Formula Student Competition 2018 mit iteratec und municHMotorsport

Diese Blogreihe rund um die Formula Student Competition 2018 mit municHMotorsport besteht aus drei Teilen:
- Teil 1: Was ist Formula Student Driverless und Anforderungsanalysen?
- Teil 2: Umfelderkennung mit Darknet YOLO
- Teil 3: Modellbasierte Trajektorienplanung
In diesem Teil der Blogreihe über das Formula-Student-Projekt geht es um Trajektorienplanung, d.h. konkret: Es soll basierend auf einer Karte der Umgebung des Fahrzeugs (bestehend aus einem Track, der durch Hütchen markiert ist) eine möglichst schnelle Route inklusive der nötigen Fahrzeugparameter (Geschwindigkeit, Lenkwinkel, Beschleunigung etc.) durch den Track berechnet werden.
Inhalt
- Reinforcement Learning
- Exploration vs. Exploitation
- On-/Off-policy
- Model-based / Model-free
- Umsetzung im Fahrzeug
- Fahrzeugzustand
- Aktionen
- Reward-Funktion
- Open Loop Cross Entropy Planning
- Ergebnisse
- Ausblick
- Zum Weiterlesen
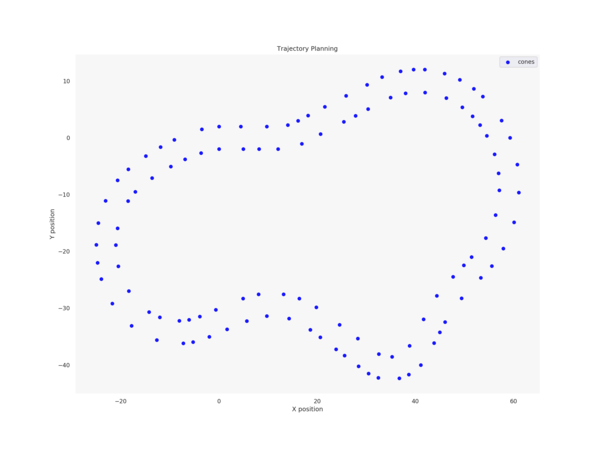
Hierfür wurde in der letzten Saison ein Algorithmus verwendet, der ähnlich eines A*-Ansatzes einen Suchbaum aus verschiedenen Fahrtmöglichkeiten aufbaut und mithilfe einer zu optimierenden Kostenfunktion entscheidet, welcher Pfad abgefahren wird.
Die Nachteile waren hierbei, dass nur diskrete Aktionen (welche genau das in diesem Fall sind, wird später erklärt) möglich waren und dass wir auf jeder Strecke komplett bei null angefangen mussten mit der Planung. Da jedoch der generelle Aufbau einer Stecke bekannt ist, war das Ziel in dieser Saison mittels eines Maschine-Learning-Ansatzes den Zusammenhang zwischen Fahrzeugzuständen und Performance des Fahrzeugs auf der Strecke zu lernen. Um stetige Aktionen zu ermöglichen, haben wir einen Open Loop Cross Entropy Planner implementiert, den ich später noch erläutern werde.
Bevor wir allerdings auf die Details eingehen, sehen wir uns zunächst die Grundlagen des Reinforcement Learning und zugehöriger Begriffe an. Wer darin schon fit ist, kann diesen Teil gerne überspringen und gleich zur Anwendung weiter scrollen.
Wenn man sich überlegt, einen Reinforcement Learning Ansatz anzuwenden, sollte man sich zunächst im Klaren darüber sein, ob das vorliegende Problem folgendem Schema entspricht:
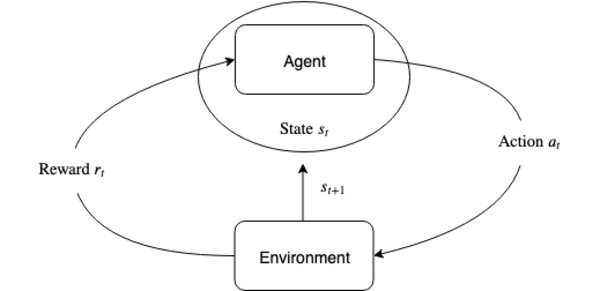
Das bedeutet, wir haben irgendeine Art von Umgebung, auf der ein Agent Aktionen a ausführt, die den Zustand s der Umgebung ändern und entweder zielführend sind - oder nicht (d.h. für die ein positiver oder negativer Reward r gegeben werden sollte). Wichtig ist hierbei, dass der Zustand der Umgebung nur vom vorherigen Zustand abhängen darf (man spricht dann von einem Markov-Prozess).
Ist das der Fall, müssen wir lediglich (Caution!) eine Reward-Funktion definieren, um eine Zeitreihe
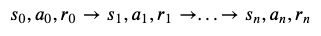
von Start zu End-Zustand zu erhalten. Der End-Zustand ist dann entweder Success oder Failure (wir lassen hier kontinuierliche Tasks außen vor). Eine solche Zeitreihe nennt man Episode. Uns interessiert nun, wie viel Reward der Agent über die komplette Episode generiert hat, den sogenannten Return.
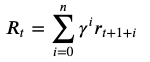
Der Discount Factor Gamma entscheidet dabei, wie weitsichtig der Agent handeln soll (gamma=1 ---> weitsichtig, gamma=0 ---> kurzsichtig).
Haben wir alle diese Voraussetzungen geklärt, suchen wir jetzt nach einer Policy, also nach einer Regel, die uns sagt, in welchem Zustand wir welche Aktion ausführen sollen, um am Ende einen möglichst hohen Return zu bekommen. Das führt uns zur Definition der Value Function, die für einen Zustand s zu einem Zeitpunkt t den erwarteten Return zurück gibt:
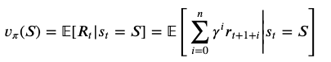
Würden wir diese Funktion bereits kennen, könnten wir einfach in jedem Zustand diejenige Aktion ausführen, die diese Funktion maximiert und würden somit immer den höchstmöglichen Return erzielen. Da wir das aber nicht tun, geht es darum, die Value Function v zu lernen. Das können wir generell, indem wir wiederholt Episoden ablaufen lassen und mit der Erfahrung, die wir dabei machen, die Value Function updaten (je mehr Erfahrung wir sammeln, desto adäquater wird unsere Repräsentation von v werden). Konkret passiert das mithilfe der Bellman Equation.
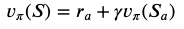
Diese besagt, dass wir in jedem Schritt den Reward, den wir nach Ausführung der Aktion a bekommen, benutzen können, um die aktuelle Value Function ein Stück in die Richtung der eigentlichen Value Function zu verändern, was zur Update-Regel
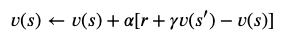
führt, wobei s' der Nachfolgezustand ist (es besteht auch die Möglichkeit mehrere Schritte zu einem Update zusammenzufassen, um eine noch bessere Schätzung der echten Value Function zu bekommen).
Sind der Zustandsraum und der Aktionenraum klein (endlich!) genug, ist es möglich, die Value Function in einer Tabelle zu repräsentieren und es ist sichergestellt, dass obige Methode mit genügend Episoden gegen die eigentliche Value Function konvergiert, d.h. am Ende kennen wir diese exakt.
Da jedoch in den meisten interessanten Fällen der Zustands- und/oder Aktionsraum zu groß sind, muss man auf approximative Methoden zurückgreifen. Eine beliebte Methode ist dabei Deep Learning, bei dem die Value Function durch ein tiefes neuronales Netz repräsentiert wird. Die Trainingssamples stellen dabei exakt dieselben Updates dar, die auch bei der Tabellen-Methode oben verwendet werden (d.h. Zustände s und zugehörige Update Values). Diese fungieren sozusagen als Input-Output Beispiele der gesuchten Funktion.
Auch wenn dabei keine Garantie mehr für die Konvergenz gegeben werden kann, ist dennoch meistens das Erreichen eines lokalen Optimum ausreichend für die meisten Problemstellungen.
Bevor wir nun zum Umsetzen des konkreten Problems kommen, hier noch einige Erklärungen zu Begriffen, die einem im Bereich Reinforcement Learning oft begegnen.
Die meisten Reinforcement-Algorithmen müssen eine Mischung finden aus Erkundung der Umgebung und Ausführung von Aktionen, die bekanntermaßen hohe Rewards bringen. Dies bezeichnet man als das Problem von Exploration vs. Exploitation. Meistens wird dabei ein epsilon-greedy-Ansatz gewählt, bei dem mit einer Wahrscheinlichkeit epsilon eine zufällige Aktion ausgeführt wird (-> Exploration) und mit Wahrscheinlichkeit 1-epsilon die Aktion, die die bisherige Value Function maximiert (-> Exploitation). Dabei sinkt im Verlauf der Ausführung das Epsilon langsam auf einen minimalen Wert.
Eine weitere Unterscheidung ergibt sich daraus, dass die Möglichkeit besteht, für das Updaten und für das Verhalten zwei unterschiedliche Policies zu verwenden. In einem Fall sind beide dieselben (on-policy), im zweiten Fall entscheidet eine Policy darüber, was als nächstes getan wird, während die andere für das Liefern der Updates sorgt (off-policy).
Dies hat hauptsächlich Auswirkungen auf das Konvergenzverhalten der Value Function.
Zuletzt lässt sich zwischen model-based und model-free Reinforcement Learning unterscheiden (Achtung: Es ist hierbei unerheblich, ob ein Modell der physikalischen Umgebung verwendet wird oder nicht). Ersteres verwendet im Verlauf des Trainings ein Modell des zugehörigen Prozesses in dem Sinne, dass sie Annahmen über zukünftige Zustände und Rewards machen, z.B. indem sie zugehörige Wahrscheinlichkeitsverteilungen zugrunde legen. Letztere verwenden ausschließlich Samples, die im Prozess der Ausführung zustande kommen, ohne irgendwelche Voraussagen über die Zukunft zu tätigen. Grob gesagt lässt sich alles, was in den Bereich Planung fällt, als model-based klassifizieren, da hier im Simulationsschritt ein Modell des Prozesses generiert wird.
Nach dieser Einführung beschreibe ich jetzt, wie das ganze konkret im Auto umgesetzt wurde.
Zuerst müssen wir das Problem der Pfadplanung auf das oben beschriebene Modell münzen. Das bedeutet, wir brauchen:
- eine Umgebung, bzw. Zustände s vom Fahrzeug
- Aktionen, die auf dieser Umgebung ausgeführt werden können
- eine Reward-Funktion
Es gibt ein gängiges physikalisches Modell, um Autos zu simulieren: das sogenannte Einspurmodell (der interessierte Leser sei auf den Wikipedia Eintrag verwiesen). Dieses kann das komplette Fahrzeug mit seinen Parametern (Geschwindigkeit, Beschleunigung, Lenkwinkel, Lenkwinkelgeschwindigkeit, Gierwinkel, Gierrate, Schwimmwinkel) repräsentieren. Hinzu kommt eine Repräsentation der Fahrbahn mittels eines feingranularen Grids, mithilfe dessen die Krümmung der Fahrbahn in der aktuellen Position sowie der Abstand zum Rand der Fahrbahn bestimmt werden können.
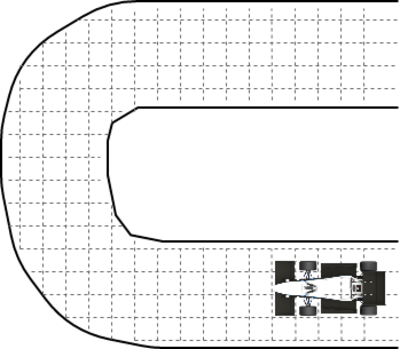
Basierend auf dem oben genannten Einspurmodell können Aktionen bestehend aus Längsbeschleunigung und Lenkwinkelgeschwindigkeit angewandt werden, die zu einer simulierten Fahrt von 0.4 Sekunden führen. Wichtig ist dabei, dass der neue Fahrzeugzustand nur vom letzten Fahrzeugzustand abhängt (siehe Markov-Prozesse oben). Die Berechnungen basieren auf Differentialgleichungen, die diskretisiert werden können.
Ziel des Systems ist natürlich, das Auto möglichst schnell durch den Parkour zu navigieren. Es genügt dabei allerdings nicht, einen Reward am Ende der Strecke z. B. für eine gute Rundenzeit zu vergeben, da dieser Reward zu spät kommen würde für ein effektives Training. Stattdessen werden Reward Lines in die Strecke gelegt, bei deren Überquerung das Fahrzeug jedesmal einen Reward entsprechend seiner erreichten Geschwindigkeit erhält.
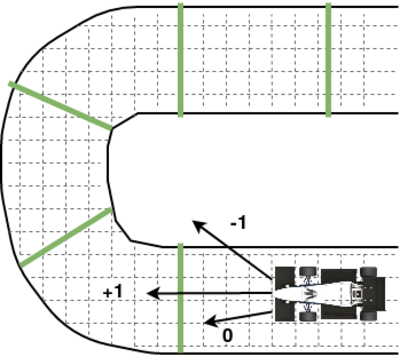
Mit dieser Methode ist es möglich, eine Value Function v(s) zu lernen, die uns sagt, wie gut ein bestimmter Fahrzeugzustand in einem bestimmten Streckenabschnitt hinsichtlich des zu erwartenden (globalen!) Returns ist. Nun benötigen wir allerdings noch einen Planer, der letztendlich entscheidet, welche Aktionen ausgeführt werden.
Hinter diesem komplizierten Namen verbirgt sich eine Methode, die mehrere Reihen von Aktionen bis zu einem gewissen Zeithorizont H simuliert und anschließend die beste (im Sinne der Reward Funktion) dieser Aktionen auswählt und ausführt. Um stetige Aktionen zu ermöglichen, werden diese aus einer Verteilung gesamplet. Die Verteilung wird wiederum nach der Simulationsphase optimiert durch Auswahl der besten x % an Aktionen.
Die Value Function kommt bei dem Ganzen ins Spiel, da wir für den letzten simulierten Zustand zu Zeit H nicht nur einen Reward, sondern mittels der Value Function eine Schätzung für den kompletten restlichen Return ab diesem Zustand erhalten können. Das führt zu der Annahme, dass unter Verwendung der Value Function der Planungshorizont H verringert werden kann.
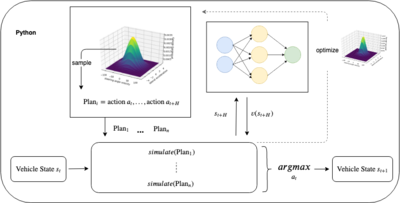
Die Methode simulate implementiert dabei die Funktion.
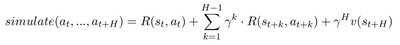
Hier sind einige beispielhafte Tracks aufgeführt, die sehr gute Pfade zeigen. Dabei repräsentieren dunkle Farben langsame und helle Farben hohe Geschwindigkeiten (~20 m/s).
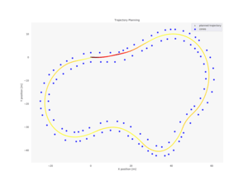
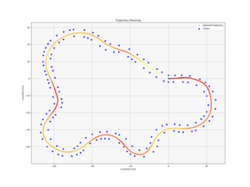
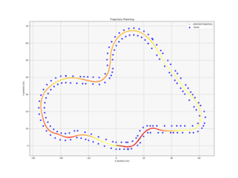
Die Performance für verschiedene Werte des Horizonts H über 1000 Episoden sind hier abgebildet, wobei für H=13 keine Value Function verwendet wurde (dieser Wert ist hoch genug um die - laut den Regeln - längstmögliche Gerade von 80m voraus zu planen):
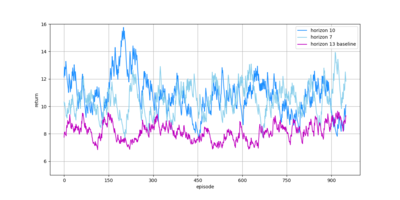
Dabei ergibt sich für die durchschnittliche Geschwindigkeit, die durchschnittliche Anzahl an Schritten sowie den durchschnittlichen Return folgende Tabelle:
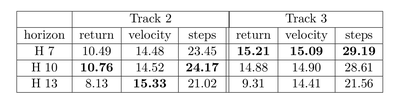
Trotz der punktuell sehr guten Ergebnisse auch mit geringerem Horizont, die den Algorithmus der vorherigen Saison teilweise um fast 10 km/h übertroffen haben, hat sich herausgestellt, dass eine hohe Varianz durch das Samplen aus einer Verteilung nicht zu vermeiden war.
Das führt dazu, dass der Ansatz unter diesen Umständen ausschließlich für eine Planung, die offline stattfindet, anwendbar ist.
Nichtsdestotrotz war es spannend, diesen innovativen Ansatz auszuprobieren und zweifelsfrei bietet das Reinforcement Learning vielversprechende Optimierungsmöglichkeiten.
Wie oben beschrieben, ist ein Problem die hohe Varianz beim Samplen der Aktionen. Man könnte hier eine andere Sampling-Methode verwenden (ein Paper schlägt vor, eine Verteilung mittels eines Monte-Carlo-Tree-Search-Ansatzes zu generieren).
Ein weiterer Punkt ist das Übertragen der Simulation auf die Realität. Hier müsste man z. B. noch Noise in den Prozess aufnehmen, um mit Problemen bei der Messung von Daten umzugehen.
Ein komplett anderer Ansatz, der häufig in der Simulation von Robotern getestet wird, wäre Reinforcement Learning mit Actor-Critic-Architektur. Hier wird nicht geplant, sondern mit einem neuronalen Netz eine Funktion gelernt, die direkt Zuständen Aktionen zuweist (das ist ein Beispiel eines model-free Ansatzes, siehe oben).
Letztendlich ist das Progammieren autonomer Agenten mittels Reinforcement Learning noch ein Feld aktiver Forschung, bei dem das Gewährleisten von Sicherheit gegenüber Benutzern eine Herausforderung darstellt (ein Punkt, der im industriellen Einsatz äußerst wichtig wäre).
Andererseits gibt es momentan noch keine Alternativen, die bei solchen Problemen ähnliche Ergebnisse liefern. Zudem werden wohl noch weitere Verbesserungen beim Einsatz neuronaler Netze erzielt werden.
Hier einige Quellen, die helfen das äußerst weite Feld des Reinforcement Learning besser kennenzulernen:
1. Reinforcement Learning von Sutton und Barto: Das ausführliche Standardwerk zum Thema
2. Tutorial von Arthur Juliani: Exzellenter Blog Post mit Code Beispielen
3. Human Level Control: Paper über das Spielen von Atari Games
4. Continuous Control with Reinforcement Learning: Actor-Critic Architektur für stetige Probleme
Noch Fragen?
Was bedeutet Machine Learning und wie kann Ihr Unternehmen vom Einsatz profitieren? Erfahren Sie, wie wir Sie beim Thema Machine Learning unterstützen können:
![]() Westermeier Adrian - war zwei Jahre lang im Formula-Student-Projekt tätig und hat seine Bachelorarbeit über das Thema Reinforcement Learning geschrieben. Er studierte Informatik im Master an der LMU und arbeitete als Werkstudent im Machine Learning Lab der iteratec. Wir schätzen seinen Beitrag und informieren, dass er nicht mehr bei iteratec tätig ist. .
Westermeier Adrian - war zwei Jahre lang im Formula-Student-Projekt tätig und hat seine Bachelorarbeit über das Thema Reinforcement Learning geschrieben. Er studierte Informatik im Master an der LMU und arbeitete als Werkstudent im Machine Learning Lab der iteratec. Wir schätzen seinen Beitrag und informieren, dass er nicht mehr bei iteratec tätig ist. .
Weitere Artikel










- Juni 2026
- April 2026
- Februar 2026
- Januar 2026
- Dezember 2025
- November 2025
- Oktober 2025
- August 2025
- Juli 2025
- Juni 2025
- Mai 2025
- April 2025
- März 2025
- Februar 2025
- Januar 2025
- Oktober 2024
- September 2024
- August 2024
- Juli 2024
- Juni 2024
- Mai 2024
- April 2024
- März 2024
- Februar 2024
- Januar 2024
- Dezember 2023
- November 2023
- September 2023
- August 2023
- Juli 2023
- Juni 2023
- Mai 2023
- April 2023
- Februar 2023
- Dezember 2022
- November 2022
- Mai 2022
- April 2022
- März 2022
- Januar 2022
- Dezember 2021
- November 2021
- Oktober 2021
- August 2021
- Juli 2021
- Juni 2021
- Mai 2021
- April 2021
- Dezember 2020
- Oktober 2020
- September 2020
iteratec
iteratec ist der Partner für alle, die zu den Gewinner:innen der digitalen Transformation gehören wollen. Mit individuellen, überlegenen Lösungen eröffnen wir unseren Kunden technologische wie unternehmerische Potenziale. Denn: Wenn Scheitern keine Option ist, sind wir der Partner, der den Unterschied macht. So haben wir seit 1996 mehr als 1.000 Projekte zum Erfolg geführt und eine Kundenzufriedenheit von 97%.