickler die Hoheit über oder zumindest Einsicht in den Jenkins und die verwendete Infrastruktur, so könnte auch im Rechenzentrum CI/CD betrieben werden, ähnlich wie es in der Cloud der Fall ist. Dazu müssten festgelegte Prozesse aber überdacht und flexibler gestaltet werden.
Noch Fragen?
Weitere Informationen und Hilfestellungen rund um die Gestaltung und Weiterentwicklung hochperformanter IT-Infrastrukturen und Applikationslandschaften finden Sie unter:
Referenzen:
[12F5]: THE TWELVE-FACTOR-APP - X. Dev/prod parity, siehe: https://12factor.net/dev-prod-parity
Weitere Artikel










- Juni 2026
- April 2026
- Februar 2026
- Januar 2026
- Dezember 2025
- November 2025
- Oktober 2025
- August 2025
- Juli 2025
- Juni 2025
- Mai 2025
- April 2025
- März 2025
- Februar 2025
- Januar 2025
- Oktober 2024
- September 2024
- August 2024
- Juli 2024
- Juni 2024
- Mai 2024
- April 2024
- März 2024
- Februar 2024
- Januar 2024
- Dezember 2023
- November 2023
- September 2023
- August 2023
- Juli 2023
- Juni 2023
- Mai 2023
- April 2023
- Februar 2023
- Dezember 2022
- November 2022
- Mai 2022
- April 2022
- März 2022
- Januar 2022
- Dezember 2021
- November 2021
- Oktober 2021
- August 2021
- Juli 2021
- Juni 2021
- Mai 2021
- April 2021
- Dezember 2020
- Oktober 2020
- September 2020
iteratec
iteratec ist der Partner für alle, die zu den Gewinner:innen der digitalen Transformation gehören wollen. Mit individuellen, überlegenen Lösungen eröffnen wir unseren Kunden technologische wie unternehmerische Potenziale. Denn: Wenn Scheitern keine Option ist, sind wir der Partner, der den Unterschied macht. So haben wir seit 1996 mehr als 1.000 Projekte zum Erfolg geführt und eine Kundenzufriedenheit von 97%.








